LangChain Chinese Getting Started Guide
1.0.0
為了便於閱讀,已生成gitbook:https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
github地址:https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
《LangChain技術解密:構建大模型應用的全景指南》現已出版:https://item.jd.com/14598210.html
低價國內外ai 模型api 中轉:https://api.91ai.me
因為langchain庫一直在飛速更新迭代,但該文檔寫與4月初,並且我個人精力有限,所以colab裡面的代碼有可能有些已經過時。如果有運行失敗的可以先搜索一下當前文檔是否有更新,如文檔也沒更新歡迎提issue,或者修復後直接提pr,感謝~
加了個CHANGELOG,更新了新的內容我會寫在這裡,方便之前看過的朋友快速查看新的更新內容
如果想把OPENAI API 的請求根路由修改成自己的代理地址,可以通過設置環境變量“OPENAI_API_BASE” 來進行修改。
相關參考代碼:https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#L48
或在初始化OpenAI相關模型對象時,傳入“openai_api_base” 變量。
相關參考代碼:https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#L148
眾所周知OpenAI 的API 無法聯網的,所以如果只使用自己的功能實現聯網搜索並給出回答、總結PDF 文檔、基於某個Youtube 視頻進行問答等等的功能肯定是無法實現的。所以,我們來介紹一個非常強大的第三方開源庫: LangChain 。
文檔地址:https://python.langchain.com/en/latest/
這個庫目前非常活躍,每天都在迭代,已經有22k 的star,更新速度飛快。
LangChain 是一個用於開發由語言模型驅動的應用程序的框架。他主要擁有2 個能力:
LLM 模型:Large Language Model,大型語言模型
LLM 調用
Prompt管理,支持各種自定義模板
擁有大量的文檔加載器,比如Email、Markdown、PDF、Youtube ...
對索引的支持
Chains
相信大家看完上面的介紹多半會一臉懵逼。不要擔心,上面的概念其實在剛開始學的時候不是很重要,當我們講完後面的例子之後,在回來看上面的內容會一下明白很多。
