LangChain Chinese Getting Started Guide
1.0.0
Para una lectura fácil, se han generado gitbooks: https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
Dirección de GitHub: https://github.com/liaokongvfx/langchain-chinese-getting-start-guide
"Decryto de tecnología Langchain: una guía panorámica para construir grandes aplicaciones modelo" ahora: https://item.jd.com/14598210.html
Transferencia de API del modelo de IA doméstica y extranjera de baja precio: https://api.91ai.me
Debido a que la Biblioteca Langchain se ha actualizado e iterando rápidamente, pero el documento está escrito a principios de abril, y tengo energía personal limitada, por lo que el código en Colab puede estar algo desactualizado. Si hay alguna falla en la operación, primero puede buscar si el documento actual se ha actualizado.
Agregué un ChangeLog y actualicé el nuevo contenido.
Si desea modificar la ruta raíz de solicitud de la API de OpenAI a su propia dirección de poder, puede modificarla configurando la variable de entorno "OpenAI_API_Base".
Código de referencia relacionado: https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#l48
O al inicializar los objetos de modelo relacionados con OpenAI, pase en la variable "OpenAI_API_BASE".
Código de referencia relacionado: https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
Como todos sabemos, la API de OpenAI no puede conectarse a Internet, por lo que definitivamente es imposible usar sus propias funciones para buscar y dar respuestas, resumir documentos PDF y realizar preguntas y respuestas en función de un video de YouTube. Entonces, presentemos una biblioteca de código abierto de terceros muy potente: LangChain .
Dirección del documento: https://python.langchain.com/en/latest/
Esta biblioteca es actualmente muy activa e itera todos los días.
Langchain es un marco para desarrollar aplicaciones alimentadas por modelos de idiomas. Tiene 2 habilidades principales:
Modelo LLM: modelo de lenguaje grande, modelo de lenguaje grande
LLM Llamada
Gestión rápida, admite varias plantillas personalizadas
Tiene una gran cantidad de cargadores de documentos, como correo electrónico, markdown, pdf, youtube ...
Soporte para índices
Cadenas
Creo que todos se confundirán después de leer la introducción anterior. No se preocupe, el concepto anterior en realidad no es muy importante cuando comenzamos a aprender.
Sin embargo, aquí hay varios conceptos que deben ser conocidos.
Como su nombre lo indica, esto es cargar datos de una fuente especificada. Por ejemplo: carpeta de DirectoryLoader , Azure Storage AzureBlobStorageContainerLoader , CSV File CSVLoader , Evernote EverNoteLoader , Google GoogleDriveLoader , cualquier página web UnstructuredHTMLLoader , PDF PyPDFLoader , S3 S3DirectoryLoader / S3FileLoader ,
YouTube YoutubeLoader , etc., acabo de enumerar brevemente algunos de ellos.
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
Después de leer la fuente de datos utilizando el cargador del cargador, la fuente de datos debe convertirse en un objeto de documento antes de que pueda usarse más adelante.
Como su nombre indica, la segmentación de texto se usa para dividir el texto. ¿Por qué necesitas dividir el texto? Porque cada vez que enviamos texto como propt para OpenAI API o usamos la función de incrustación de la API de OpenAI, existen restricciones de caracteres.
Por ejemplo, si enviamos un PDF de 300 páginas a la API de OpenAI y le pedimos que resume, definitivamente informará un error que excede el token máximo. Así que aquí necesitamos usar un divisor de texto para dividir el documento en el que entra nuestro cargador.
Porque la búsqueda de correlación de datos es en realidad una operación vectorial. Por lo tanto, ya sea que usemos la función de incrustación de la API de OpenAI o consultemos directamente a través de la base de datos Vector, necesitamos vectorizar nuestro Document de datos cargados para realizar la búsqueda de operaciones vectoriales. La conversión en un vector también es muy simple.
El funcionario también proporciona muchas bases de datos vectoriales para que lo usemos.
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
Podemos entender la cadena como una tarea. Una cadena es una tarea y, por supuesto, también puede ejecutar múltiples cadenas una por una como una cadena.
Simplemente podemos entender que puede ayudarnos dinámicamente a elegir y la cadena de llamadas o las herramientas existentes.
