LangChain Chinese Getting Started Guide
1.0.0
Для легкого чтения были сгенерированы Gitbooks: https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
Адрес github: https://github.com/liaokongvfx/langchain-chinese-getting-started-guide
«Decryption Technology Langchain: панорамное руководство по созданию больших модельных приложений» было опубликовано сейчас: https://item.jd.com/14598210.html
Низкая ценовая и иностранная модель AI Model Transfer: https://api.91ai.me
Поскольку библиотека Лангхейна была быстро обновлена и итерации, но документ написан в начале апреля, и у меня ограниченная личная энергия, поэтому код в Колабе может быть несколько устаревшим. Если в эксплуатации есть какой -либо сбой, вы можете сначала найти то, что текущий документ был обновлен
Я добавил изменение изменений и обновил новый контент.
Если вы хотите изменить корневой маршрут запроса API OpenAI на свой собственный прокси -адрес, вы можете изменить его, установив переменную среды "openai_api_base".
Связанный справочный код: https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#l48
Или при инициализации объектов модели, связанных с OpenAI, пройдите в переменной "openai_api_base".
Связанный справочный код: https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
Как мы все знаем, API OpenAI не может быть подключен к Интернету, поэтому определенно невозможно использовать свои собственные функции для поиска и дать ответы, суммировать документы PDF и выполнять вопросы и ответы на основе видео на YouTube. Итак, давайте представим очень мощную стороннюю библиотеку с открытым исходным кодом: LangChain .
Адрес документа: https://python.langchain.com/en/latest/
Эта библиотека в настоящее время очень активна и итерат каждый день.
Langchain - это основа для разработки приложений, основанных на языковых моделях. У него есть 2 основные способности:
Модель LLM: модель большой языка, модель большой языка
LLM Call
Быстрое управление, поддерживает различные пользовательские шаблоны
Он имеет большое количество загрузчиков документов, таких как электронная почта, маркировка, pdf, youtube ...
Поддержка индексов
Цепочки
Я считаю, что все будут смущены после прочтения вышеупомянутого введения. Не волнуйтесь, приведенная выше концепция на самом деле не очень важна, когда мы впервые начали учиться.
Однако вот несколько понятий, которые должны быть известны.
Как следует из названия, это для загрузки данных из указанного источника. For example: folder DirectoryLoader , Azure Storage AzureBlobStorageContainerLoader , CSV file CSVLoader , Evernote EverNoteLoader , Google GoogleDriveLoader , any web page UnstructuredHTMLLoader , PDF PyPDFLoader , S3 S3DirectoryLoader / S3FileLoader ,
YouTube YoutubeLoader и т. Д. Я просто кратко перечислил несколько из них.
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
После чтения источника данных с использованием загрузчика загрузчика источник данных должен быть преобразован в объект документа, прежде чем его можно будет использовать позже.
Как следует из названия, сегментация текста используется для разделения текста. Зачем нужно разделить текст? Поскольку каждый раз, когда мы отправляем текст в качестве Propt в API OpenAI или используем функцию встраивания API OpenAI, существуют ограничения на символ.
Например, если мы отправим PDF на 300 страниц API OpenAI и попросим его подвести итог, он обязательно сообщит об ошибке, которая превышает максимальный токен. Так что здесь нам нужно использовать текстовый сплиттер, чтобы разделить документ, в котором появляется наш загрузчик.
Потому что поиск корреляции данных на самом деле является векторной операцией. Поэтому, независимо от того, используем ли мы функцию встраивания API OpenAI или напрямую запросить векторную базу данных, нам необходимо векторизировать наш Document загруженного данного данных, чтобы выполнить поиск в векторной работе. Преобразование в вектор также очень проста.
Чиновник также предоставляет много векторных баз данных для использования.
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
Мы можем понять цепь как задачу. Цепочка - это задача, и, конечно, она также может выполнить несколько цепей одной, как цепочка.
Мы можем просто понять, что это может динамически помочь нам выбрать и вызовать цепочку или существующие инструменты.