但是,這裡有幾個概念是必須知道的。
顧名思義,這個就是從指定源進行加載數據的。比如:文件夾DirectoryLoader 、Azure 存儲AzureBlobStorageContainerLoader 、CSV文件CSVLoader 、印象筆記EverNoteLoader 、Google網盤GoogleDriveLoader 、任意的網頁UnstructuredHTMLLoader 、PDF PyPDFLoader 、S3 S3DirectoryLoader / S3FileLoader 、
Youtube YoutubeLoader等等,上面只是簡單的進行列舉了幾個,官方提供了超級的多的加載器供你使用。
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
當使用loader加載器讀取到數據源後,數據源需要轉換成Document 對像後,後續才能進行使用。
顧名思義,文本分割就是用來分割文本的。為什麼需要分割文本?因為我們每次不管是做把文本當作prompt 發給openai api ,還是還是使用openai api embedding 功能都是有字符限制的。
比如我們將一份300頁的pdf 發給openai api,讓他進行總結,他肯定會報超過最大Token 錯。所以這裡就需要使用文本分割器去分割我們loader 進來的Document。
因為數據相關性搜索其實是向量運算。所以,不管我們是使用openai api embedding 功能還是直接通過向量數據庫直接查詢,都需要將我們的加載進來的數據Document進行向量化,才能進行向量運算搜索。轉換成向量也很簡單,只需要我們把數據存儲到對應的向量數據庫中即可完成向量的轉換。
官方也提供了很多的向量數據庫供我們使用。
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
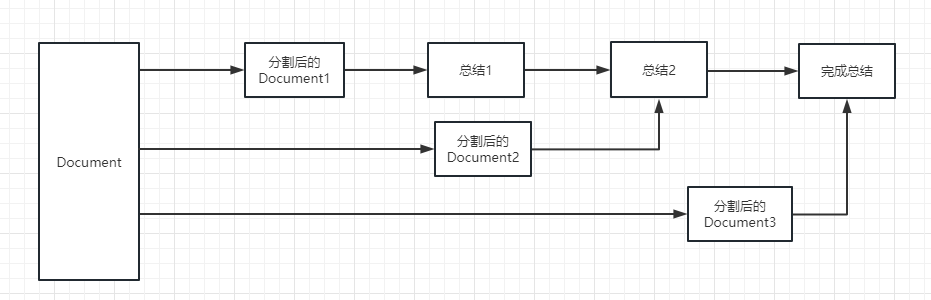
我們可以把Chain 理解為任務。一個Chain 就是一個任務,當然也可以像鏈條一樣,一個一個的執行多個鏈。
我們可以簡單的理解為他可以動態的幫我們選擇和調用chain或者已有的工具。
執行過程可以參考下面這張圖:
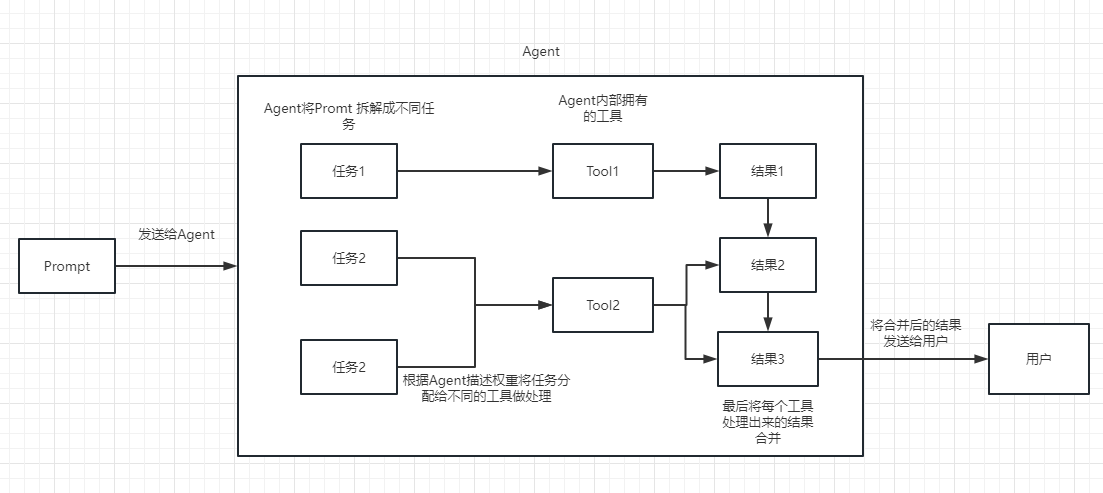
用於衡量文本的相關性。這個也是OpenAI API 能實現構建自己知識庫的關鍵所在。
他相比fine-tuning 最大的優勢就是,不用進行訓練,並且可以實時添加新的內容,而不用加一次新的內容就訓練一次,並且各方面成本要比fine-tuning 低很多。
