One Shot Voice Cloning
1.0.0
Inglés | 中文
❗ Ahora proporcionamos código de inferencia y modelos previos a la capacitación. Podrías generar cualquier sonido de texto que desee.
El entrenamiento modelo solo usa el corpus de la emoción neutral y no usa ningún discurso fuertemente emocional.
Todavía hay grandes desafíos en la transferencia de estilo fuera de dominio. Limitado por el Corpus de Entrenamiento, es difícil para los métodos de estilo de estilo incrustado o de estilo no supervisado (como GST) para imitar los datos invisibles.
Con la ayuda de UNET Network y Adain Layer, nuestro algoritmo propuesto tiene potentes capacidades de transferencia de altavoces y estilo.
Resultados de demostración
Enlace de papel
El cuaderno de Colab es muy recomendable para la prueba.
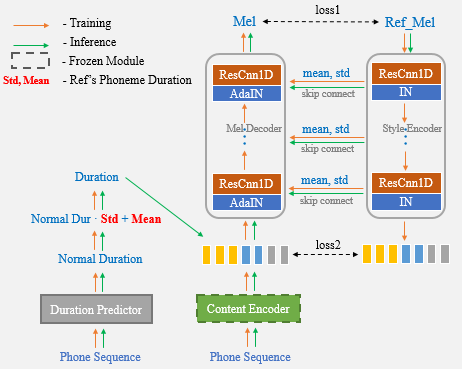
Ahora, solo necesita usar el discurso de referencia para la clonación de voz de una sola vez y ya no necesita ingresar manualmente las estadísticas de duración adicionalmente.
? Los autores están preparando un proceso de entrenamiento simple, claro y bien documentado de UNET-TTS basado en Aishell3.
Contiene:
¡Manténganse al tanto!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)Opción 1: Modifique el archivo de audio de referencia que se clonará en el archivo unettts_syn.py. (Consulte este archivo para más detalles)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyOpción 2: cuaderno
Nota : Agregue la ruta de clonación de la voz de un disparo a la ruta del sistema. De lo contrario, la clase requerida no se puede importar del archivo unettts_syn.py.
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-cloning