Для процесса выполнения, пожалуйста, обратитесь к следующей картине:
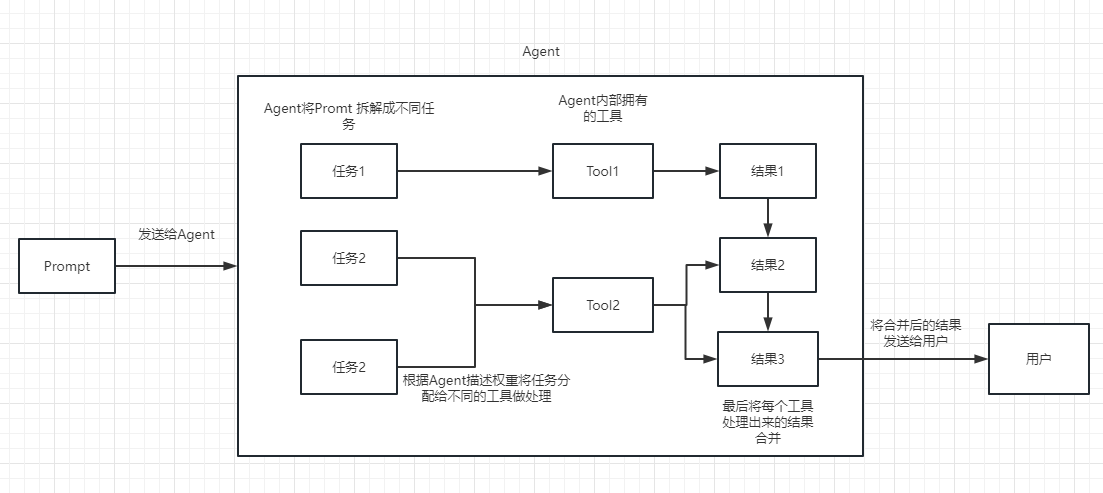
Используется для измерения актуальности текста. Это также является ключом к способности API OpenAI строить собственную базу знаний.
Его самое большое преимущество перед точной настройкой заключается в том, что ему не нужно тренироваться и может добавлять новый контент в режиме реального времени, вместо того, чтобы добавлять новый контент один раз, а стоимость во всех аспектах намного ниже, чем точная настройка.
Для конкретных сравнений и выборов, пожалуйста, см.
Благодаря вышеупомянутым основным понятиям, у вас должно быть определенное понимание Лэнгкейна, но вы все равно можете быть немного запутанными.
Все это небольшие вопросы.
Поскольку наш API OpenAI продвигается, LLM, используемый в наших последующих примерах, основан на открытом AI.
Конечно, в конце этой статьи весь код будет сохранен в качестве файла colab ipynb и предоставлен для всех, чтобы учиться.
Рекомендуется посмотреть на каждый пример в порядке, потому что в следующем примере будут использоваться точки знаний в предыдущем примере.
Конечно, если вы что -то не понимаете, не волнуйтесь.
В первом случае мы будем использовать Langchain для загрузки модели Openai и завершить вопросы и ответы.
Перед началом нам нужно сначала настроить наш ключ Openai.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'Затем мы импортируем и выполняем
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
В настоящее время мы можем увидеть результат, который он дал нам.
Далее давайте сделаем что -нибудь интересное. Давайте заставим наш API Openai для поиска в Интернете и вернем ответы нам.
Здесь нам нужно использовать Serpapi для его реализации, который предоставляет интерфейс API для поиска Google.
Во -первых, нам нужно зарегистрировать пользователя на официальном веб -сайте Serpapi, https://serpapi.com/ и скопировать его, чтобы сгенерировать ключ API для нас.
Затем нам нужно установить его в переменную среды, например, клавиша API OpenAI выше.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'Затем начните писать мой код
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )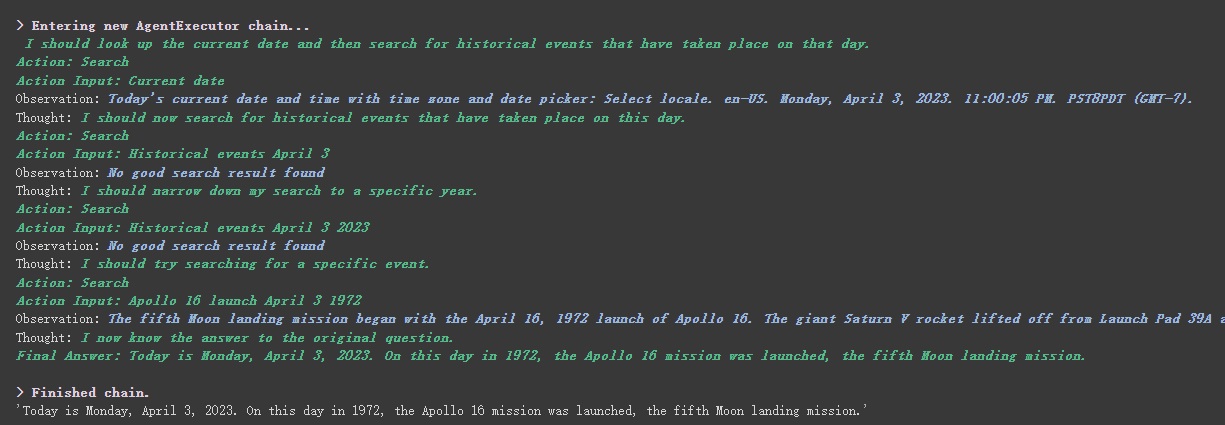
Мы видим, что он правильно вернул дату (иногда разницу) и вернулся к сегодняшнему дню в истории.
