LangChain Chinese Getting Started Guide
1.0.0
Pour une lecture facile, des gitbooks ont été générés: https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
Adresse GitHub: https://github.com/liaokongvfx/langchain-chinese-getting-started-guide
"Le décryptage de la technologie de Langchain: un guide panoramique pour construire des applications de grandes modèles" a été publié maintenant: https://item.jd.com/14598210.html
Transfert API du modèle AI intérieur et étranger à bas prix: https://api.91ai.me
Parce que la bibliothèque de Langchain a été rapidement mise à jour et itérant, mais le document est rédigé début avril, et j'ai une énergie personnelle limitée, donc le code de Colab peut être quelque peu dépassé. S'il y a un échec en fonctionnement, vous pouvez d'abord rechercher si le document actuel a été mis à jour.
J'ai ajouté un Changelog et mis à jour le nouveau contenu.
Si vous souhaitez modifier l'itinéraire racine de demande de l'API OpenAI vers votre propre adresse proxy, vous pouvez le modifier en définissant la variable d'environnement "OpenAI_API_BASE".
Code de référence associé: https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#l48
Ou lors de l'initialisation des objets du modèle lié à OpenAI, transmettez la variable "OpenAI_API_BASE".
Code de référence associé: https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
Comme nous le savons tous, l'API d'Openai ne peut pas être connectée à Internet, il est donc certainement impossible d'utiliser ses propres fonctions pour rechercher et donner des réponses, résumer les documents PDF et effectuer des questions et réponses basées sur une vidéo YouTube. Alors, introduisons une bibliothèque open source tierce très puissante: LangChain .
Adresse du document: https://python.langchain.com/en/latest/
Cette bibliothèque est actuellement très active et itère chaque jour.
Langchain est un cadre pour développer des applications alimentées par des modèles de langue. Il a 2 capacités principales:
Modèle LLM: modèle de grande langue, modèle grand langage
Appel LLM
Gestion rapide, prend en charge divers modèles personnalisés
Il a un grand nombre de chargeurs de documents, tels que les e-mails, Markdown, PDF, YouTube ...
Prise en charge des index
Chaînes
Je crois que tout le monde sera confus après avoir lu l'introduction ci-dessus. Ne vous inquiétez pas, le concept ci-dessus n'est en fait pas très important lorsque nous avons commencé à apprendre.
Cependant, voici plusieurs concepts qui doivent être connus.
Comme son nom l'indique, il s'agit de charger des données à partir d'une source spécifiée. Par exemple: Roder DirectoryLoader , Azure Storage AzureBlobStorageContainerLoader , fichier CSV CSVLoader , Evernote EverNoteLoader , Google GoogleDriveLoader , n'importe quelle page Web UnstructuredHTMLLoader / PyPDFLoader , S3 S3DirectoryLoader / S3FileLoader ,
YouTube YoutubeLoader , etc., j'en ai brièvement répertorié quelques-uns.
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
Après avoir lu la source de données à l'aide du chargeur de chargeur, la source de données doit être convertie en un objet de document avant de pouvoir être utilisé plus tard.
Comme son nom l'indique, la segmentation du texte est utilisée pour diviser le texte. Pourquoi avez-vous besoin de diviser du texte? Étant donné que chaque fois que nous envoyons du texte sous forme de propt à l'API OpenAI ou utilisons la fonction d'intégration de l'API OpenAI, il existe des restrictions de caractère.
Par exemple, si nous envoyons un PDF de 300 pages à l'API OpenAI et lui demandons de résumer, il rapportera certainement une erreur qui dépasse le jeton maximal. Ici, nous devons donc utiliser un séparateur de texte pour diviser le document dans lequel notre chargeur entre.
Parce que la recherche de corrélation des données est en fait une opération vectorielle. Par conséquent, que nous utilisons la fonction d'intégration de l'API OpenAI ou que nous remercions directement la base de données vectorielle, nous devons vectoriser notre Document de données chargé afin d'effectuer la recherche de l'opération vectorielle. La conversion en vecteur est également très simple.
Le responsable fournit également de nombreuses bases de données vectorielles à utiliser.