Para el proceso de ejecución, consulte la siguiente imagen:
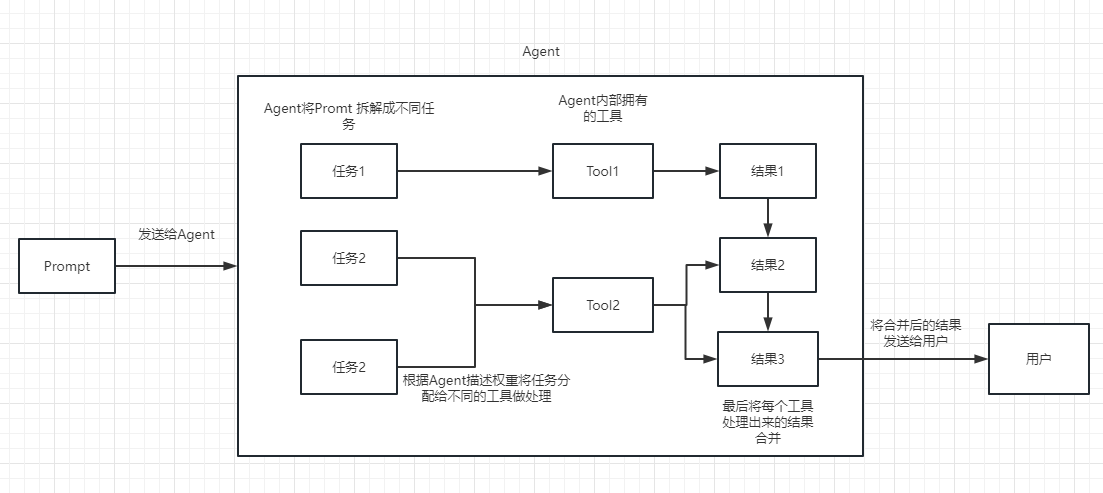
Utilizado para medir la relevancia del texto. Esta es también la clave para la capacidad de la API de OpenAI para construir su propia base de conocimiento.
Su mayor ventaja sobre el ajuste fino es que no necesita entrenar y puede agregar nuevo contenido en tiempo real, en lugar de agregar contenido nuevo una vez, y el costo en todos los aspectos es mucho más bajo que el ajuste.
Para comparaciones y selecciones específicas, consulte este video: https://www.youtube.com/watch?v=9qq6htr7ocw
A través de los conceptos esenciales anteriores, debe tener una cierta comprensión de Langchain, pero aún puede estar un poco confundido.
Todas estas son pequeñas preguntas.
Debido a que nuestra API de OpenAI avanzó, el LLM utilizado en nuestros ejemplos posteriores se basa en AI Open como ejemplo.
Por supuesto, al final de este artículo, todo el código se guardará como un archivo COLAB IPYNB y se proporcionará a todos para que aprendan.
Se recomienda que mire cada ejemplo en orden, porque el siguiente ejemplo usará los puntos de conocimiento en el ejemplo anterior.
Por supuesto, si no entiende algo, no se preocupe.
En el primer caso, utilizaremos Langchain para cargar el modelo Operai y completar un preguntas y respuestas.
Antes de comenzar, primero debemos configurar nuestra clave OpenAI.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'Luego importamos y ejecutamos
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
En este momento, podemos ver el resultado que nos dio.
A continuación, hagamos algo interesante. Hagamos que nuestra API de OpenAI busque en línea y nos devuelvamos las respuestas.
Aquí necesitamos usar Serpapi para implementarlo, que proporciona una interfaz API para la búsqueda de Google.
Primero, necesitamos registrar a un usuario en el sitio web oficial de Serpapi, https://serpapi.com/ y copiarlo para generar la clave API para nosotros.
Luego necesitamos configurarlo en la variable de entorno como la tecla API OpenAI anterior.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'Entonces, comience a escribir mi código
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )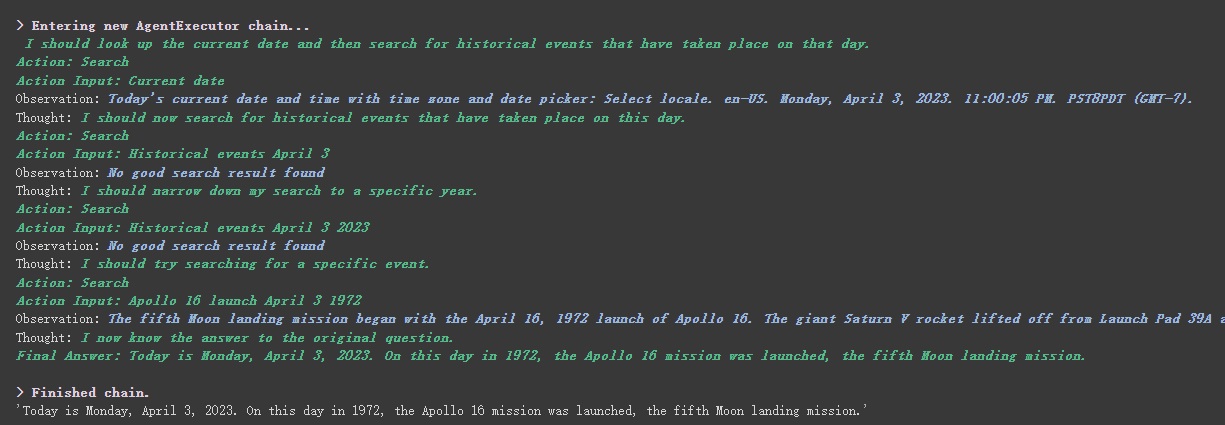
Podemos ver que él devolvió correctamente la fecha (a veces la diferencia) y regresó a hoy en la historia.