Существует verbose параметров на объектах цепи и агента.
Как вы можете видеть из результата, возвращенного выше, он разбивает наш вопрос на несколько шагов, а затем получает окончательный ответ шаг за шагом.
Что касается значения нескольких вариантов типа агента (если вы не можете его понять, это не повлияет на следующее обучение. Если вы используете его слишком много, вы, естественно, поймете это):
Search и Lookup , первое используется для поиска, а последний используется для поиска термина, например: инструмент WipipediaGoogle search APIВы можете увидеть это для введения React: https://arxiv.org/pdf/2210.03629.pdf
Реализация Python React Pattern of LLM: https://til.simonwillison.net/llms/python-react-pattern
Официальное объяснение типа агента:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-description
Одна вещь, которую следует отметить, состоит в том, что этот
serpapiкажется не очень дружелюбным для китайца, поэтому запрос на подсказку рекомендуется использовать английский язык.
Конечно, чиновник написал агент ChatGPT Plugins .
Однако в настоящее время могут использоваться только плагины, которые не требуют авторизации.
Те, кто заинтересован, могут прочитать этот документ: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Chatgpt может заработать только на чиновнике, а API Openai может заработать для меня деньги
Если мы хотим использовать API OpenAI, чтобы обобщить абзац текста, наш обычный способ - отправить его непосредственно в API, чтобы его суммировали. Однако, если текст превышает максимальный предел токена API, сообщается об ошибке.
В настоящее время мы обычно сегментируем статью, такую как расчет и разделение ее через тиктокен, а затем отправляем каждый абзац в API для резюме и, наконец, суммирование резюме каждого абзаца.
Если вы используете Langchain, он очень хорошо помог нам справиться с этим процессом, что облегчает нам писать код.
Без лишних слов просто загрузите код.
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
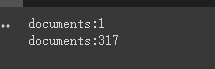
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])Во -первых, мы печатаем количество документов до и после резки.
Наконец, краткое изложение первых 5 документов - вывод.

Вот несколько параметров, чтобы отметить:
Параметр chunk_overlap текстового сплиттера
Это относится к содержимому, заканчивающемуся несколькими предыдущими документами в каждом документе после резки. Например, когда chunk_overlap=0 chunk_overlap=2 первым документом является aaaaaaa, второй - bbbbbb;
Однако это не абсолютно, это зависит от конкретного алгоритма внутри используемой модели сегментации текста.
Вы можете обратиться к этому документу для текстовых расщепления: https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
параметр цепочки chain_type
Этот параметр в основном управляет тем, как документ передается в модель LLM, и всего 4 способа:
stuff : это проще и грубо, и сразу передаст все документы модели LLM. Если есть много документов, это неизбежно сообщает об ошибке, которая превышает максимальный предел токена, поэтому это обычно не выбирается при суммировании текста.
map_reduce : этот метод сначала обобщает каждый документ и, наконец, суммирует результаты, обобщенные всеми документами.