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
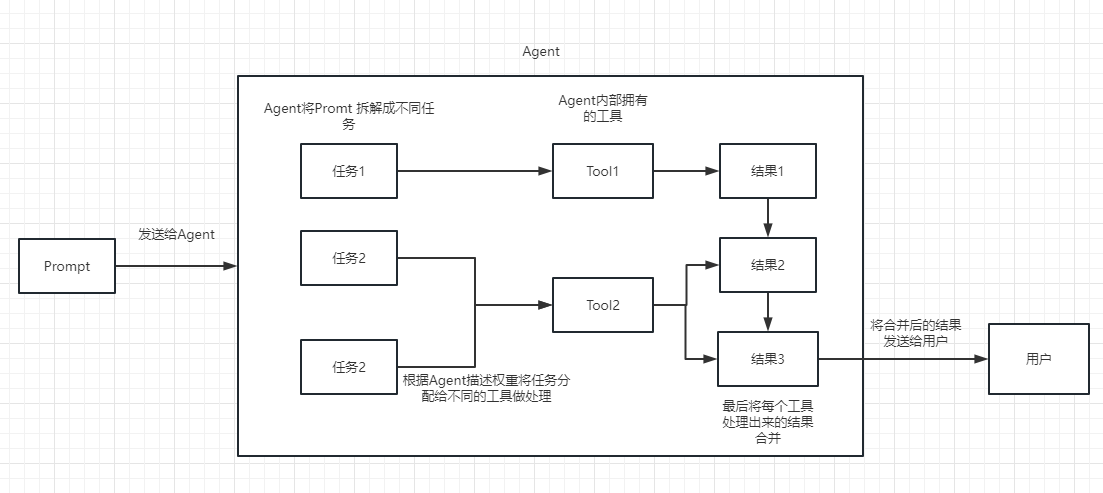
Nous pouvons comprendre la chaîne comme une tâche. Une chaîne est une tâche, et bien sûr, il peut également exécuter plusieurs chaînes une par une comme une chaîne.
Nous pouvons simplement comprendre qu'il peut nous aider dynamiquement à choisir et à appeler la chaîne ou les outils existants.
Pour le processus d'exécution, veuillez vous référer à l'image suivante:
Utilisé pour mesurer la pertinence du texte. C'est également la clé de la capacité de l'API OpenAI à construire sa propre base de connaissances.
Son plus grand avantage sur le réglage fin est qu'il n'a pas besoin de s'entraîner et peut ajouter de nouveaux contenus en temps réel, au lieu d'ajouter un nouveau contenu une fois, et le coût dans tous les aspects est beaucoup plus bas que le réglage fin.
Pour des comparaisons et des sélections spécifiques, veuillez vous référer à cette vidéo: https://www.youtube.com/watch?v=9qq6htr7ocw
Grâce aux concepts essentiels ci-dessus, vous devriez avoir une certaine compréhension de Langchain, mais vous pouvez toujours être un peu confus.
Ce sont toutes de petites questions.
Parce que notre API OpenAI est avancée, le LLM utilisé dans nos exemples suivants est tous basés sur une IA ouverte comme exemple.
Bien sûr, à la fin de cet article, tout le code sera enregistré en tant que fichier Colab Ipynb et fourni à tout le monde.
Il est recommandé de regarder chaque exemple dans l'ordre, car l'exemple suivant utilisera les points de connaissance de l'exemple précédent.
Bien sûr, si vous ne comprenez pas quelque chose, ne vous inquiétez pas.
Dans le premier cas, nous utiliserons Langchain pour charger le modèle OpenAI et compléter une Q&R.
Avant de commencer, nous devons d'abord configurer notre clé OpenAI.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'Ensuite, nous importons et exécutons
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
En ce moment, nous pouvons voir le résultat qu'il nous a donné.
Ensuite, faisons quelque chose d'intéressant. Amettons notre API Openai pour rechercher en ligne et nous retourner les réponses.
Ici, nous devons utiliser SERPAPI pour l'implémenter, qui fournit une interface API pour Google Search.
Tout d'abord, nous devons enregistrer un utilisateur sur le site officiel de SERPAPI, https://serpapi.com/ et le copier pour générer la clé API pour nous.