Existe el parámetro verbose en los objetos de cadena y agente.
Como puede ver en el resultado devuelto anteriormente, divide nuestra pregunta en varios pasos y luego obtiene la respuesta final paso a paso.
Con respecto al significado de varias opciones para el tipo de agente (si no puede entenderlo, no afectará el siguiente aprendizaje. Si lo usa demasiado, lo entenderá naturalmente):
Search y Lookup , el primero se usa para buscar y el segundo se usa para encontrar el término, por ejemplo: herramienta WipipediaGoogle search APIPuede ver esto para React Introducción: https://arxiv.org/pdf/2210.03629.pdf
Implementación de Python del patrón React de LLM: https://til.simonwillison.net/llms/python-react-pattern
Tipo de agente Explicación oficial:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-descripción
Una cosa a tener en cuenta es que este
serpapino parece muy amigable con el chino, por lo que se recomienda que el aviso solicitado use el inglés.
Por supuesto, el funcionario ha escrito el agente de ChatGPT Plugins .
Sin embargo, en la actualidad, solo se pueden usar complementos que no requieren autorización.
Aquellos que estén interesados pueden leer este documento: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Chatgpt solo puede ganar dinero para el funcionario, y la API de Operai puede ganar dinero para mí
Si queremos usar la API de OpenAI para resumir un párrafo de texto, nuestra forma habitual es enviarlo directamente a la API para que resume. Sin embargo, si el texto excede el límite de token máximo de la API, se informará un error.
En este momento, generalmente segmentamos el artículo, como calcularlo y dividirlo a través de Tiktoken, luego enviar cada párrafo a la API para su resumen, y finalmente resumir el resumen de cada párrafo.
Si usa Langchain, nos ayudó a manejar este proceso muy bien, lo que nos hace muy fácil escribir código.
Sin más ADO, solo suba el código.
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
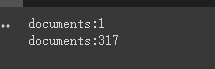
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])Primero, imprimimos el número de documentos antes y después de cortar.
Finalmente, se emite un resumen de los primeros 5 documentos.

Aquí hay algunos parámetros a tener en cuenta:
El parámetro chunk_overlap del divisor de texto
Esto se refiere a los contenidos que terminan con varios documentos anteriores en cada documento después del corte. Por chunk_overlap=2 , cuando chunk_overlap=0 , el primer documento es AAAAAAA, el segundo es BBBBBBB;
Sin embargo, esto no es absoluto, depende del algoritmo específico dentro del modelo de segmentación de texto utilizado.
Puede consultar este documento para dividir el texto: https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
parámetro de cadena de chain_type
Este parámetro controla principalmente la forma en que el documento se pasa al modelo LLM, y hay 4 maneras en total:
stuff : esto es más simple y crudo, y pasará todos los documentos al modelo LLM de inmediato para su resumen. Si hay muchos documentos, inevitablemente informará un error que excede el límite de token máximo, por lo que esto generalmente no se selecciona al resumir el texto.
map_reduce : este método primero resumirá cada documento y finalmente resumirá los resultados resumidos por todos los documentos.