具體比較和選擇可以參考這個視頻:https://www.youtube.com/watch?v=9qq6HTr7Ocw
通過上面的必備概念大家應該已經可以對LangChain 有了一定的了解,但是可能還有有些懵。
這都是小問題,我相信看完後面的實戰,你們就會徹底的理解上面的內容,並且能感受到這個庫的真正強大之處。
因為我們OpenAI API 進階,所以我們後面的範例使用的LLM 都是以Open AI 為例,後面大家可以根據自己任務的需要換成自己需要的LLM 模型即可。
當然,在這篇文章的末尾,全部的全部代碼都會被保存為一個colab 的ipynb 文件提供給大家來學習。
建議大家按順序去看每個例子,因為下一個例子會用到上一個例子裡面的知識點。
當然,如果有看不懂的也不用擔心,可以繼續往後看,第一次學習講究的是不求甚解。
第一個案例,我們就來個最簡單的,用LangChain 加載OpenAI 的模型,並且完成一次問答。
在開始之前,我們需要先設置我們的openai 的key,這個key 可以在用戶管理裡面創建,這裡就不細說了。
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'然後,我們進行導入和執行
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
這時,我們就可以看到他給我們的返回結果了,怎麼樣,是不是很簡單。
接下來,我們就來搞點有意思的。我們來讓我們的OpenAI api 聯網搜索,並返回答案給我們。
這裡我們需要藉助Serpapi 來進行實現,Serpapi 提供了google 搜索的api 接口。
首先需要我們到Serpapi 官網上註冊一個用戶,https://serpapi.com/ 並複制他給我們生成api key。
然後我們需要像上面的openai api key 一樣設置到環境變量裡面去。
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'然後,開始編寫我的代碼
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )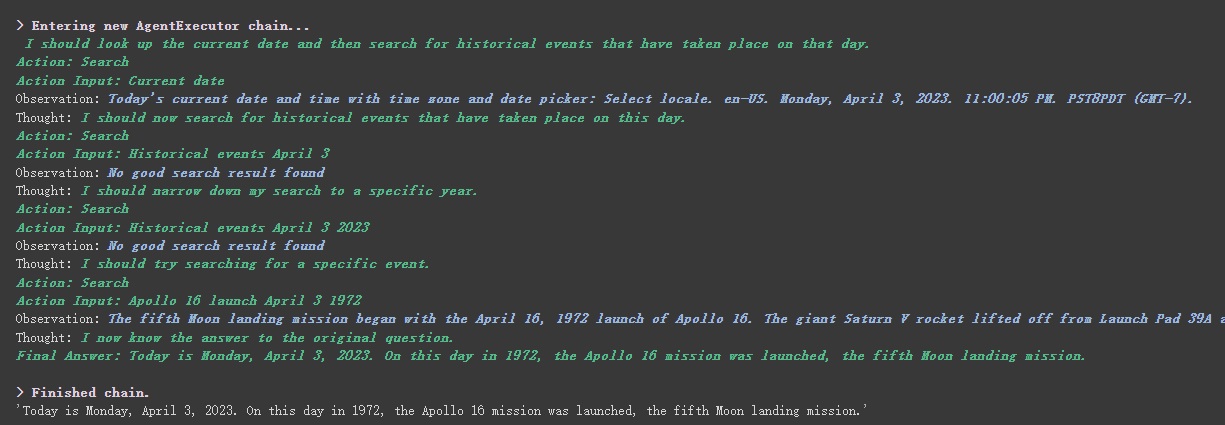
我們可以看到,他正確的返回了日期(有時差),並且返回了歷史上的今天。
在chain 和agent 對像上都會有verbose這個參數,這個是個非常有用的參數,開啟他後我們可以看到完整的chain 執行過程。
可以在上面返回的結果看到,他將我們的問題拆分成了幾個步驟,然後一步一步得到最終的答案。
關於agent type 幾個選項的含義(理解不了也不會影響下面的學習,用多了自然理解了):