Ensuite, nous devons le régler dans la variable d'environnement comme la touche API OpenAI ci-dessus.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'Ensuite, commencez à écrire mon code
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )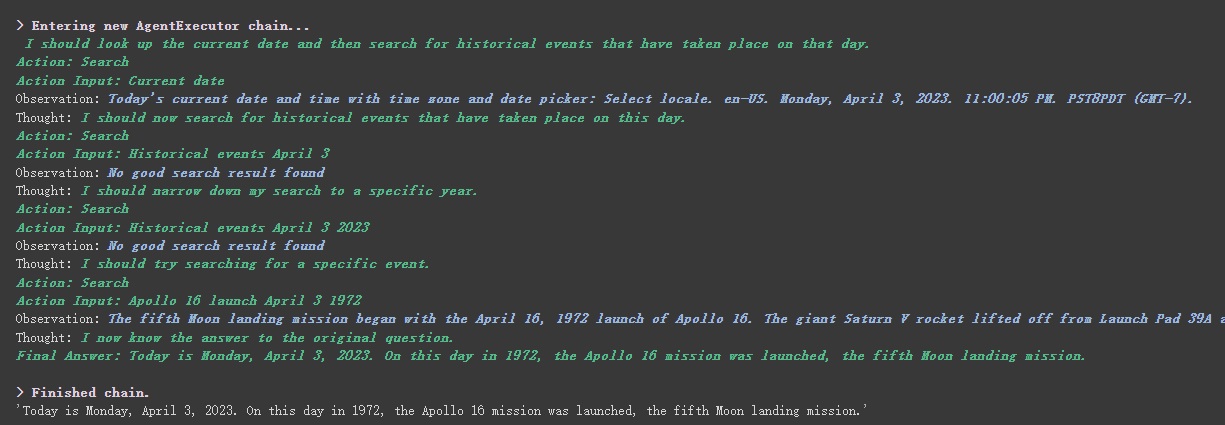
Nous pouvons voir qu'il a correctement retourné la date (parfois la différence) et est retourné aujourd'hui dans l'histoire.
Il y a le paramètre verbose sur les objets de chaîne et d'agent.
Comme vous pouvez le voir à partir du résultat renvoyé ci-dessus, il divise notre question en plusieurs étapes, puis obtient la réponse finale étape par étape.
En ce qui concerne la signification de plusieurs options pour le type d'agent (si vous ne pouvez pas le comprendre, cela n'affectera pas l'apprentissage suivant. Si vous l'utilisez trop, vous le comprendrez naturellement):
Search et Lookup , le premier est utilisé pour rechercher, et le second est utilisé pour trouver le terme, par exemple: l'outil WipipediaGoogle search APIVous pouvez le voir pour React Introduction: https://arxiv.org/pdf/2210.03629.pdf
Python Implémentation du modèle de réact de LLM: https://til.simonwillison.net/llms/python-react-pattern
Explication officielle de type d'agent:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-description
Une chose à noter est que ce
serpapine semble pas très amical avec le chinois, donc l'invite demandée est recommandée d'utiliser l'anglais.
Bien sûr, le fonctionnaire a écrit l'agent des ChatGPT Plugins .
Cependant, à l'heure actuelle, seuls les plug-ins qui ne nécessitent pas d'autorisation peuvent être utilisés.
Ceux qui sont intéressés peuvent lire ce document: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Chatgpt ne peut gagner de l'argent que pour l'API officiel, et Openai API peut gagner de l'argent pour moi
Si nous voulons utiliser l'API OpenAI pour résumer un paragraphe de texte, notre moyen habituel est de l'envoyer directement à l'API pour qu'il résume. Cependant, si le texte dépasse la limite de jeton maximale de l'API, une erreur sera signalée.
À l'heure actuelle, nous segmulons généralement l'article, tel que le calculer et le diviser via Tiktoken, puis envoyer chaque paragraphe à l'API pour résumé, et enfin résumer le résumé de chaque paragraphe.
Si vous utilisez Langchain, il nous a très bien aidés à gérer ce processus, ce qui nous permet d'écrire du code.
Sans plus tarder, téléchargez simplement le code.
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
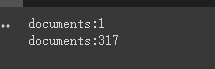
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])Tout d'abord, nous imprimons le nombre de documents avant et après la coupe.
Enfin, un résumé des 5 premiers documents est la sortie.

Voici quelques paramètres à noter:
Le paramètre chunk_overlap du séparateur de texte
Cela fait référence au contenu se terminant par plusieurs documents précédents dans chaque document après la coupe. Par chunk_overlap=2 , lorsque chunk_overlap=0 , le premier document est aaaaaaa, le second est BBBBBB;
Cependant, ce n'est pas absolu, cela dépend de l'algorithme spécifique à l'intérieur du modèle de segmentation de texte utilisé.
Vous pouvez vous référer à ce document pour les séparateurs de texte: https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
paramètre chain_type de la chaîne
Ce paramètre contrôle principalement la façon dont le document est transmis au modèle LLM, et il y a 4 façons au total:
stuff : c'est le plus simple et le plus brut, et passera tous les documents au modèle LLM à la fois pour le résumé. S'il existe de nombreux documents, il rapportera inévitablement une erreur qui dépasse la limite de jeton maximale, donc ce n'est généralement pas sélectionné lors de la résumé du texte.
map_reduce : cette méthode résumera d'abord chaque document et résumera enfin les résultats résumés par tous les documents.