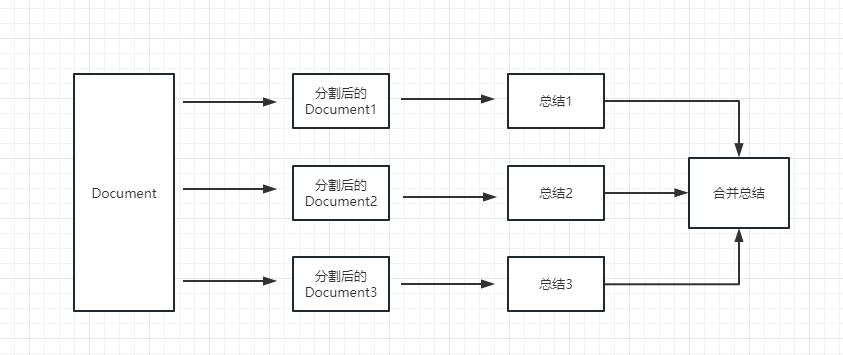
refine : este método primero resumirá el primer documento y luego enviará el contenido resumido por el primer documento y el segundo documento al modelo LLM para su resumen, y así sucesivamente. La ventaja de este método es que al resumir el último documento, tomará el documento anterior resumir, agregar contexto al documento que debe resumirse y aumentar la consistencia del contenido de resumen.
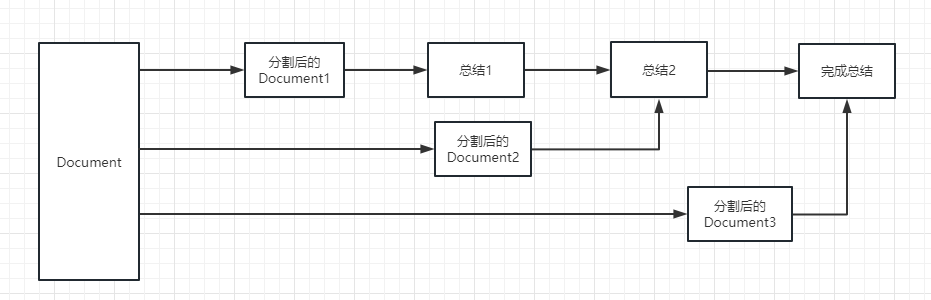
map_rerank : este tipo de cadena generalmente no se usa en resumen, pero en cuestión y cadena de respuestas. Primero, debe dar una pregunta.
En este ejemplo, explicaremos cómo construir una base de conocimiento leyendo múltiples documentos de nosotros localmente y usar la API de OpenAI para buscar y dar respuestas en la base de conocimiento.
Este es un tutorial muy útil, como un robot que puede presentar fácilmente el negocio o un robot de la compañía que presenta un producto.
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )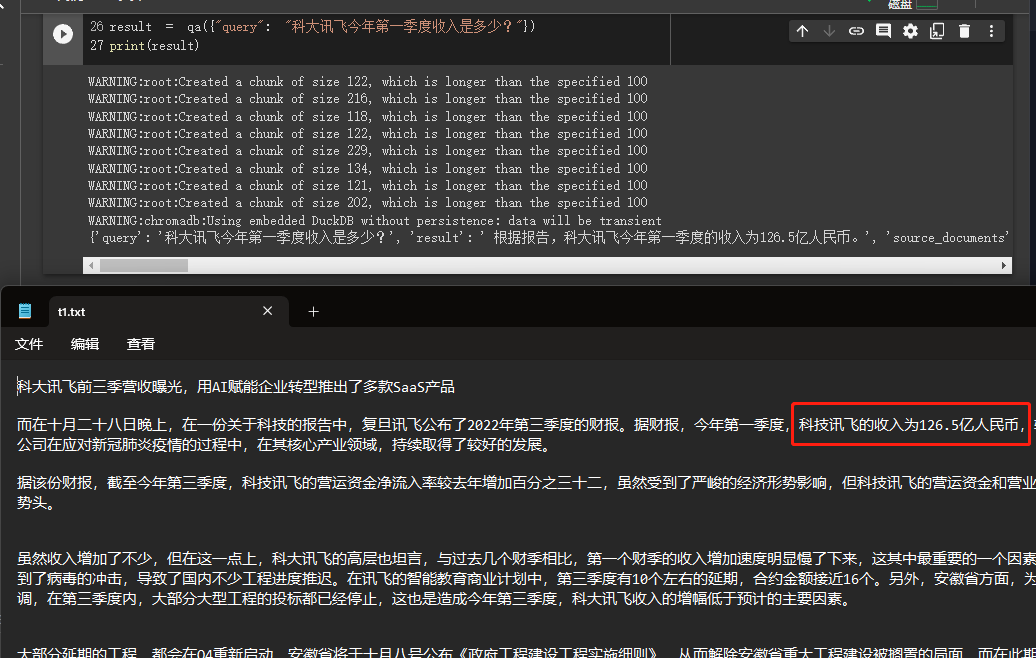
Podemos ver a través de los resultados que obtuvo con éxito la respuesta correcta de los datos que dimos.