Search和Lookup工具, 前者用來搜, 後者尋找term, 舉例: Wipipedia工具Google search API工具reAct 介紹可以看這個:https://arxiv.org/pdf/2210.03629.pdf
LLM 的ReAct 模式的Python 實現: https://til.simonwillison.net/llms/python-react-pattern
agent type 官方解釋:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-description
有一點要說明的是,這個
serpapi貌似對中文不是很友好,所以提問的prompt 建議使用英文。
當然,官方已經寫好了ChatGPT Plugins的agent,未來chatgpt 能用啥插件,我們在api 裡面也能用插件,想想都美滋滋。
不過目前只能使用不用授權的插件,期待未來官方解決這個。
感興趣的可以看這個文檔:https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Chatgpt 只能給官方賺錢,而Openai API 能給我賺錢
假如我們想要用openai api 對一個段文本進行總結,我們通常的做法就是直接發給api 讓他總結。但是如果文本超過了api 最大的token 限制就會報錯。
這時,我們一般會進行對文章進行分段,比如通過tiktoken 計算並分割,然後將各段發送給api 進行總結,最後將各段的總結再進行一個全部的總結。
如果,你用是LangChain,他很好的幫我們處理了這個過程,使得我們編寫代碼變的非常簡單。
廢話不多說,直接上代碼。
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
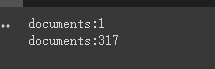
chain . run ( split_documents [: 5 ])首先我們對切割前和切割後的document 個數進行了打印,我們可以看到,切割前就是只有整篇的一個document,切割完成後,會把上面一個document 切成317 個document。
最終輸出了對前5 個document 的總結。

這裡有幾個參數需要注意:
文本分割器的chunk_overlap參數
這個是指切割後的每個document 裡包含幾個上一個document 結尾的內容,主要作用是為了增加每個document 的上下文關聯。比如, chunk_overlap=0時, 第一個document 為aaaaaa,第二個為bbbbbb;當chunk_overlap=2時,第一個document 為aaaaaa,第二個為aabbbbbb。