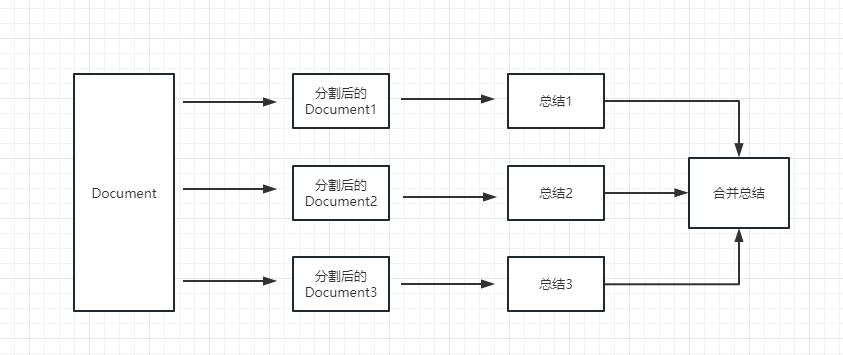
refine : cette méthode résumera d'abord le premier document, puis envoie le contenu résumé par le premier document et le deuxième document au modèle LLM pour le résumé, etc. L'avantage de cette méthode est que lors du résumé de ce dernier document, il faudra le document précédent pour résumer, ajouter un contexte au document qui doit être résumé et augmenter la cohérence du contenu sommaire.
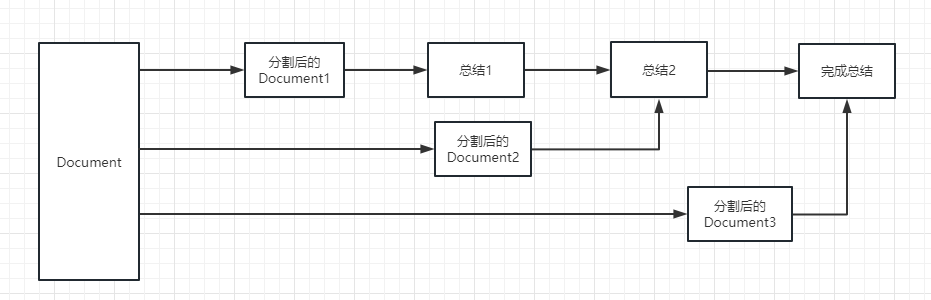
map_rerank : Ce type de chaîne n'est généralement pas utilisé en résumé, mais dans la chaîne de questions et de réponses. Tout d'abord, vous devez donner une question.
Dans cet exemple, nous expliquerons comment construire une base de connaissances en lisant plusieurs documents de nous localement et utiliser l'API OpenAI pour rechercher et donner des réponses dans la base de connaissances.
Il s'agit d'un tutoriel très utile, comme un robot qui peut facilement introduire l'entreprise de l'entreprise ou un robot qui introduit un produit.
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )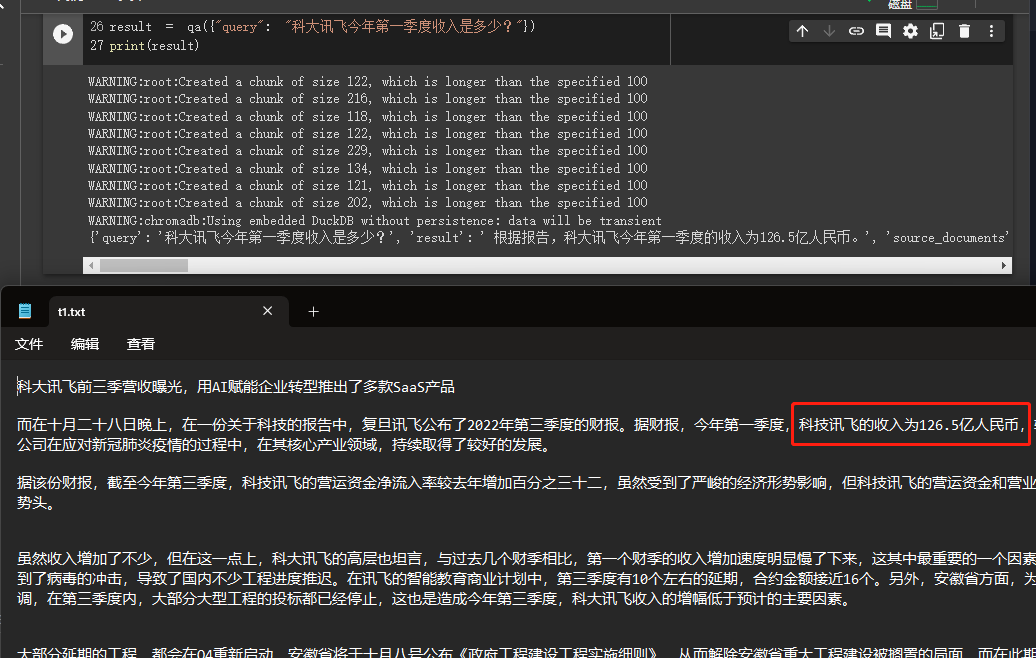
Nous pouvons voir à travers les résultats qu'il a obtenu avec succès la bonne réponse des données que nous avons données.