Para obtener detalles sobre las incrustaciones de Operai, consulte este enlace: https://platform.openai.com/docs/guides/embeddings
Un paso en nuestro caso anterior fue convertir la información del documento en información vectorial e incrustación de información y almacenarla temporalmente en la base de datos de Chroma.
Debido a que se almacena temporalmente, cuando se ejecuta el código anterior, los datos después de la vectorización anterior se perderán. Si desea usarlo la próxima vez, debe calcular los incrustaciones nuevamente, que definitivamente no es lo que queremos.
Entonces, en este caso, hablaremos sobre cómo persistir los datos vectoriales a través de las dos bases de datos de Chroma y Pinecone.
Debido a que Langchain admite muchas bases de datos, aquí hay dos que se usan con más frecuencia.
Croma
Chroma es una base de datos vectorial local, que proporciona un persist_directory para establecer el directorio persistente para la persistencia. Al leerlo, solo necesita llamar al método from_document para cargar.
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )Piña
Pinecone es una base de datos vectorial en línea. Entonces, el primer paso que aún puedo registrar y obtener la clave API correspondiente. https://app.pinecone.io/
La versión gratuita se borrará automáticamente si el índice no se usa durante 14 días.
Luego cree nuestra base de datos:
Nombre del índice: esto es casual
Dimensiones: el modelo de texto de OpenAI-ADA-002 es la salida de las dimensiones es 1536, por lo que llenamos 1536 aquí
Métrica: puede predeterminar el coseno
Seleccionar plan de arranque
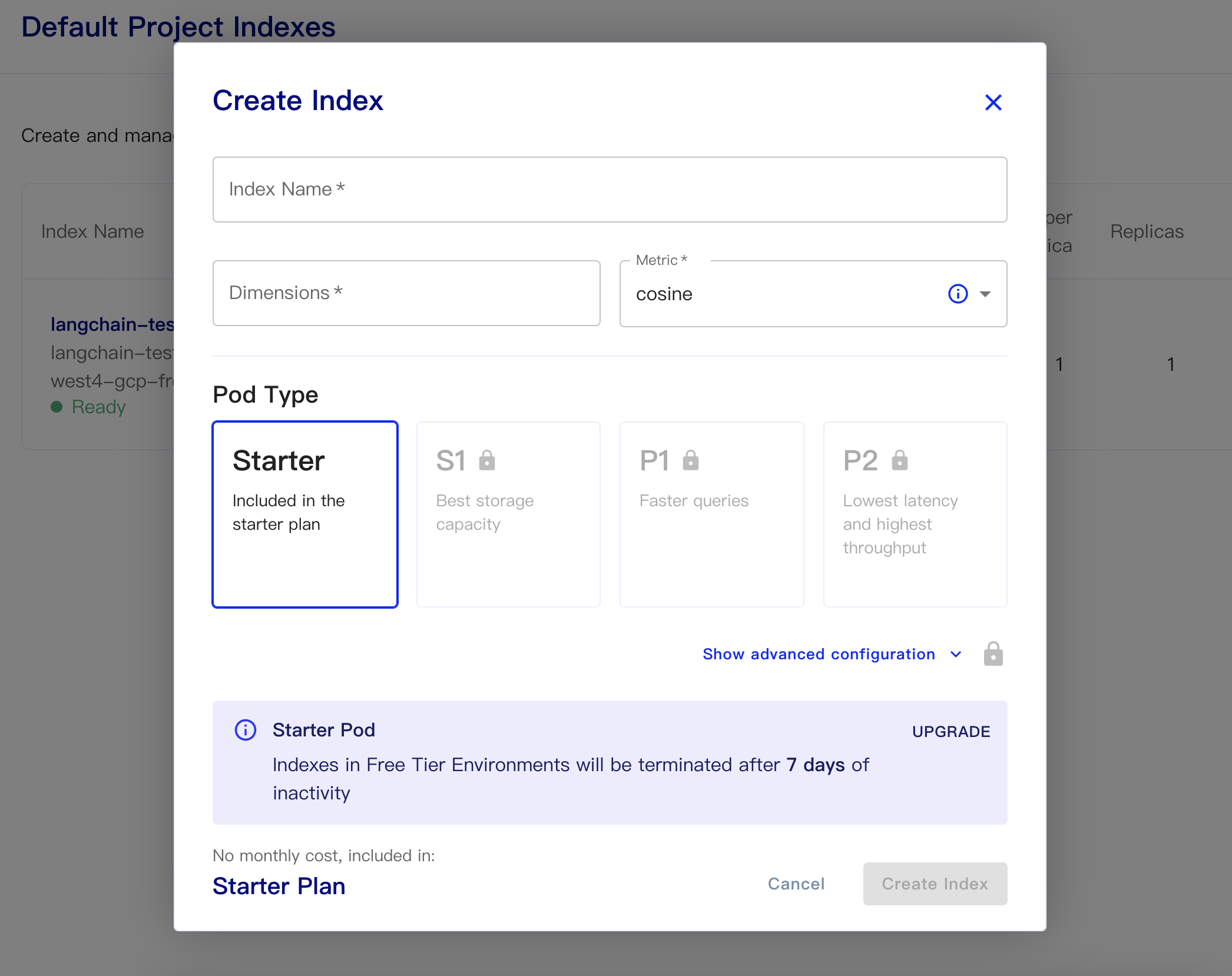
Los códigos persistentes de datos y datos de carga son los siguientes