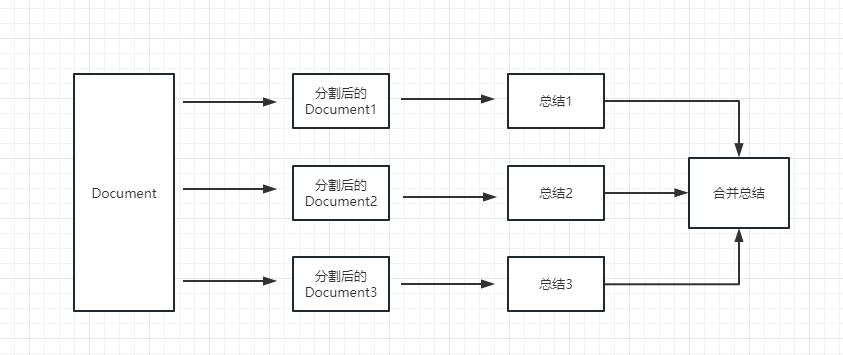
refine : этот метод сначала подведет сумму первого документа, а затем отправит контент, обобщенное первым документом, и второй документ в модель LLM для резюме и так далее. Преимущество этого метода заключается в том, что при суммировании последнего документа потребуется предыдущий документ, чтобы суммировать, добавить контекст в документ, который необходимо обобщить, и увеличить согласованность суммарного содержания.
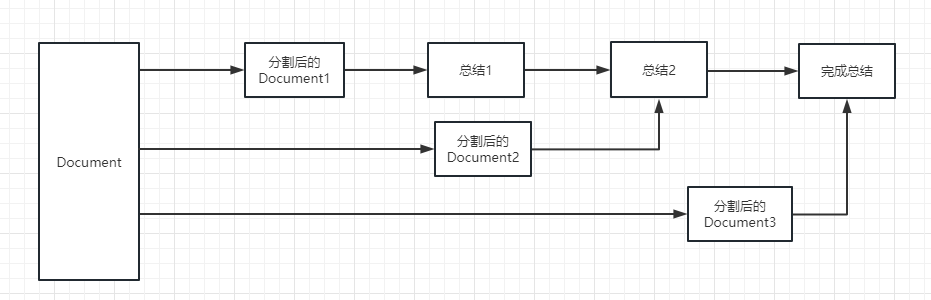
map_rerank : Этот тип цепочки обычно используется не в резюме, а в вопросе и цепочке ответов. Во -первых, вам нужно задать вопрос.
В этом примере мы объясним, как построить базу знаний, прочитав несколько документов из США на местном уровне и использовать API OpenAI для поиска и дать ответы на базе знаний.
Это очень полезный урок, такой как робот, который может легко представить бизнес компании или робот, который представляет продукт.
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )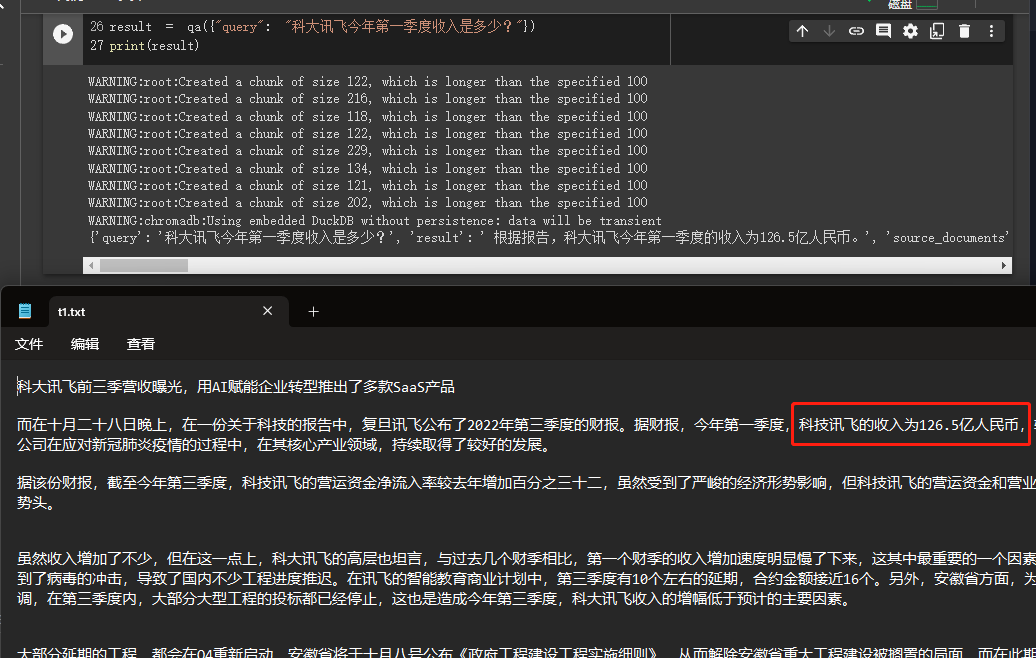
Через результаты мы можем видеть, что он успешно получил правильный ответ из данных, которые мы дали.