Pour plus de détails sur Openai Embeddings, veuillez vous référer à ce lien: https://platform.openai.com/docs/guides/embedings
Une étape de notre cas précédent a été de convertir les informations sur le document en informations vectorielles et intégrer des informations et de les stocker temporairement dans la base de données Chroma.
Parce qu'il est temporairement stocké, lorsque le code ci-dessus est exécuté, les données après la vectorisation ci-dessus seront perdues. Si vous souhaitez l'utiliser la prochaine fois, vous devez à nouveau calculer les intégres, ce qui n'est certainement pas ce que nous voulons.
Ainsi, dans ce cas, nous parlerons de la façon de persister les données vectorielles à travers les deux bases de données de chroma et de pinone.
Parce que Langchain prend en charge de nombreuses bases de données, en voici deux qui sont utilisées plus fréquemment.
Chrome
Le chroma est une base de données vectorielle locale, qui fournit un persist_directory pour définir le répertoire persistant de persistance. Lors de la lecture, il vous suffit d'appeler la méthode from_document à charger.
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )Pignon
PineCone est une base de données vectorielle en ligne. Ainsi, la première étape que je peux encore m'inscrire et obtenir la clé API correspondante. https://app.pinecone.io/
La version gratuite sera automatiquement effacée si l'index n'est pas utilisé pendant 14 jours.
Créez ensuite notre base de données:
Nom d'index: c'est décontracté
Dimensions: le modèle Text-Embedding-ADA-002 d'Openai est de sortie les dimensions est de 1536, donc nous remplissons 1536 ici
Métrique: peut-on par défaut au cosinus
Sélectionnez le plan de démarrage
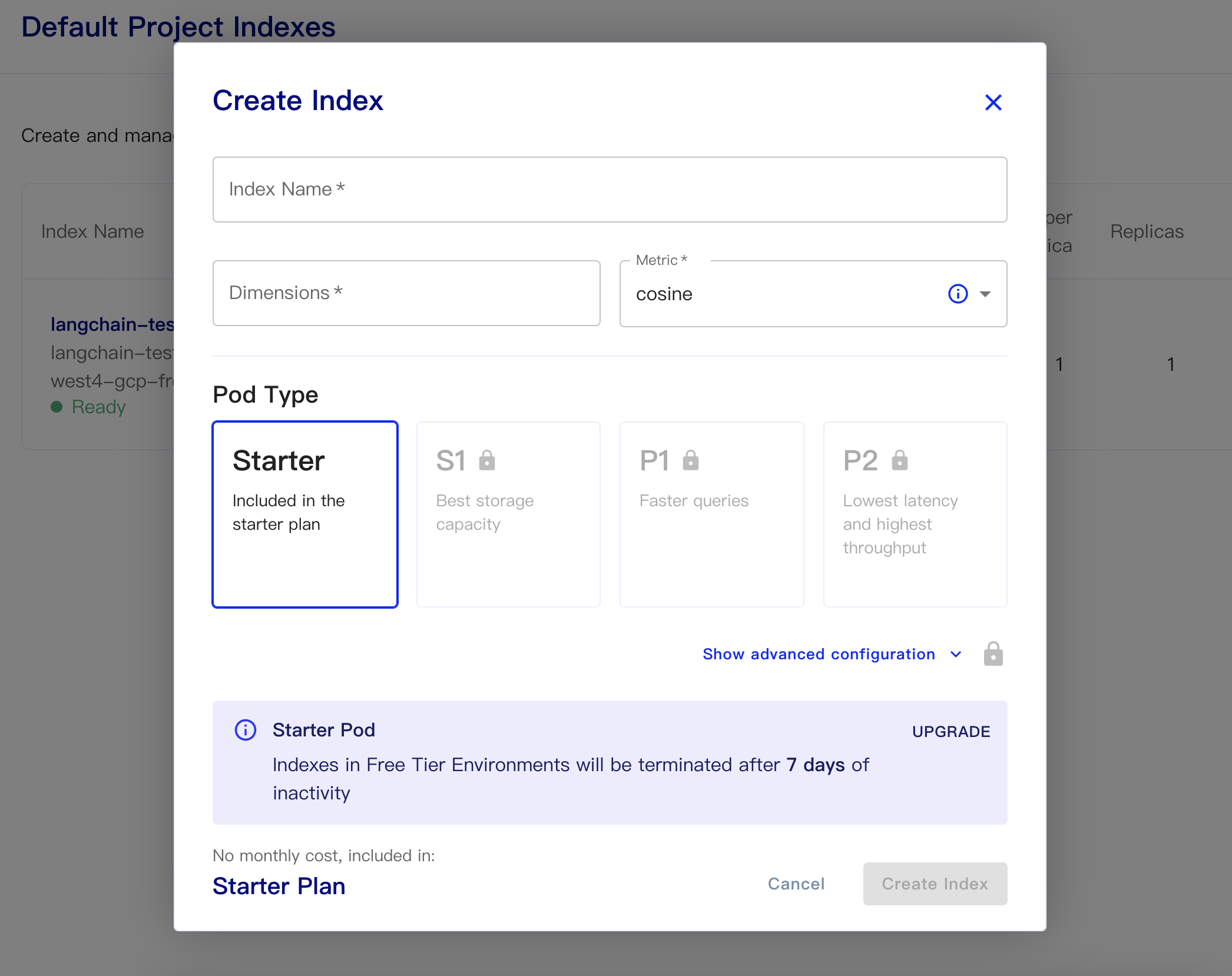
Les données persistantes et les codes de données de chargement sont les suivantes
