LangChain Chinese Getting Started Guide
1.0.0
Zum einfachen Lesen wurden Gitbooks generiert: https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
GitHub-Adresse: https://github.com/liaokongvfx/langchain-chinese-getting-started-guide
"Langchain Technology Decryption: Ein Panorama -Leitfaden zum Erstellen großer Modellanwendungen" wurde jetzt veröffentlicht: https://item.jd.com/14598210.html
Tiefpreis inländische und ausländische KI-Modell-API-Transfer: https://api.91ai.me
Weil die Langchain -Bibliothek schnell aktualisiert und iteriert wurde, das Dokument jedoch Anfang April geschrieben wurde und ich nur begrenzte persönliche Energie habe, sodass der Code in Colab möglicherweise etwas veraltet ist. Wenn Sie zuerst nach dem Betrieb eines Unternehmens nach dem aktuellen Dokument suchen, erwähnen Sie das Problem, wenn das Dokument nicht aktualisiert wurde
Ich habe einen Changelog hinzugefügt und den neuen Inhalt aktualisiert.
Wenn Sie die Anforderung Root Route der OpenAI -API an Ihre eigene Proxy -Adresse ändern möchten, können Sie diese ändern, indem Sie die Umgebungsvariable "openai_api_base" einstellen.
Verwandter Referenzcode: https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbe1/openai/__init__.py#l4888
Oder wenn Sie OpenAI-bezogene Modellobjekte initialisieren, geben Sie die Variable "OpenAI_API_BASE" über.
Verwandter Referenzcode: https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
Wie wir alle wissen, kann die API von OpenAI nicht mit dem Internet in Verbindung gebracht werden. Daher ist es definitiv unmöglich, ihre eigenen Funktionen zu verwenden, um Antworten zu suchen und Antworten zu geben, PDF -Dokumente zusammenzufassen und Q & A basierend auf einem YouTube -Video auszuführen. Lassen Sie uns also eine sehr leistungsstarke Open-Source-Bibliothek von Drittanbietern vorstellen: LangChain .
Dokumentadresse: https://python.langchain.com/en/latest/
Diese Bibliothek ist derzeit sehr aktiv und iteriert jeden Tag.
Langchain ist ein Rahmen für die Entwicklung von Anwendungen, die von Sprachmodellen betrieben werden. Er hat 2 Hauptfähigkeiten:
LLM -Modell: großes Sprachmodell, großes Sprachmodell
LLM -Anruf
Forderungsverwaltung unterstützt verschiedene benutzerdefinierte Vorlagen
Es verfügt über eine große Anzahl von Dokumentladern wie E -Mail, Markdown, PDF, YouTube ...
Unterstützung für Indizes
Ketten
Ich glaube, jeder wird nach dem Lesen der obigen Einführung verwirrt sein. Keine Sorge, das obige Konzept ist eigentlich nicht sehr wichtig, wenn wir anfingen zu lernen, nachdem wir die folgenden Beispiele beendet haben, werden wir viel verstehen, wenn wir auf den obigen Inhalt zurückblicken.
Hier sind jedoch einige Konzepte, die bekannt sein müssen.
Wie der Name schon sagt, wird Daten aus einer bestimmten Quelle geladen. Zum Beispiel: Ordner DirectoryLoader , Azure Storage AzureBlobStorageContainerLoader , CSV -Datei CSVLoader , EVERNOTE EverNoteLoader , Google GoogleDriveLoader , jede Webseite UnstructuredHTMLLoader , pdf PyPDFLoader , S3DirectoryLoader / S3FileLoader ,
YouTube YoutubeLoader usw. Ich habe nur einige davon kurz aufgeführt.
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
Nach dem Lesen der Datenquelle mit dem Loader Loader muss die Datenquelle in ein Dokumentobjekt konvertiert werden, bevor sie später verwendet werden kann.
Wie der Name schon sagt, wird die Textsegmentierung verwendet, um Text zu teilen. Warum müssen Sie Text teilen? Denn jedes Mal, wenn wir Text als Openai -API senden oder die OpenAI -API -Einbettungsfunktion verwenden, gibt es Zeichenbeschränkungen.
Wenn wir beispielsweise eine 300-seitige PDF an die OpenAI-API senden und ihn bitten, zusammenzufassen, wird er definitiv einen Fehler melden, der das maximale Token übersteigt. Hier müssen wir also einen Textsplitter verwenden, um das Dokument zu teilen, in dem unser Lader eingeht.
Da die Datenkorrelationssuche tatsächlich ein Vektoroperation ist. Unabhängig davon, ob wir die OpenAI -API -Einbettungsfunktion verwenden oder direkt über die Vektordatenbank abfragen, müssen wir unser geladenes Document vektorisieren, um die Suche nach Vektoroperationen durchzuführen. Das Konvertieren in einen Vektor ist ebenfalls sehr einfach.
Der Beamte stellt uns auch viele Vektor -Datenbanken zur Verfügung.
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
Wir können Kette als Aufgabe verstehen. Eine Kette ist eine Aufgabe und kann natürlich auch mehrere Ketten nacheinander wie eine Kette ausführen.