Для получения подробной информации об Openai Enterdings, пожалуйста, обратитесь к этой ссылке: https://platform.openai.com/docs/guides/embeddings
Одним из шагов в нашем предыдущем случае было преобразование информации о документах в векторную информацию и информацию о встроении и временно хранить ее в базу данных Chroma.
Поскольку он временно хранится, когда выполняется приведенный выше код, данные после векторизации выше будут потеряны. Если вы хотите использовать его в следующий раз, вам нужно снова вычислить встраивание, что определенно не то, что мы хотим.
Итак, в этом случае мы поговорим о том, как сохранить векторные данные через две базы данных Chroma и Pinecone.
Поскольку Langchain поддерживает многие базы данных, вот два, которые используются чаще.
Хрома
Chroma - это локальная векторная база данных, которая обеспечивает persist_directory для установки постоянного каталога для постоянства. При чтении вам нужно только вызвать метод from_document для загрузки.
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )Pinecone
Pinecone - это онлайн -база данных векторной. Итак, первый шаг я все еще могу зарегистрироваться и получить соответствующий ключ API. https://app.pinecone.io/
Бесплатная версия будет автоматически очищена, если индекс не используется в течение 14 дней.
Затем создайте нашу базу данных:
Имя индекса: это случайно
Размеры: модель Openai-Embedding-ADA-002-выходные размеры 1536, поэтому мы заполняем 1536 здесь
Метрика: может по умолчанию в косинус
Выберите стартовый план
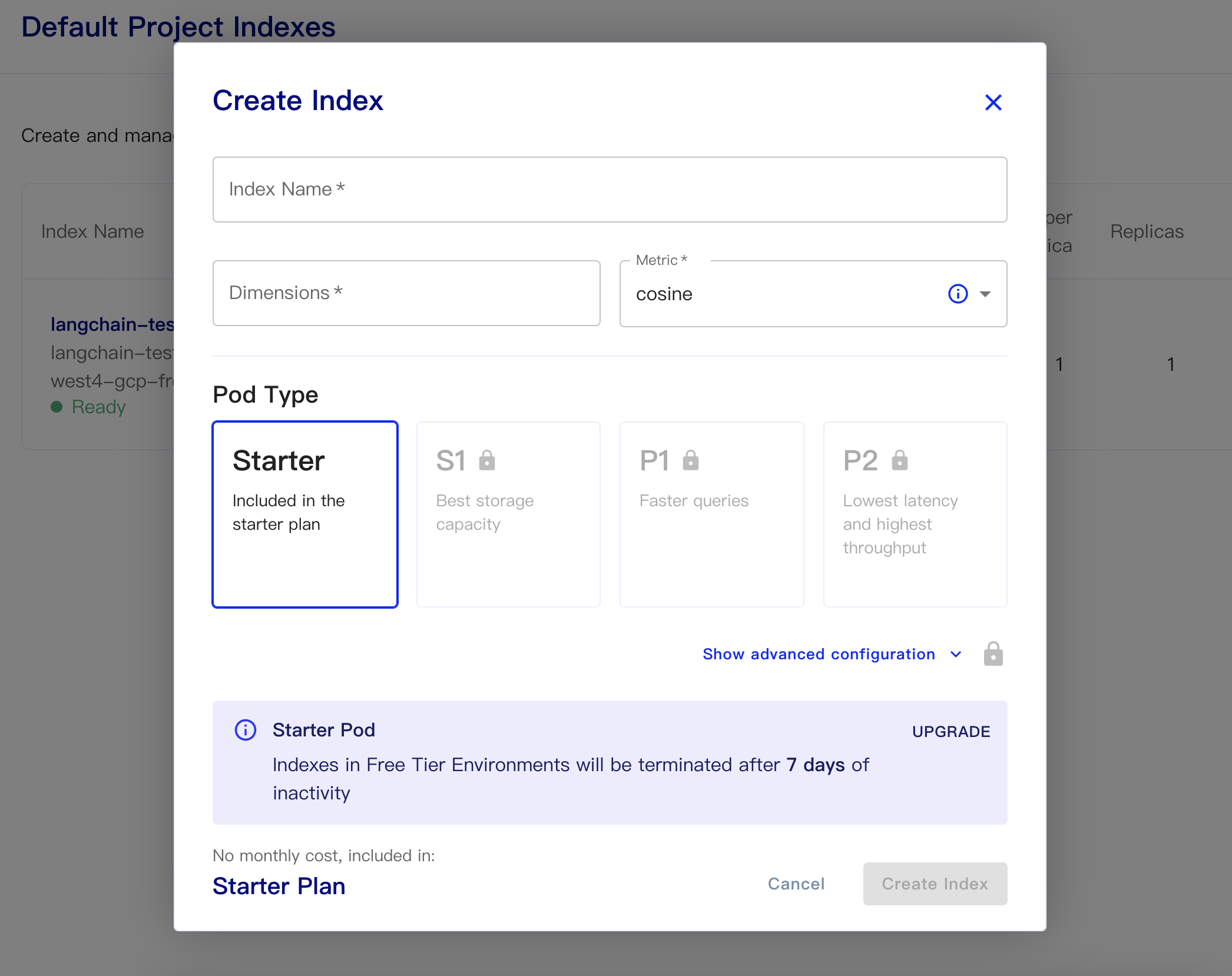
Постоянные данные и коды данных загрузки следующие
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )Простой код для получения встраивания из базы данных и ответа на него следующим образом
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
После того, как модель API CATGPT (то есть GPT-3.5-Turbo) была выпущена, она была любима всеми, потому что это было меньше денег, поэтому Langchain также добавил эксклюзивные цепи и модели.