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )Un code simple pour obtenir des intégres à partir de la base de données et répondre est comme suit
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
Après la publication de l'API ChatGPT (c'est-à-dire GPT-3.5-Turbo), elle a été aimée par tout le monde parce que c'était moins d'argent, donc Langchain a également ajouté des chaînes et des modèles exclusifs.
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])Nous pouvons voir qu'il peut répondre avec précision aux questions et réponses autour de cette vidéo de tuyau d'huile

Les réponses en streaming sont également très pratiques
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) Nous utilisons principalement zapier pour connecter des milliers d'outils.
Notre première étape consiste donc à demander un compte et sa clé API en langage naturel. https://zapier.com/l/natural-language-actions
Sa clé API doit remplir la demande d'information. Cependant, après avoir essentiellement rempli les informations, vous pouvez essentiellement voir l'e-mail approuvé dans l'adresse e-mail en quelques secondes.
Ensuite, nous ouvrons notre page de configuration de l'API en cliquant avec le bouton droit sur la connexion. Nous cliquez sur Manage Actions à droite pour configurer les applications que nous souhaitons utiliser.
J'ai configuré les actions de Gmail pour lire et envoyer des e-mails ici, et tous les champs sont sélectionnés par devinettes d'IA.
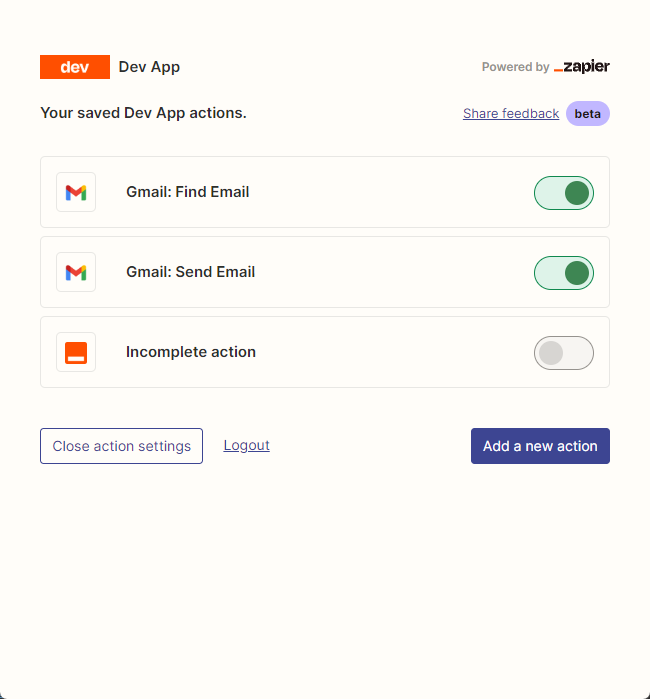
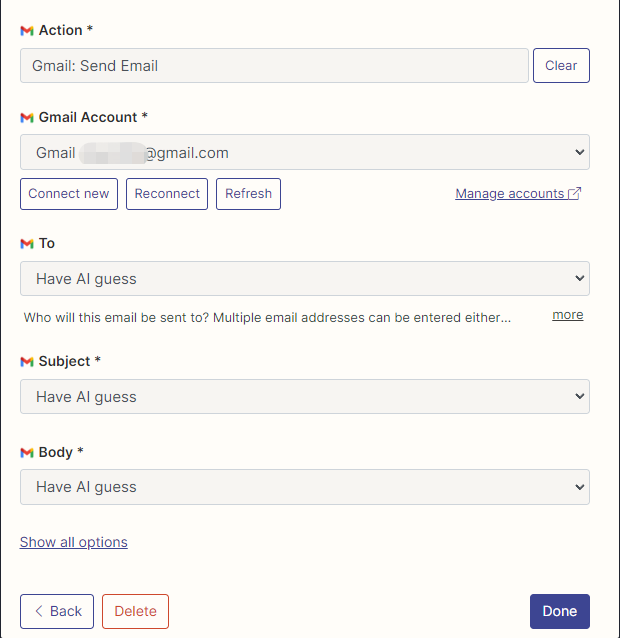
Une fois la configuration terminée, nous commençons à écrire du code
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
Nous pouvons voir qu'il a lu avec succès le dernier e-mail qui lui a été envoyé par ******@qq.com et a envoyé le contenu résumé à ******@qq.com .