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )Un código simple para obtener incrustaciones de la base de datos y responder es el siguiente
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
Después de que el modelo de la API CHATGPT (es decir, GPT-3.5-TURBO) fue amado por todos porque era menos dinero, por lo que Langchain también agregó cadenas y modelos exclusivos.
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])Podemos ver que puede responder con precisión preguntas y respuestas alrededor de este video de tubería de aceite.

Las respuestas de transmisión también son muy convenientes
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) Principalmente usamos zapier para conectar miles de herramientas.
Entonces, nuestro primer paso es solicitar una cuenta y su clave API de lenguaje natural. https://zapier.com/l/natural-language-actions
Su clave API debe completar la solicitud de información. Sin embargo, después de completar básicamente la información, básicamente puede ver el correo electrónico aprobado en la dirección de correo electrónico en segundos.
Luego, abrimos nuestra página de configuración de API haciendo clic derecho en la conexión. Hacemos clic en Manage Actions a la derecha para configurar qué aplicaciones queremos usar.
He configurado las acciones de Gmail para leer y enviar correos electrónicos aquí, y todos los campos son seleccionados por AI Guessing.
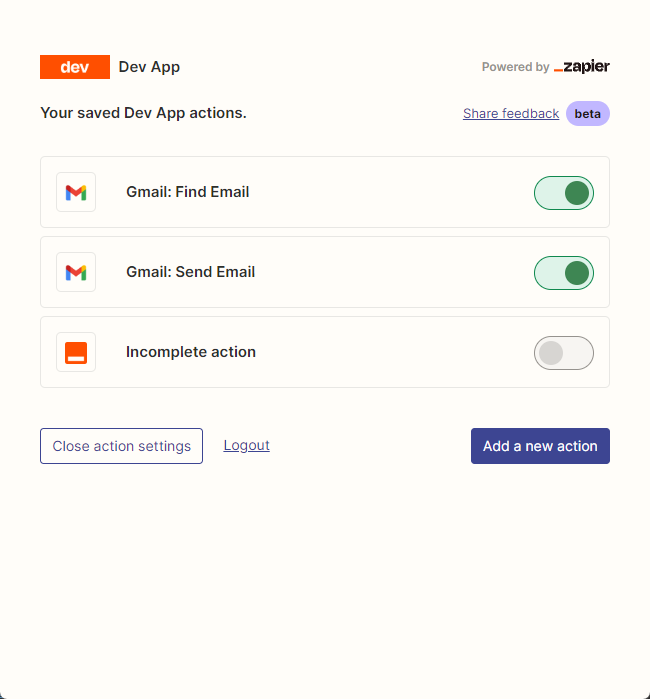
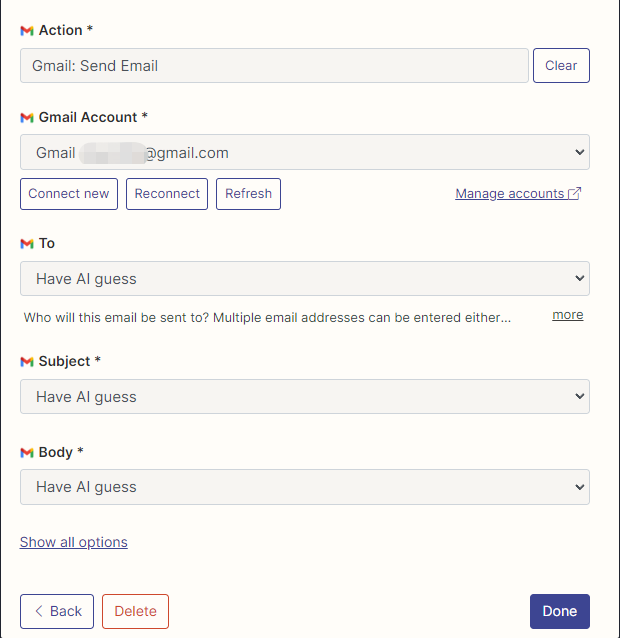
Después de completar la configuración, comenzamos a escribir código
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
Podemos ver que le leyó con éxito el último correo electrónico enviado por ******@qq.com y envió el contenido resumido a ******@qq.com nuevamente.