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])Мы видим, что он может точно ответить на вопросы и ответы на это видео масляной трубы

Потоковые ответы также очень удобны
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) В основном мы используем zapier для подключения тысяч инструментов.
Таким образом, наш первый шаг - подать заявку на учетную запись и его ключ API естественного языка. https://zapier.com/l/natural-language-actions
Его ключ API должен заполнить информационное приложение. Однако после заполнения информации вы можете в основном увидеть утвержденное электронное письмо в адрес электронной почты за считанные секунды.
Затем мы открываем нашу страницу конфигурации API, щелкнув правой кнопкой мыши подключение. Мы нажимаем Manage Actions справа, чтобы настроить приложения, которые мы хотим использовать.
Я настроил действия Gmail для чтения и отправки электронных писем здесь, и все поля выбираются с помощью AI.
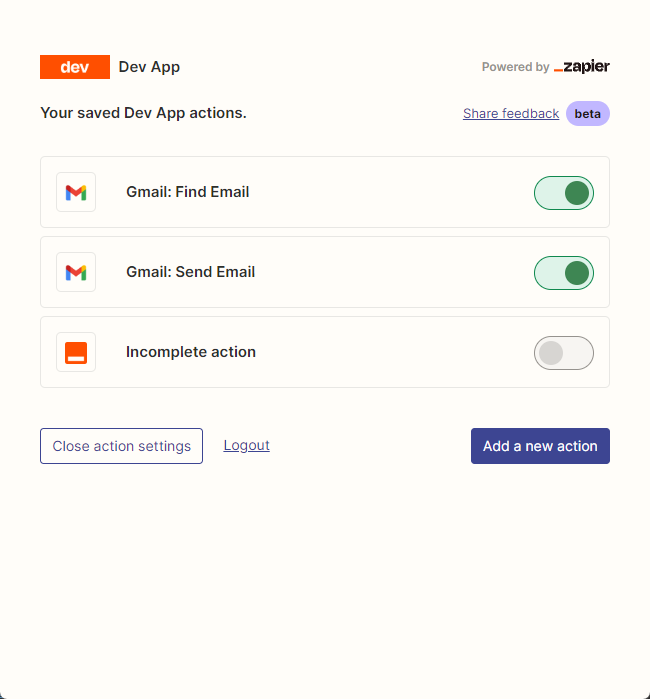
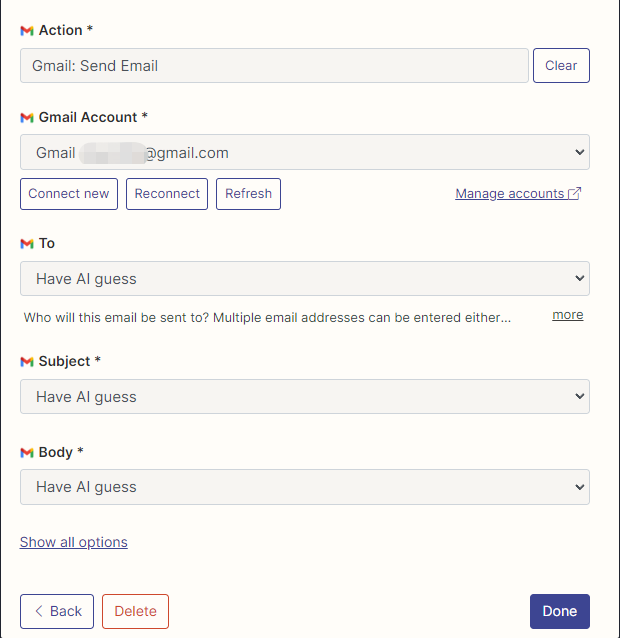
После завершения конфигурации мы начинаем писать код
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
Мы видим, что он успешно прочитал последнее электронное письмо, отправленное ему ******@qq.com , и снова отправил сводный контент ******@qq.com .