Ceci est l'e-mail que j'ai envoyé à Gmail.

Ceci est l'e-mail qu'il a envoyé à son e-mail QQ.
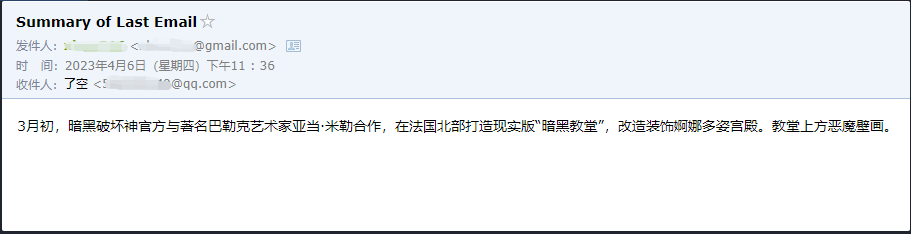
Ce n'est qu'un petit exemple, car zapier a des milliers d'applications, nous pouvons donc facilement construire nos propres flux de travail avec l'API OpenAI.
Certains des points de connaissance plus importants ont été expliqués, et le contenu suivant concerne quelques petits exemples intéressants, comme extensions.
Parce qu'il est enchaîné, il peut également exécuter plusieurs chaînes en séquence.
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )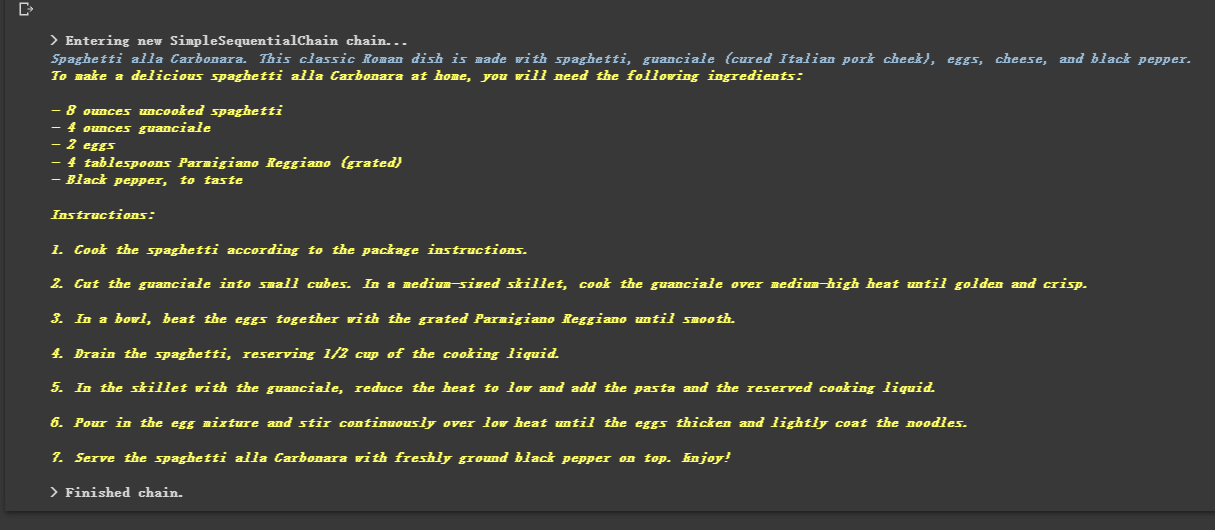
Parfois, nous voulons que la sortie ne soit pas du texte, mais des données structurées comme JSON.
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
Parfois, nous avons besoin de ramper Structure plus forte et les informations de la page Web doivent être renvoyées en mode JSON.
Nous pouvons utiliser la classe LLMRequestsChain pour l'implémenter.