不過,這個也不是絕對的,要看所使用的那個文本分割模型內部的具體算法。
文本分割器可以參考這個文檔:https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
chain 的chain_type參數
這個參數主要控制了將document 傳遞給llm 模型的方式,一共有4 種方式:
stuff : 這種最簡單粗暴,會把所有的document 一次全部傳給llm 模型進行總結。如果document很多的話,勢必會報超出最大token 限制的錯,所以總結文本的時候一般不會選中這個。
map_reduce : 這個方式會先將每個document 進行總結,最後將所有document 總結出的結果再進行一次總結。
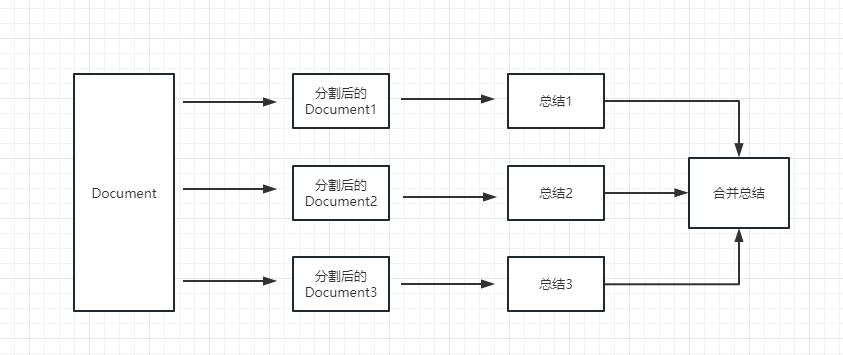
refine : 這種方式會先總結第一個document,然後在將第一個document 總結出的內容和第二個document 一起發給llm 模型在進行總結,以此類推。這種方式的好處就是在總結後一個document 的時候,會帶著前一個的document 進行總結,給需要總結的document 添加了上下文,增加了總結內容的連貫性。
map_rerank : 這種一般不會用在總結的chain 上,而是會用在問答的chain 上,他其實是一種搜索答案的匹配方式。首先你要給出一個問題,他會根據問題給每個document 計算一個這個document 能回答這個問題的概率分數,然後找到分數最高的那個document ,在通過把這個document 轉化為問題的prompt 的一部分(問題+document)發送給llm 模型,最後llm 模型返回具體答案。
在這個例子中,我們會介紹如何從我們本地讀取多個文檔構建知識庫,並且使用Openai API 在知識庫中進行搜索並給出答案。
這個是個很有用的教程,比如可以很方便的做一個可以介紹公司業務的機器人,或是介紹一個產品的機器人。
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )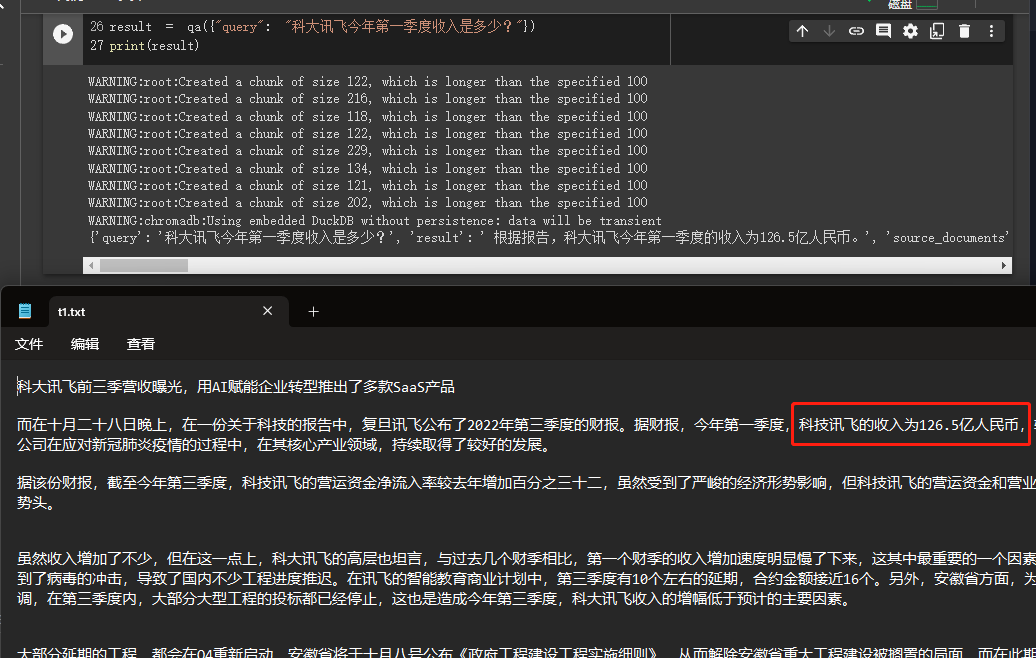
我們可以通過結果看到,他成功的從我們的給到的數據中獲取了正確的答案。
關於Openai embeddings 詳細資料可以參看這個連接: https://platform.openai.com/docs/guides/embeddings