Это электронное письмо, которое я отправил в Gmail.

Это электронное письмо, которое он отправил на свою электронную почту QQ.
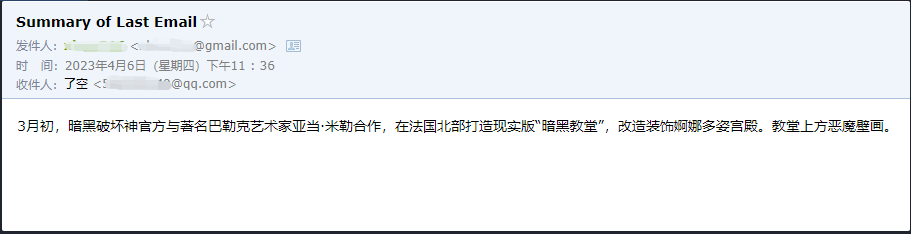
Это всего лишь небольшой пример, потому что у zapier есть тысячи приложений, поэтому мы можем легко построить свои собственные рабочие процессы с API OpenAI.
Некоторые из более крупных точек знаний были объяснены, и следующее содержание посвящено некоторым интересным небольшим примерам, как расширения.
Поскольку он прикован, он также может выполнять несколько цепей в последовательности.
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )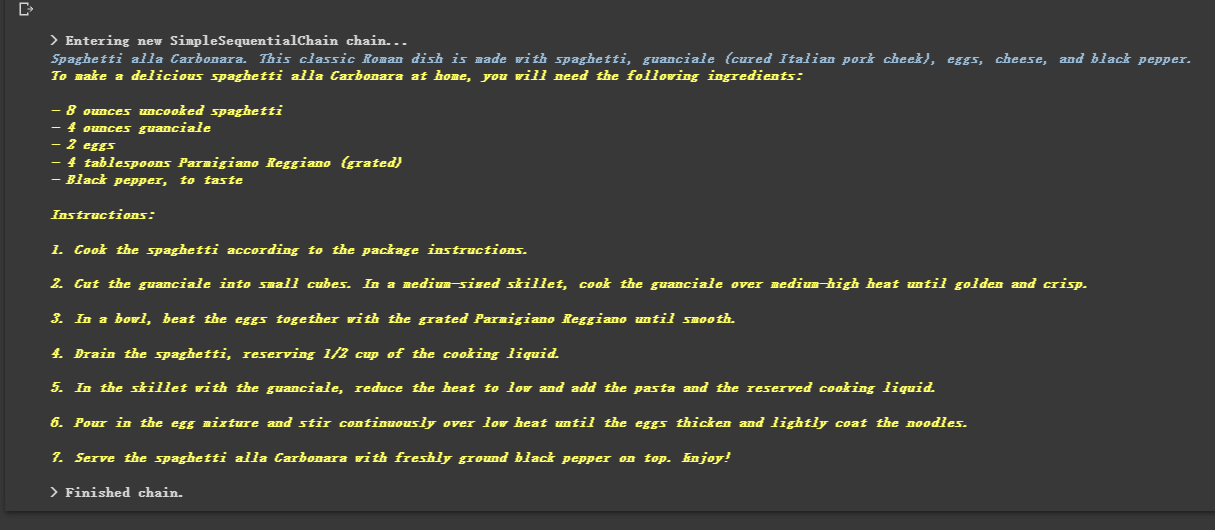
Иногда мы хотим, чтобы вывод был не текстом, а структурированными данными, такими как JSON.
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
Иногда нам нужно ползти Более сильная структура и информация на веб -странице должна быть возвращена в режиме JSON.
Мы можем использовать класс LLMRequestsChain для его реализации.