Wir können einfach verstehen, dass es uns dynamisch helfen kann, Kette auszuwählen und aufzurufen oder vorhandene Tools.
Für den Ausführungsprozess finden Sie im folgenden Bild:
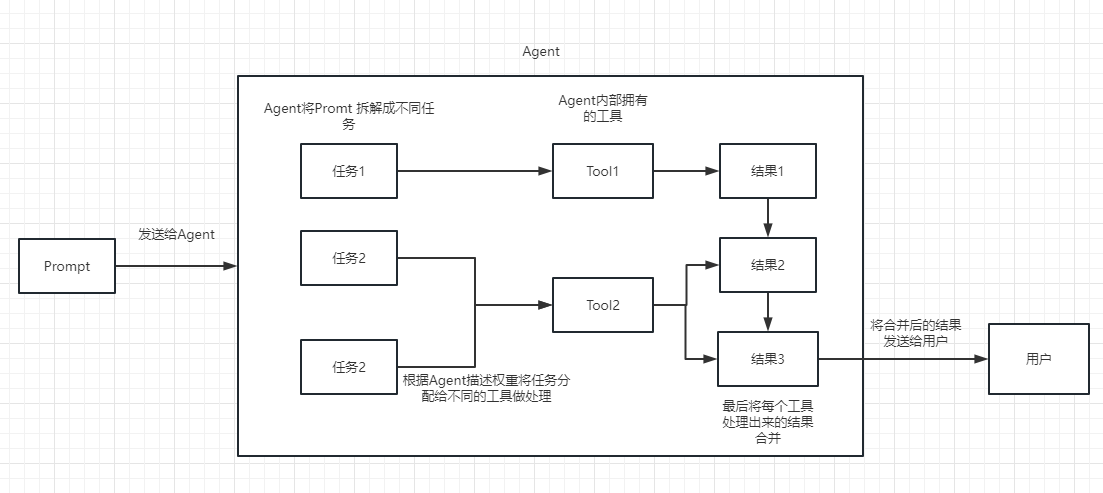
Wird verwendet, um die Relevanz des Textes zu messen. Dies ist auch der Schlüssel zur Fähigkeit der OpenAI -API, eine eigene Wissensbasis aufzubauen.
Sein größter Vorteil gegenüber der Feinabstimmung besteht darin, dass er nicht trainieren muss und in Echtzeit neue Inhalte hinzufügen kann, anstatt einmal neue Inhalte hinzuzufügen, und die Kosten in allen Aspekten sind viel niedriger als die Feinabstimmung.
Weitere Vergleiche und Auswahlmöglichkeiten finden Sie in diesem Video: https://www.youtube.com/watch?v=9qq6HTR7OCW
Durch die oben genannten wesentlichen Konzepte sollten Sie ein gewisses Verständnis von Langchain haben, aber Sie sind möglicherweise immer noch ein wenig verwirrt.
Dies sind alles kleine Fragen.
Da unsere OpenAI -API fortgeschritten ist, basieren die in unseren nachfolgenden Beispielen verwendeten LLM als Beispiel auf Open AI.
Am Ende dieses Artikels wird natürlich der gesamte Code als Colab Ipynb -Datei gespeichert und für alle gelernt.
Es wird empfohlen, jedes Beispiel in der Reihenfolge zu betrachten, da im nächsten Beispiel die Wissenspunkte im vorherigen Beispiel verwendet werden.
Wenn Sie etwas nicht verstehen, können Sie es sich nicht mehr Sorgen machen.
Im ersten Fall werden wir Langchain verwenden, um das OpenAI -Modell zu laden und ein Q & A zu vervollständigen.
Bevor wir anfangen, müssen wir zuerst unseren OpenAI -Schlüssel einrichten.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'Dann importieren und führen wir aus
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
Zu diesem Zeitpunkt können wir das Ergebnis sehen, das er uns gegeben hat.
Als nächstes tun wir etwas Interessantes. Lassen Sie uns unsere Openai -API dazu bringen, online zu suchen und uns die Antworten an uns zurückzugeben.
Hier müssen wir SERPAPI verwenden, um es zu implementieren, was eine API -Schnittstelle für die Google -Suche bietet.
Zunächst müssen wir einen Benutzer auf der offiziellen SERPAPI -Website unter https://serpapi.com/ registrieren und ihn kopieren, um den API -Schlüssel für uns zu generieren.