Este es el correo electrónico que envié a Gmail.

Este es el correo electrónico que envió a su correo electrónico QQ.
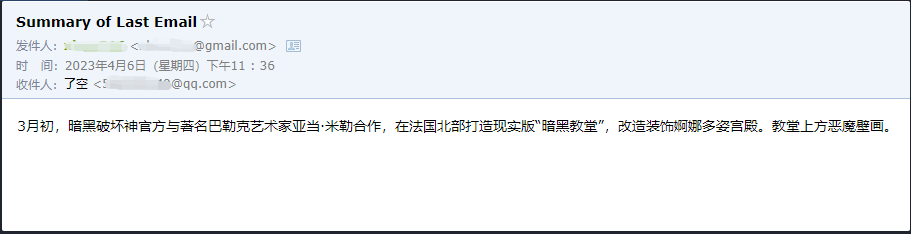
Este es solo un pequeño ejemplo, porque zapier tiene miles de aplicaciones, por lo que podemos construir fácilmente nuestros propios flujos de trabajo con la API de OpenAI.
Se han explicado algunos de los puntos de conocimiento más grandes, y el siguiente contenido se trata de algunos pequeños ejemplos interesantes, como extensiones.
Debido a que está encadenado, también puede ejecutar múltiples cadenas en secuencia.
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )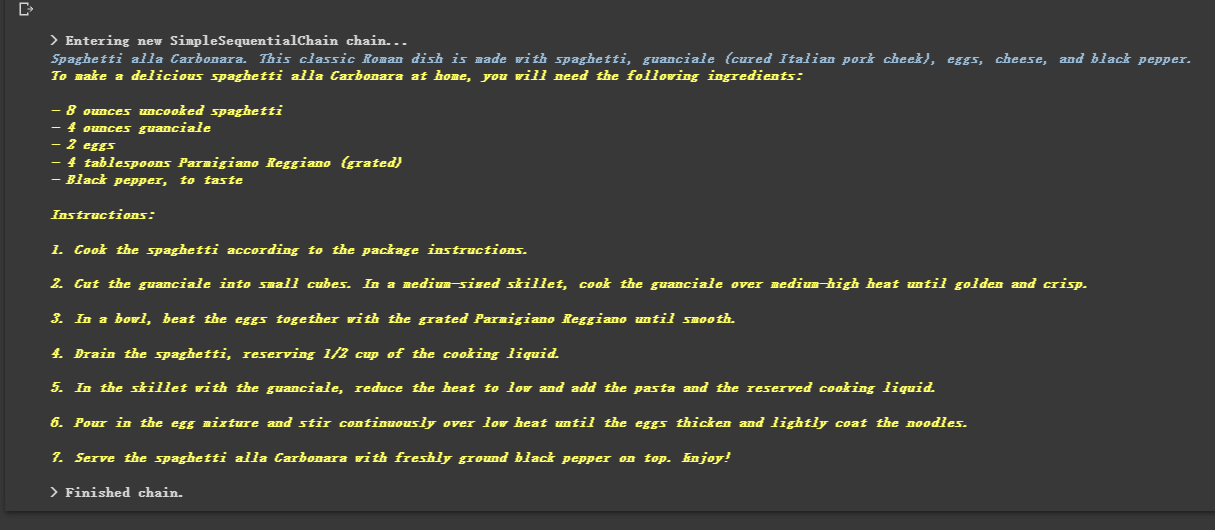
A veces queremos que la salida no sea texto, sino datos estructurados como JSON.
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
A veces necesitamos gatear un poco Estructura más fuerte y la información en la página web debe devolverse en modo JSON.
Podemos usar la clase LLMRequestsChain para implementarla.