Для легкого понимания я напрямую использовал метод быстрого приглашения для форматирования результатов выходных данных в примере, но не использовал
StructuredOutputParserиспользуемый в предыдущем случае для его форматирования, что также можно рассматривать как предоставление другой идеи форматирования.
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])Мы можем видеть, что он очень хорошо выводит отформатированные результаты

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )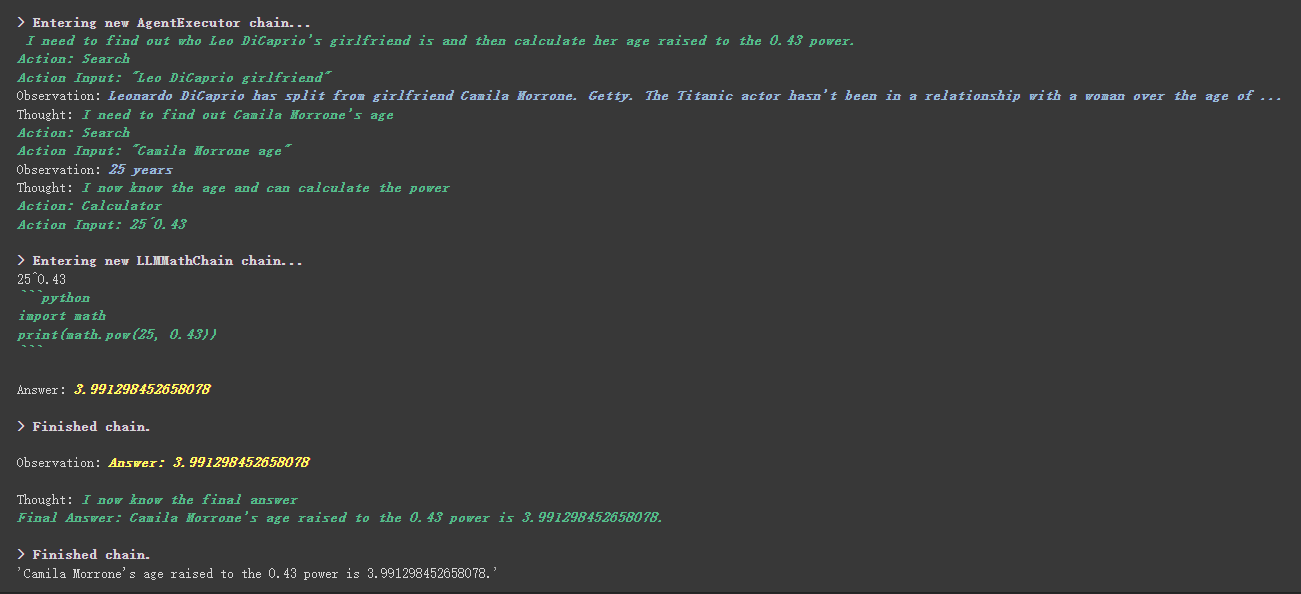
工具中描述内容инструменте есть более интересная вещь.
Например, калькулятор написал в описании, что если вы задаете вопросы о математике, используйте этот инструмент. В приведенном выше процессе выполнения мы видим, что в математической части нашего запрошенного Propt он использовал инструмент калькулятора для вычислений.
В предыдущем примере мы использовали способ, которым мы сохранили историю, настраивая список для хранения разговоров.
Конечно, вы также можете использовать включенный объект памяти для достижения этого.
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )Перед использованием модели обнимающего лица, вам нужно сначала установить переменные среды
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''Использование модели обнимающего лица онлайн
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))Потяните модель обнимающего лица прямо, чтобы использовать локально
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))Преимущества вытягивания модели для использования локально:
Мы можем реализовать команды SQL через SQLDatabaseToolkit или SQLDatabaseChain
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )Здесь вы можете ссылаться на эти два документа:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
Все случаи в основном закончились. Эта статья является лишь предварительным объяснением Лангчейна.
И поскольку Langchain очень быстро итерации, она определенно будет выполнять лучшие функции по мере того, как ИИ продолжает развиваться, поэтому я очень оптимистичен в этой библиотеке с открытым исходным кодом.
Я надеюсь, что каждый сможет объединить Langchain для разработки больше креативных продуктов, а не просто создавать кучу продуктов, которые создают клиентов в чате одним щелчком.
Я добавил 01 после этого названия.
Все образцы кодов в этой статье здесь, я желаю вам счастливого обучения.
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57ueapq?usp=Sharing