Dann müssen wir es in die Umgebungsvariable wie den oben OpenAI -API -Schlüssel einstellen.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'Dann fangen Sie an, meinen Code zu schreiben
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )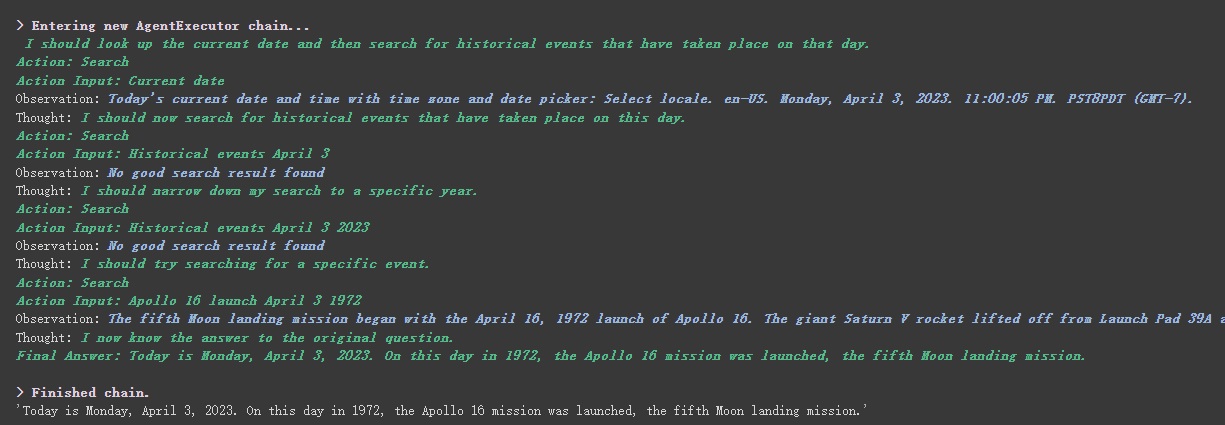
Wir können sehen, dass er das Datum (manchmal Differenz) richtig zurückgegeben und heute in der Geschichte zurückgegeben hat.
Es gibt den verbose in Ketten- und Agentenobjekten.
Wie Sie aus dem oben zurückgegebenen Ergebnis sehen können, teilt er unsere Frage in mehrere Schritte auf und erhält dann Schritt für Schritt die endgültige Antwort.
In Bezug auf die Bedeutung mehrerer Optionen für den Agententyp (wenn Sie es nicht verstehen können, wirkt sich dies nicht auf das folgende Lernen aus. Wenn Sie es zu stark verwenden, werden Sie es natürlich verstehen):
Search und Lookup zu verwenden. Ersteres wird verwendet, um zu suchen, und letzteres wird verwendet, um den Begriff zu finden, zum Beispiel: Wipipedia -ToolGoogle search API ToolSie können dies für React Einführung sehen: https://arxiv.org/pdf/2210.03629.pdf
Python-Implementierung des React-Musters von LLM: https://til.simonwillison.net/llms/python-react-pattern
Beamte Erklärung des Agenten Typ:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=Zero-shot-react-description
Eine Sache zu beachten ist, dass diese
serpapifür Chinesisch nicht sehr freundlich erscheint. Daher wird die Eingabeaufforderung empfohlen, Englisch zu verwenden.
Natürlich hat der Beamte den Agenten von ChatGPT Plugins geschrieben.
Gegenwärtig können jedoch nur Plug-Ins verwendet werden, die keine Autorisierung erfordern.
Diejenigen, die interessiert sind, können dieses Dokument lesen
Chatgpt kann nur Geld für den Beamten verdienen, und die OpenAI -API kann Geld für mich verdienen
Wenn wir die OpenAI -API verwenden möchten, um einen Absatz des Textes zusammenzufassen, können Sie ihn direkt an die API senden, damit er zusammenfasst. Wenn der Text jedoch die maximale Token -Grenze der API überschreitet, wird ein Fehler gemeldet.
Zu diesem Zeitpunkt segmentieren wir den Artikel im Allgemeinen, z. B. die Berechnung und Dividierung durch Tiktoken, dann jeden Absatz zur Zusammenfassung an die API und schließlich die Zusammenfassung jedes Absatzes zusammenzufassen.
Wenn Sie Langchain verwenden, hat er uns geholfen, diesen Prozess sehr gut zu bewältigen, sodass es uns sehr einfach macht, Code zu schreiben.
Laden Sie ohne weiteres den Code hoch.
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
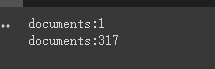
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])Zunächst drucken wir die Anzahl der Dokumente vor und nach dem Schneiden, dass es im gesamten Artikel nur ein Dokument gibt.
Schließlich wird eine Zusammenfassung der ersten 5 Dokumente ausgegeben.

Hier sind einige Parameter zu beachten:
Der Parameter chunk_overlap des Textsplitters
Dies bezieht sich auf den Inhalt, der mit mehreren vorherigen Dokument in jedem Dokument nach dem Schneiden endet. Wenn beispielsweise chunk_overlap=0 chunk_overlap=2 ist das erste Dokument aaaaaaa, das zweite ist BBBBBB;
Dies ist jedoch nicht absolut, es hängt vom spezifischen Algorithmus innerhalb des verwendeten Textsegmentierungsmodells ab.