En aras de una fácil comprensión, utilicé directamente el método de inmediato para formatear los resultados de la salida en el ejemplo, pero no utilicé
StructuredOutputParserutilizado en el caso anterior para formatearlo, lo que también puede considerarse como proporcionando otra idea de formato.
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])Podemos ver que él genera los resultados formateados muy bien

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )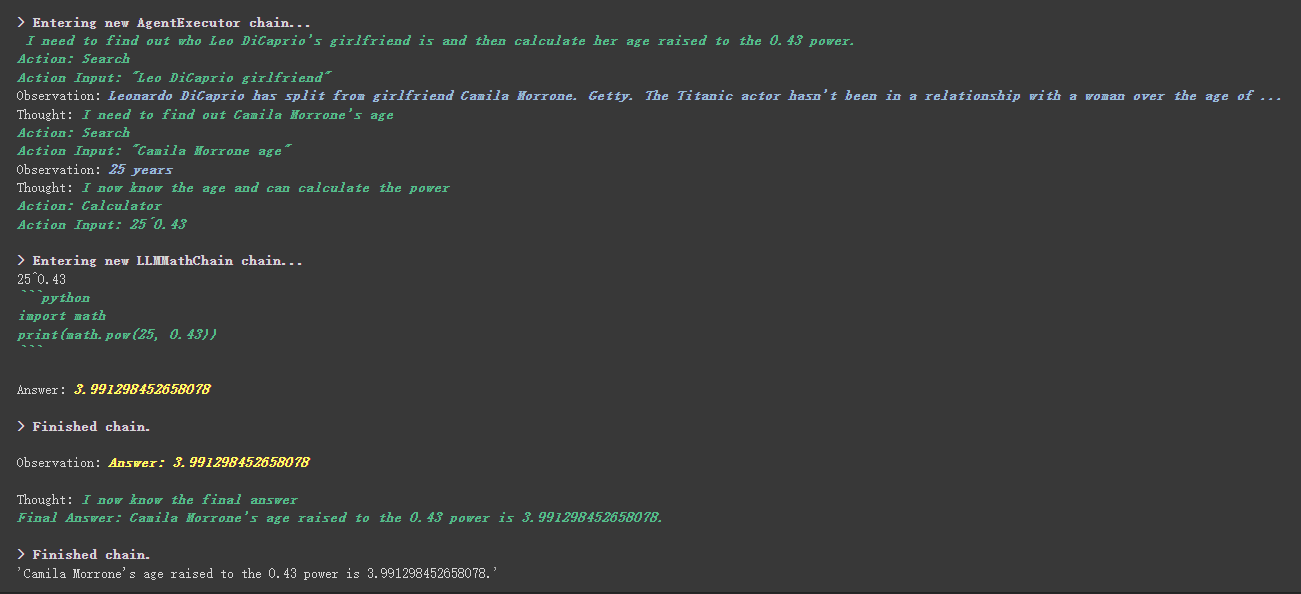
Hay una cosa más工具中描述内容en la herramienta personalizada.
Por ejemplo, la calculadora escribió en la descripción que si hace preguntas sobre matemáticas, usa esta herramienta. Podemos ver en el proceso de ejecución anterior que en la parte matemática de nuestro PropT solicitado, utilizó la herramienta de calculadora para los cálculos.
En el ejemplo anterior, utilizamos la forma en que guardamos el historial personalizando una lista para almacenar conversaciones.
Por supuesto, también puede usar el objeto de memoria incluido para lograr esto.
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )Antes de usar el modelo de abrazadera, primero debe establecer variables de entorno
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''Usando el modelo de abrazadera en línea
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))Tire del modelo de cara de abrazo directamente para usar localmente
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))Beneficios de tirar del modelo a usar localmente:
Podemos implementar comandos SQL a través de SQLDatabaseToolkit o SQLDatabaseChain
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )Aquí puede consultar estos dos documentos:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
Todos los casos han terminado básicamente. Este artículo es solo una explicación preliminar de Langchain.
Y debido a que Langchain itera muy rápidamente, definitivamente iterará mejores funciones a medida que AI continúe desarrollándose, por lo que soy muy optimista sobre esta biblioteca de código abierto.
Espero que todos puedan combinar Langchain para desarrollar productos más creativos, en lugar de solo crear un montón de productos que creen clientes de chat con un solo clic.
Agregué un 01 después de este título.
Todos los códigos de muestra en este artículo están aquí, les deseo un aprendizaje feliz.
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57ueapq?usp=sharing