Dans un souci de compréhension facile, j'ai directement utilisé la méthode invite pour formater les résultats de sortie dans l'exemple, mais je n'ai pas utilisé
StructuredOutputParserutilisé dans le cas précédent pour le formater, qui peut également être considéré comme fournissant une autre idée de formatage.
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])Nous pouvons voir qu'il publie très bien les résultats formatés

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )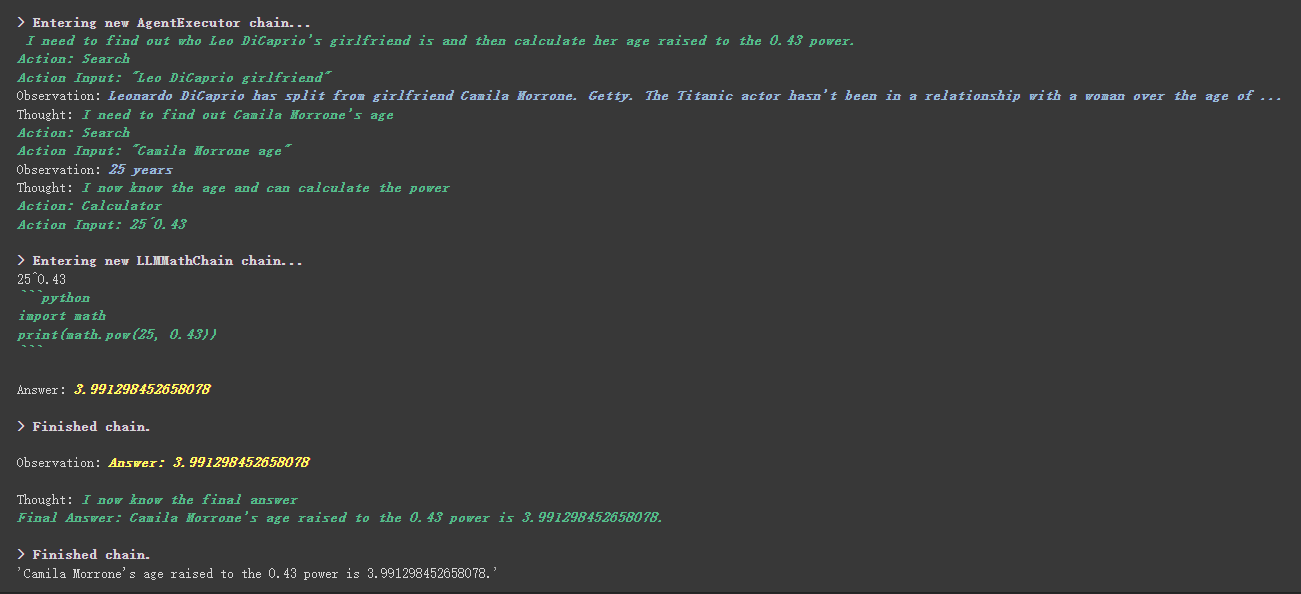
Il y工具中描述内容une chose plus intéressante dans l'outil personnalisé.
Par exemple, Calculator a écrit dans la description que si vous posez des questions sur les mathématiques, utilisez cet outil. Nous pouvons voir dans le processus d'exécution ci-dessus que dans la partie mathématique de notre propt demandé, il a utilisé l'outil de calculatrice pour les calculs.
Dans l'exemple précédent, nous avons utilisé la façon dont nous avons enregistré l'historique en personnalisant une liste pour stocker les conversations.
Bien sûr, vous pouvez également utiliser l'objet de mémoire inclus pour y parvenir.
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )Avant d'utiliser le modèle de visage étreint, vous devez d'abord définir les variables d'environnement
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''Utilisation du modèle de visage étreint en ligne
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))Tirez directement le modèle de visage étreint à utiliser localement
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))Avantages de tirer le modèle à utiliser localement:
Nous pouvons implémenter des commandes SQL via SQLDatabaseToolkit ou SQLDatabaseChain
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )Ici, vous pouvez vous référer à ces deux documents:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
Tous les cas se sont essentiellement terminés. Cet article n'est qu'une explication préliminaire de Langchain.
Et parce que Langchain itère très rapidement, il ira certainement de meilleures fonctions alors que l'IA continue de se développer, donc je suis très optimiste quant à cette bibliothèque open source.
J'espère que tout le monde pourra combiner Langchain pour développer des produits plus créatifs, plutôt que de simplement créer un tas de produits qui créent des clients de chat en un seul clic.
J'ai ajouté un 01 après ce titre.
Tous les exemples de codes de cet article sont là, je vous souhaite un apprentissage heureux.
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57ueapq?usp=sharing