Sie können sich auf dieses Dokument finden
chain_type Parameter der Kette
Dieser Parameter steuert hauptsächlich die Art und Weise, wie das Dokument an das LLM -Modell übergeben wird, und es gibt insgesamt 4 Möglichkeiten:
stuff : Dies ist einfachste und grobe und wird alle Dokumente gleichzeitig an das LLM -Modell übergeben, um eine Zusammenfassung zu erzielen. Wenn es viele Dokumente gibt, meldet es zwangsläufig einen Fehler, der die maximale Token -Grenze überschreitet. Dies wird im Allgemeinen bei der Zusammenfassung des Textes im Allgemeinen nicht ausgewählt.
map_reduce : Diese Methode fasst zunächst jedes Dokument zusammen und fasst schließlich die von allen Dokumenten zusammengefassten Ergebnisse zusammen.
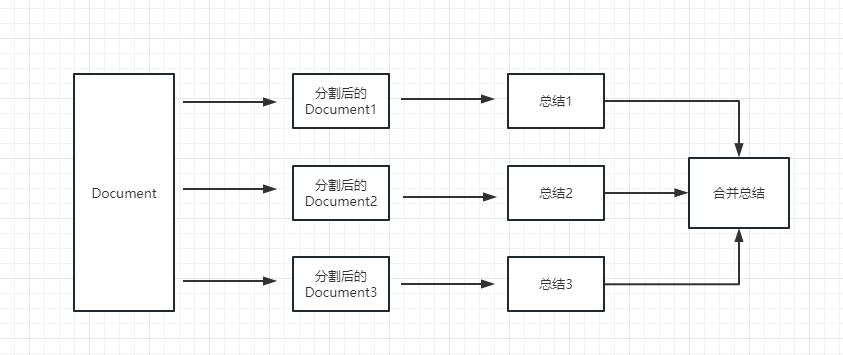
refine : Diese Methode fasst zuerst das erste Dokument zusammen und sendet dann den vom ersten Dokument zusammengefassten Inhalt und das zweite Dokument an das LLM -Modell für eine Zusammenfassung usw. Der Vorteil dieser Methode besteht darin, dass beim Zusammenfassen des letzteren Dokuments das vorherige Dokument zum Zusammenfassen des Dokuments, das zusammengefasst werden muss, einen Kontext hinzufügen und die Konsistenz des Zusammenfassungsinhalts erhöhen muss.
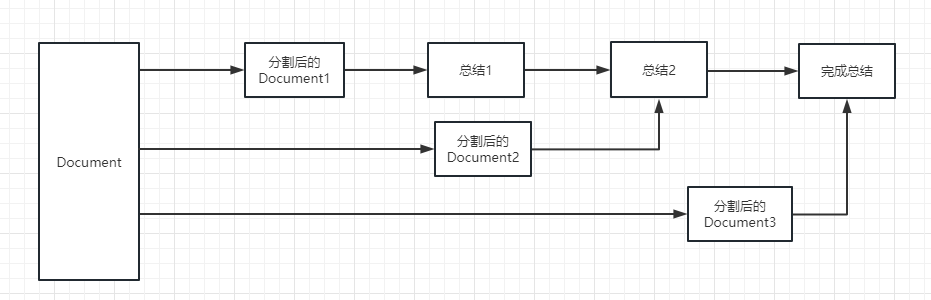
map_rerank : Diese Art der Kette wird im Allgemeinen nicht zusammenfassend, sondern in Frage und Antwortkette. Zuerst müssen Sie eine Frage angeben.
In diesem Beispiel werden wir erklären, wie Sie eine Wissensbasis erstellen, indem Sie mehrere Dokumente von uns lokal lesen und die OpenAI -API verwenden, um Antworten in der Wissensbasis zu suchen und zu geben.
Dies ist ein sehr nützliches Tutorial, beispielsweise ein Roboter, der das Geschäft des Unternehmens problemlos vorstellen kann, oder einen Roboter, der ein Produkt einführt.
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )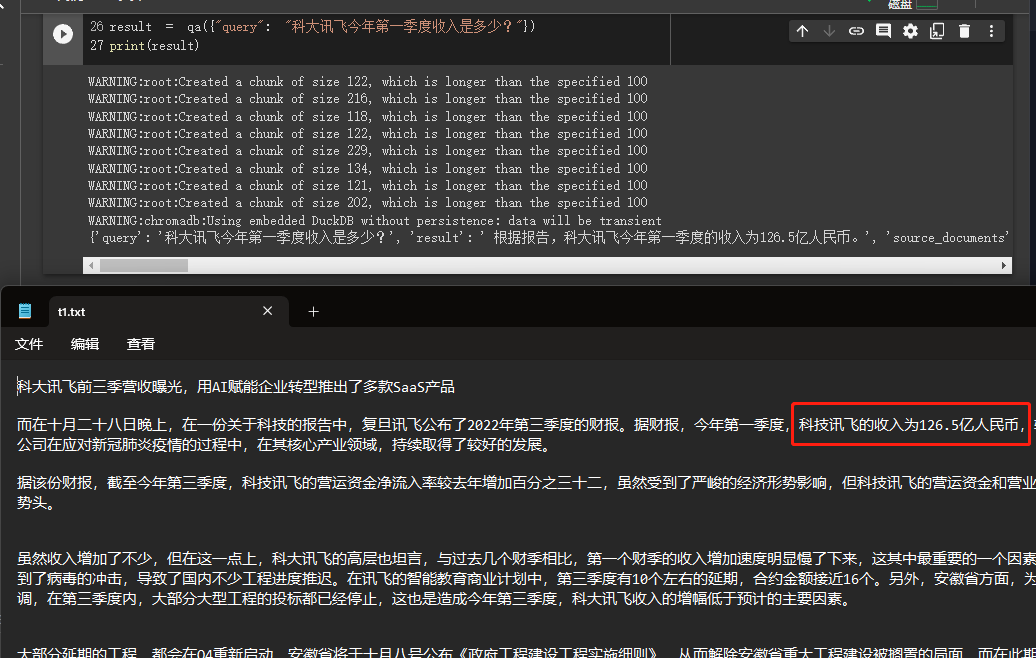
Wir können die Ergebnisse durchsehen, die er erfolgreich die richtige Antwort aus den Daten erhalten hat, die wir angegeben haben.