我們上個案例裡面有一步是將document 信息轉換成向量信息和embeddings的信息並臨時存入Chroma 數據庫。
因為是臨時存入,所以當我們上面的代碼執行完成後,上面的向量化後的數據將會丟失。如果想下次使用,那麼就還需要再計算一次embeddings,這肯定不是我們想要的。
那麼,這個案例我們就來通過Chroma 和Pinecone 這兩個數據庫來講一下如何做向量數據持久化。
因為LangChain 支持的數據庫有很多,所以這裡就介紹兩個用的比較多的,更多的可以參看文檔:https://python.langchain.com/en/latest/modules/indexes/vectorstores/getting_started.html
Chroma
chroma 是個本地的向量數據庫,他提供的一個persist_directory來設置持久化目錄進行持久化。讀取時,只需要調取from_document方法加載即可。
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )Pinecone
Pinecone 是一個在線的向量數據庫。所以,我可以第一步依舊是註冊,然後拿到對應的api key。 https://app.pinecone.io/
免費版如果索引14天不使用會被自動清除。
然後創建我們的數據庫:
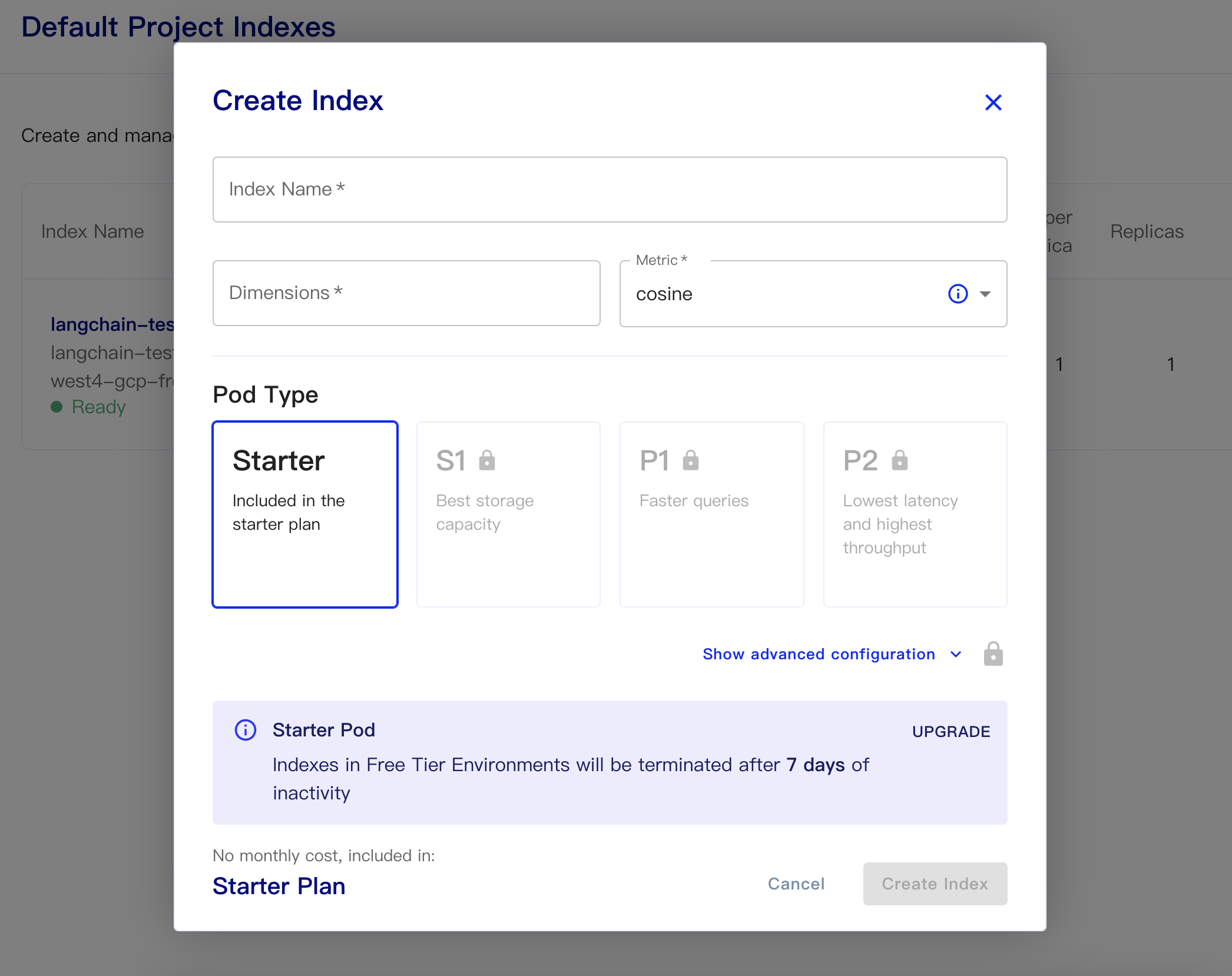
Index Name:這個隨意
Dimensions:OpenAI 的text-embedding-ada-002 模型為OUTPUT DIMENSIONS 為1536,所以我們這裡填1536
Metric:可以默認為cosine
選擇starter plan
持久化數據和加載數據代碼如下
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )一個簡單從數據庫獲取embeddings,並回答的代碼如下
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
在chatgpt api(也就是GPT-3.5-Turbo)模型出來後,因錢少活好深受大家喜愛,所以LangChain 也加入了專屬的鍊和模型,我們來跟著這個例子看下如何使用他。
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])我們可以看到他能很準確的圍繞這個油管視頻進行問答

使用流式回答也很方便
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ())我們主要是結合使用zapier來實現將萬種工具連接起來。