Weitere Informationen zu OpenAI -Einbettungen finden Sie in diesem Link: https://platform.openai.com/docs/guides/embedings
Ein Schritt in unserem vorherigen Fall bestand darin, Dokumentinformationen in Vektorinformationen umzuwandeln und Informationen einzubetten und diese vorübergehend in die Chroma -Datenbank zu speichern.
Da es vorübergehend gespeichert wird, gehen die Daten nach der obigen Vektorisierung bei der Ausführung des obigen Codes verloren. Wenn Sie es das nächste Mal verwenden möchten, müssen Sie die Einbettungen erneut berechnen, was definitiv nicht das ist, was wir wollen.
In diesem Fall werden wir darüber sprechen, wie Vektordaten durch die beiden Datenbanken von Chroma und Tinecone bestehen können.
Da Langchain viele Datenbanken unterstützt, werden hier zwei häufiger verwendet.
Chroma
Chroma ist eine lokale Vektor -Datenbank, die eine persist_directory für das persistente Verzeichnis für die Persistenz bereitstellt. Beim Lesen müssen Sie nur die from_document -Methoden zum Laden aufrufen.
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )Tannenzapfen
PineCone ist eine Online -Vektor -Datenbank. Der erste Schritt kann ich mich also noch registrieren und den entsprechenden API -Schlüssel erhalten. https://app.pinecone.io/
Die kostenlose Version wird automatisch gelöscht, wenn der Index 14 Tage lang nicht verwendet wird.
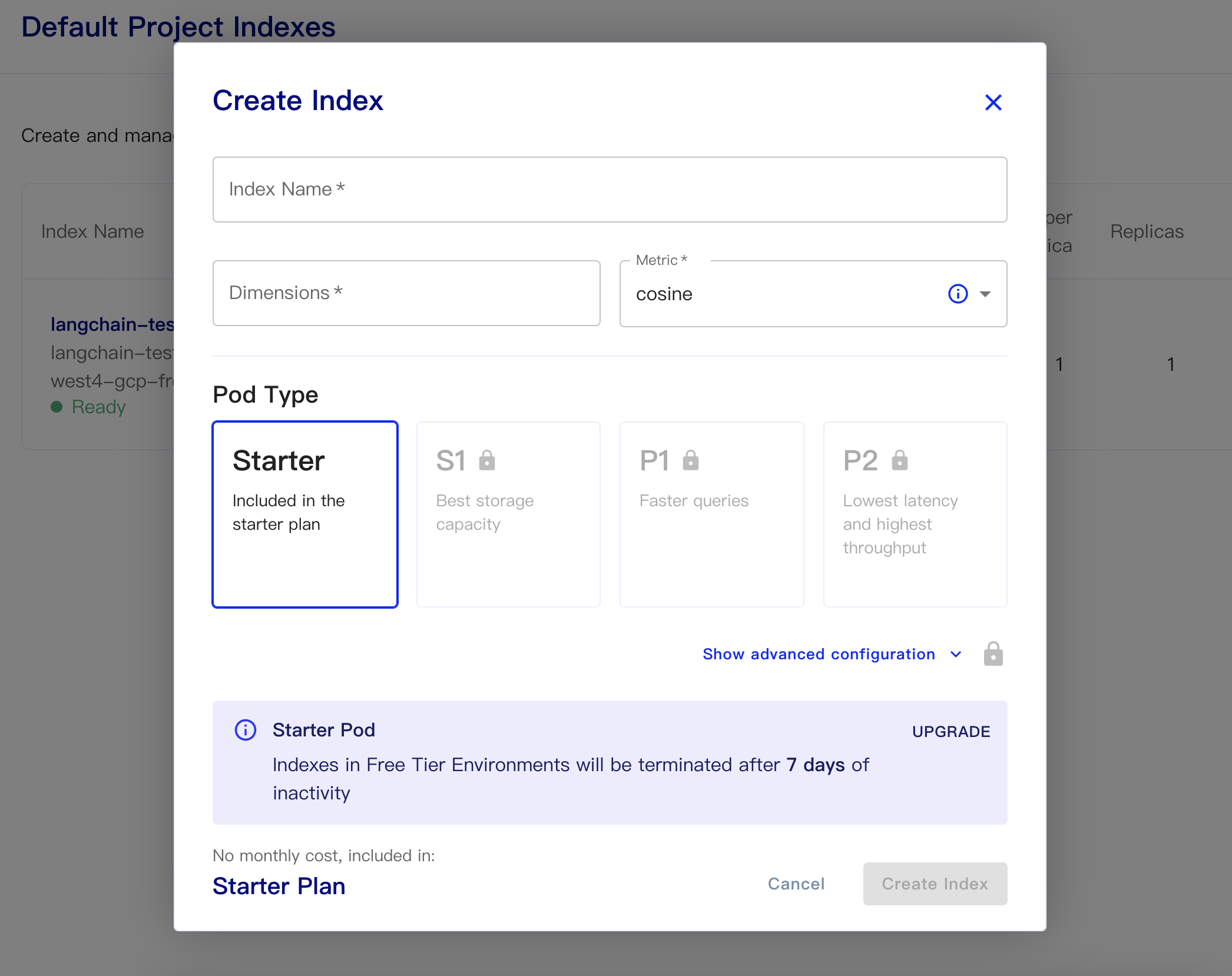
Erstellen Sie dann unsere Datenbank:
Indexname: Das ist lässig
Abmessungen: OpenAs Text-Embedding-ada-ada-002-Modell ist die Ausgabeabmessungen beträgt 1536, also füllen wir hier 1536 aus
Metrik: kann standardmäßig Cosinus
Wählen Sie Starterplan
Die anhaltenden Daten- und Lastdatencodes sind wie folgt
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )Ein einfacher Code, um Einbettung aus der Datenbank zu erhalten und dies wie folgt zu beantworten
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
Nachdem das Chatgpt-API (dh GPT-3,5-Turbo) -Modell veröffentlicht wurde, wurde es von allen geliebt, weil es weniger Geld war, so dass Langchain auch exklusive Ketten und Modelle hinzugefügt hat, um dieses Beispiel zu sehen, wie man sie benutzt.
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])Wir können sehen, dass er Fragen und Antworten in diesem Ölrohrvideo genau beantworten kann

Streaming -Antworten sind auch sehr bequem
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) Wir verwenden hauptsächlich zapier , um Tausende von Werkzeugen zu verbinden.
Unser erster Schritt ist also, einen Konto und seinen natürlichen API -Schlüssel zu beantragen. https://zapier.com/l/natural-language-actions
Sein API -Schlüssel muss die Informationsanwendung ausfüllen. Nachdem Sie die Informationen grundsätzlich ausgefüllt haben, können Sie die genehmigte E -Mail in der E -Mail -Adresse in Sekunden im Grunde genommen sehen.
Dann öffnen wir unsere API-Konfigurationsseite, indem wir mit der rechten Maustaste auf die Verbindung klicken. Wir klicken auf Manage Actions , um die Anwendungen zu konfigurieren, die wir verwenden möchten.