所以我們第一步依舊是需要申請賬號和他的自然語言api key。 https://zapier.com/l/natural-language-actions
他的api key 雖然需要填寫信息申請。但是基本填入信息後,基本可以秒在郵箱裡看到審核通過的郵件。
然後,我們通過右鍵裡面的連接打開我們的api 配置頁面。我們點擊右側的Manage Actions來配置我們要使用哪些應用。
我在這裡配置了Gmail 讀取和發郵件的action,並且所有字段都選的是通過AI 猜。
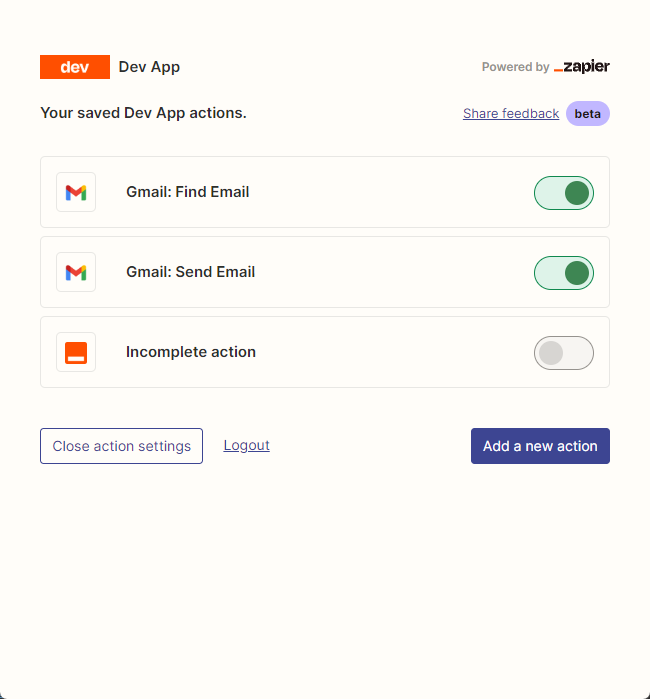
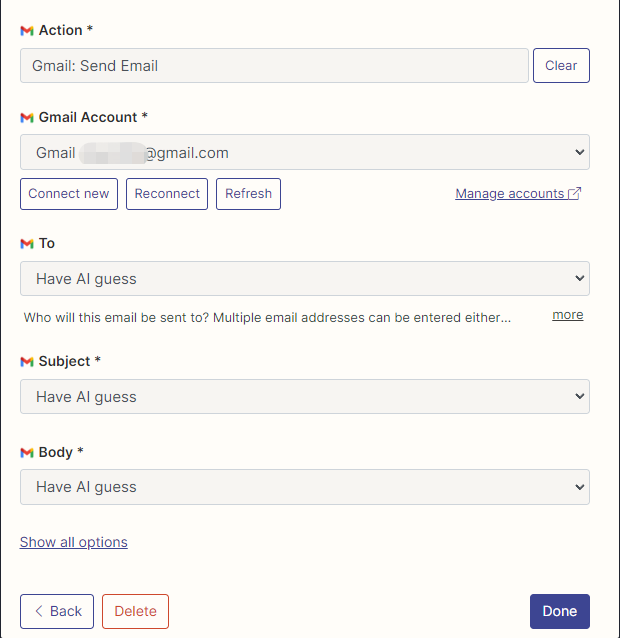
配置好後,我們開始寫代碼
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
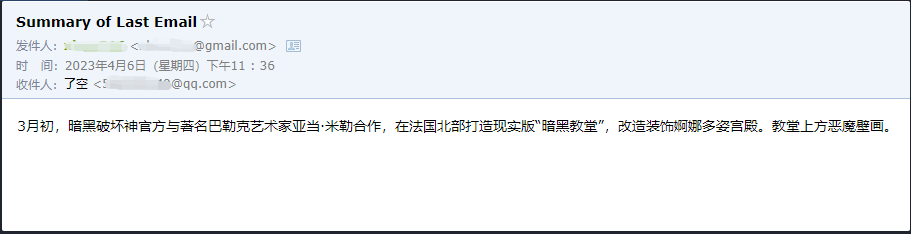
我們可以看到他成功讀取了******@qq.com給他發送的最後一封郵件,並將總結的內容又發送給了******@qq.com
這是我發送給Gmail 的郵件。

這是他發送給QQ 郵箱的郵件。
這只是個小例子,因為zapier有數以千計的應用,所以我們可以輕鬆結合openai api 搭建自己的工作流。
一些比較大的知識點都已經講完了,後面的內容都是一些比較有趣的小例子,當作拓展延伸。
因為他是鍊式的,所以他也可以按順序依次去執行多個chain
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )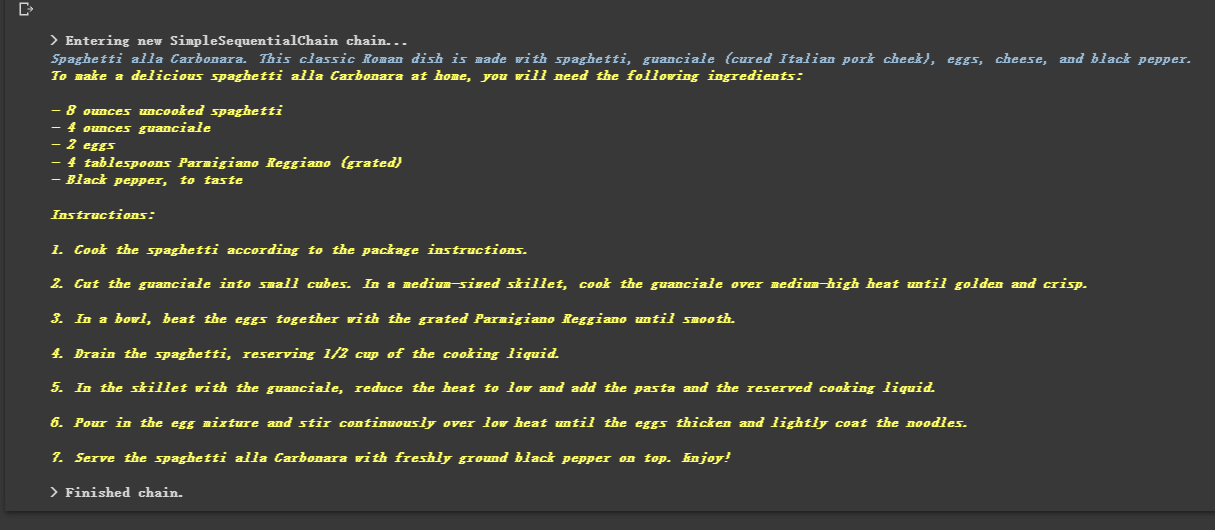
有時候我們希望輸出的內容不是文本,而是像json 那樣結構化的數據。
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
有些時候我們需要爬取一些結構性比較強的網頁,並且需要將網頁中的信息以JSON的方式返回回來。
我們就可以使用LLMRequestsChain類去實現,具體可以參考下面代碼
為了方便理解,我在例子中直接使用了Prompt的方法去格式化輸出結果,而沒用使用上個案例中用到的
StructuredOutputParser去格式化,也算是提供了另外一種格式化的思路
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])我們可以看到,他很好的將格式化後的結果輸出了出來