Ich habe die Aktionen von Google Mail zum Lesen und Senden von E -Mails hier konfiguriert, und alle Felder werden durch KI -Vermutungen ausgewählt.
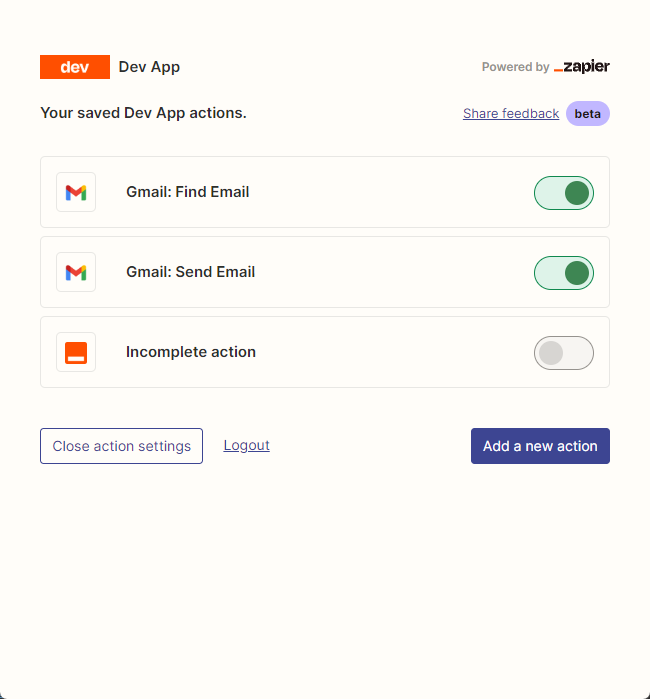
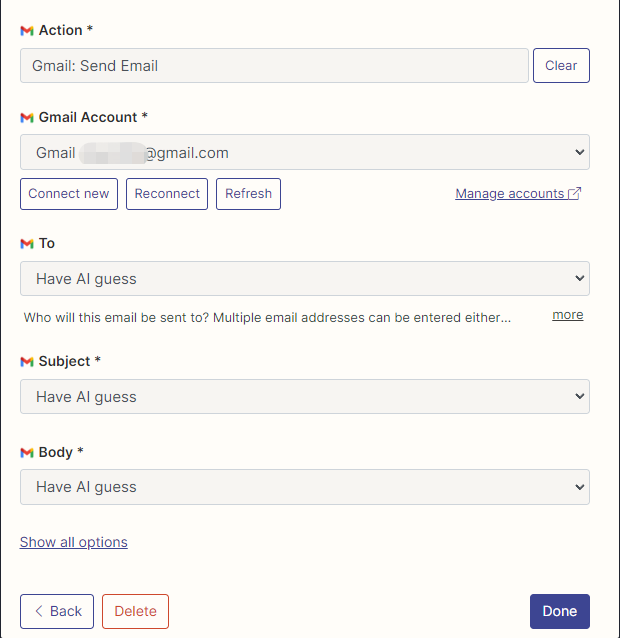
Nach Abschluss der Konfiguration beginnen wir mit dem Schreiben von Code zu schreiben
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
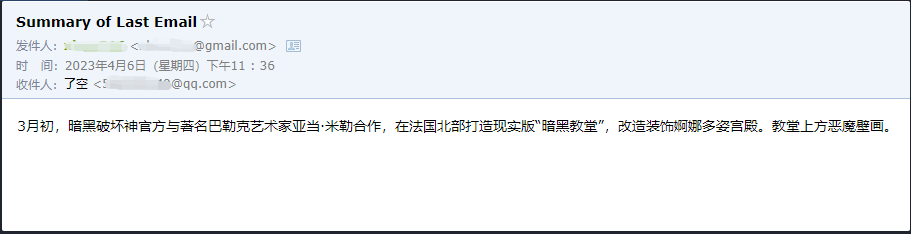
Wir können sehen, dass er die letzte E -Mail erfolgreich gelesen hat, die ihm von ******@qq.com gesendet wurde, und den zusammenfassenden Inhalt erneut an ******@qq.com gesendet hat.
Dies ist die E -Mail, die ich an Google Mail gesendet habe.

Dies ist die E -Mail, die er an seine QQ -E -Mail gesendet hat.
Dies ist nur ein kleines Beispiel, da zapier Tausende von Anwendungen hat, sodass wir mit der OpenAI -API problemlos unsere eigenen Workflows erstellen können.
Einige der größeren Wissenspunkte wurden erläutert, und der folgende Inhalt dreht sich um einige interessante kleine Beispiele als Erweiterungen.
Da es gekettet ist, kann er auch mehrere Ketten nacheinander ausführen.
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )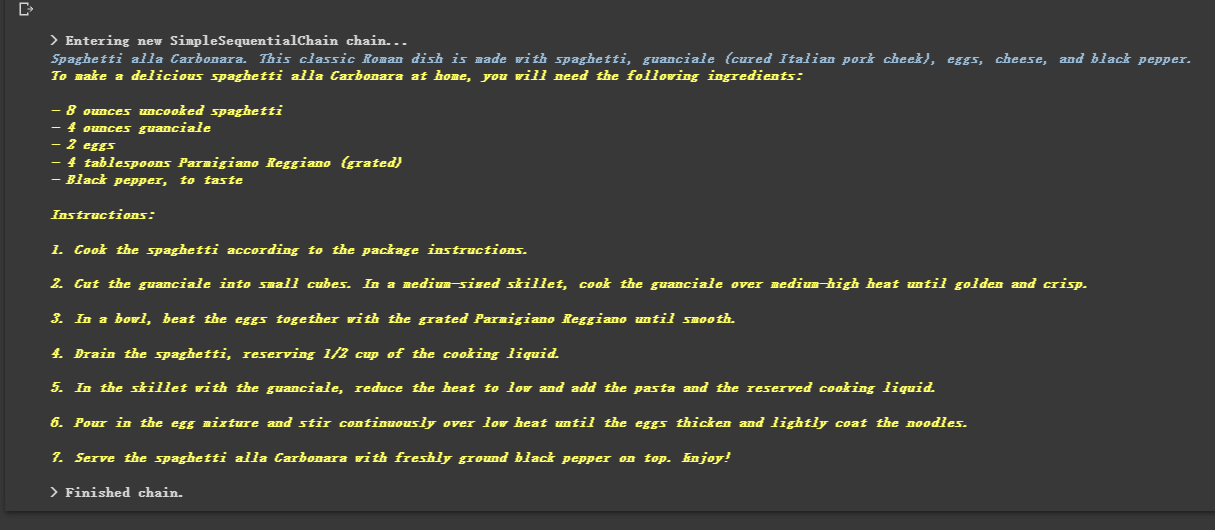
Manchmal möchten wir, dass die Ausgabe nicht Text ist, sondern strukturierte Daten wie JSON.
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
Manchmal müssen wir einige kriechen Stärkere Struktur und die Informationen auf der Webseite müssen im JSON -Modus zurückgegeben werden.
Wir können die LLMRequestsChain -Klasse verwenden, um sie zu implementieren.
Aus Gründen des einfachen Verständnisses habe ich die Eingabeaufforderung Methode direkt verwendet, um die Ausgabeergebnisse im Beispiel zu formatieren, aber den im vorherigen Fall verwendeten
StructuredOutputParsernicht verwendet, um ihn zu formatieren, was auch als eine andere Formatierungsidee angesehen werden kann.
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])Wir können sehen, dass er die formatierten Ergebnisse sehr gut ausgibt

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )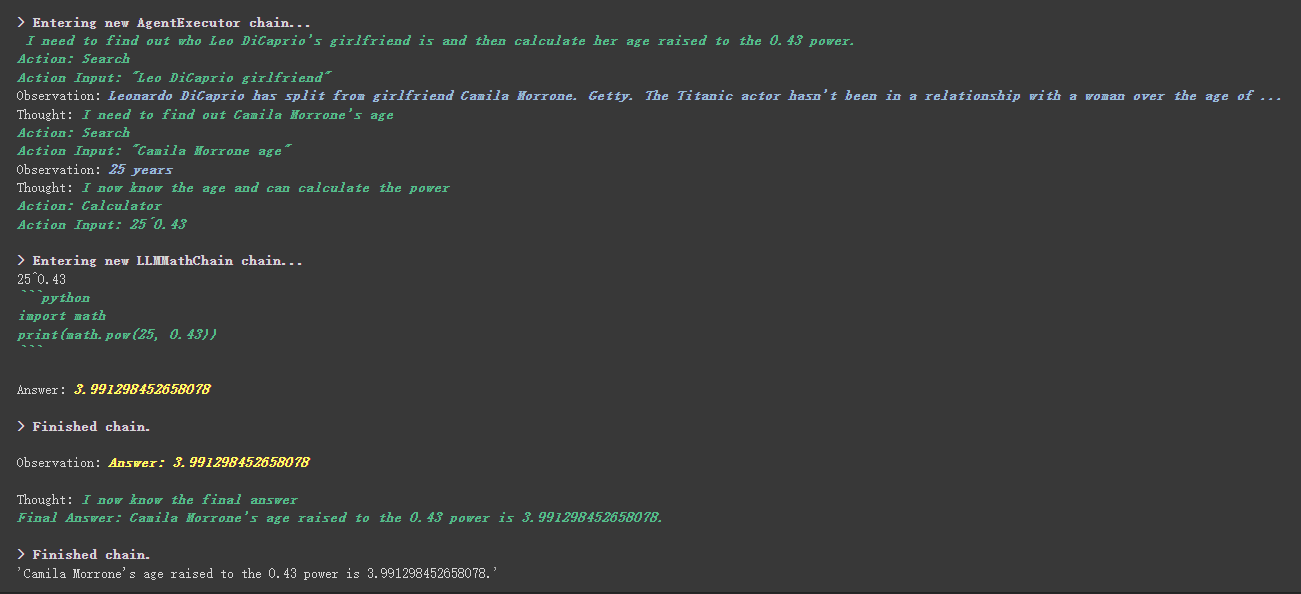
Es工具中描述内容eine interessantere Sache im benutzerdefinierten Tool.
Der Taschenrechner schrieb beispielsweise in der Beschreibung, dass Sie dieses Tool verwenden, wenn Sie Fragen zur Mathematik stellen. Wir können im obigen Ausführungsprozess sehen, dass er im mathematischen Teil unseres angeforderten APPT das Taschenrechner -Tool für Berechnungen verwendete.
Im vorherigen Beispiel haben wir die Art und Weise verwendet, wie wir die Geschichte gespeichert haben, indem wir eine Liste an Gespräche anpassen.
Natürlich können Sie das enthaltene Speicherobjekt auch verwenden, um dies zu erreichen.
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )Bevor Sie das umarmende Gesichtsmodell verwenden, müssen Sie zuerst Umgebungsvariablen festlegen
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''Verwenden Sie das umarmende Gesichtsmodell online
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))Ziehen Sie das umarmende Gesichtsmodell direkt, um lokal zu verwenden
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))Vorteile des Modells, das vor Ort zu verwenden:
Wir können SQL -Befehle über SQLDatabaseToolkit oder SQLDatabaseChain implementieren
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )Hier können Sie sich auf diese beiden Dokumente beziehen:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
Alle Fälle sind im Grunde genommen beendet. Dieser Artikel ist nur eine vorläufige Erklärung von Langchain.
Und weil Langchain sehr schnell iteratiert, wird es definitiv bessere Funktionen durchführen, wenn sich die KI weiterentwickelt, sodass ich in dieser Open -Source -Bibliothek sehr optimistisch bin.
Ich hoffe, jeder kann Langchain kombinieren, um kreative Produkte zu entwickeln, anstatt nur eine Reihe von Produkten zu erstellen, die Chat -Kunden mit einem Klick aufbauen.
Ich habe nach diesem Titel ein 01 hinzugefügt.
Alle Beispielcodes in diesem Artikel sind hier, ich wünsche Ihnen ein glückliches Lernen.
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57ueapq?usp=sharing