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )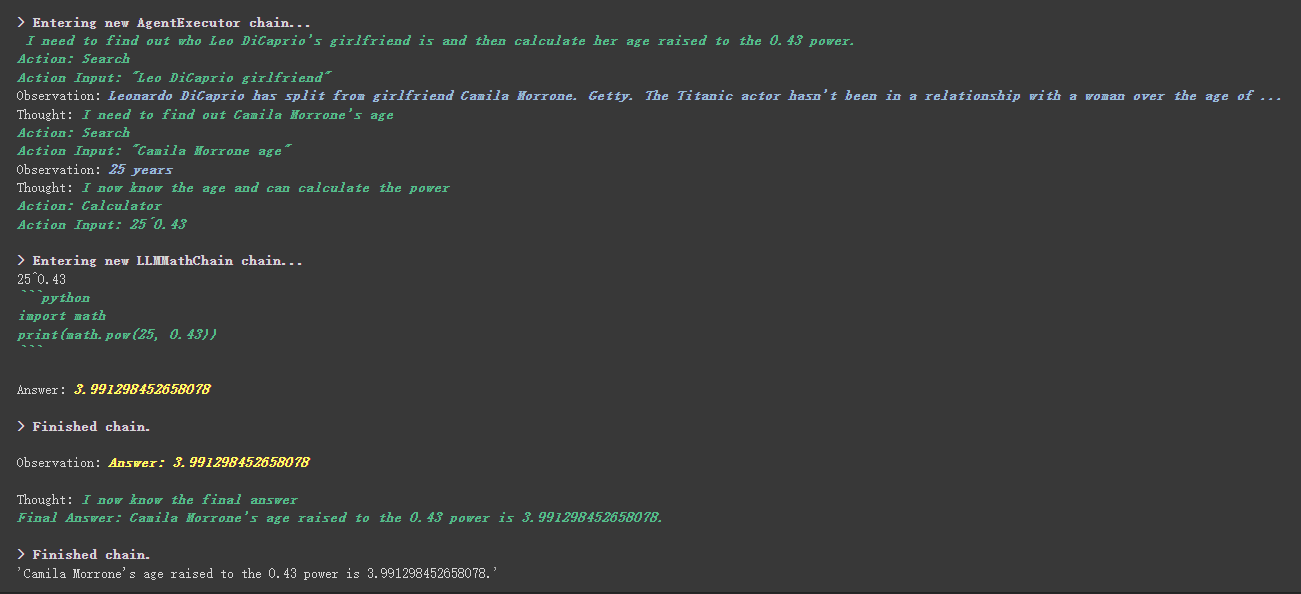
自定義工具裡面有個比較有意思的地方,使用哪個工具的權重是靠工具中描述内容來實現的,和我們之前編程靠數值來控制權重完全不同。
比如Calculator 在描述裡面寫到,如果你問關於數學的問題就用他這個工具。我們就可以在上面的執行過程中看到,他在我們請求的prompt 中數學的部分,就選用了Calculator 這個工具進行計算。
上一個例子我們使用的是通過自定義一個列表來存儲對話的方式來保存歷史的。
當然,你也可以使用自帶的memory 對象來實現這一點。
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )使用Hugging Face 模型之前,需要先設置環境變量
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''使用在線的Hugging Face 模型
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))將Hugging Face 模型直接拉到本地使用
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))將模型拉到本地使用的好處:
我們通過SQLDatabaseToolkit或者SQLDatabaseChain都可以實現執行SQL命令的操作
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )這裡可以參考這兩篇文檔:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
所有的案例都基本已經結束了,希望大家能通過這篇文章的學習有所收穫。這篇文章只是對LangChain 一個初級的講解,高級的功能希望大家繼續探索。
並且因為LangChain 迭代極快,所以後面肯定會隨著AI繼續的發展,還會迭代出更好用的功能,所以我非常看好這個開源庫。
希望大家能結合LangChain 開發出更有創意的產品,而不僅僅只搞一堆各種一鍵搭建chatgpt聊天客戶端的那種產品。
這篇標題後面加了個01是我希望這篇文章只是一個開始,後面如何出現了更好的技術我還是希望能繼續更新下去這個系列。
本文章的所有範例代碼都在這裡,祝大家學習愉快。
https://colab.research.google.com/drive/1ArRVMiS-YkhUlobHrU6BeS8fF57UeaPQ?usp=sharing


