One Shot Voice Cloning
1.0.0
ภาษาอังกฤษ | 中文
❗ตอนนี้เราให้รหัสการอนุมานและโมเดลการฝึกอบรมล่วงหน้า คุณสามารถสร้างเสียงข้อความใด ๆ ที่คุณต้องการ
การฝึกอบรมแบบจำลองใช้คลังอารมณ์ของอารมณ์ที่เป็นกลางเท่านั้นและไม่ได้ใช้คำพูดทางอารมณ์อย่างยิ่ง
ยังคงมีความท้าทายที่ดีในการถ่ายโอนสไตล์นอกโดเมน ถูก จำกัด โดยคลังการฝึกอบรมมันเป็นเรื่องยากสำหรับวิธีการเรียนรู้แบบผู้พูดหรือการเรียนรู้สไตล์ที่ไม่ได้รับการดูแล (เช่น GST) เพื่อเลียนแบบข้อมูลที่มองไม่เห็น
ด้วยความช่วยเหลือของ UNET Network และ Adain Layer อัลกอริทึมที่เราเสนอมีลำโพงที่ทรงพลังและความสามารถในการถ่ายโอนสไตล์
ผลการสาธิต
ลิงค์กระดาษ
แนะนำให้ใช้สมุดบันทึก Colab สำหรับการทดสอบ
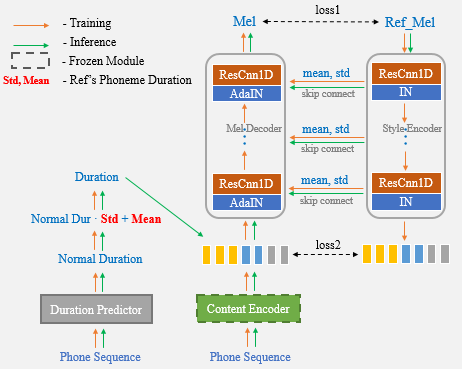
ตอนนี้คุณจะต้องใช้คำพูดอ้างอิงสำหรับการโคลนนิ่งเสียงเดียวและไม่จำเป็นต้องป้อนสถิติระยะเวลาด้วยตนเองอีกต่อไป
- ผู้เขียนกำลังเตรียมกระบวนการฝึกอบรมที่เรียบง่ายชัดเจนและมีเอกสารที่ดีของ UNET-TTS ตาม Aishell3
มันมี:
คอยติดตาม!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)ตัวเลือกที่ 1: แก้ไขไฟล์เสียงอ้างอิงที่จะโคลนในไฟล์ unettts_syn.py (ดูไฟล์นี้สำหรับรายละเอียดเพิ่มเติม)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyตัวเลือกที่ 2: สมุดบันทึก
หมายเหตุ : โปรดเพิ่มเส้นทางการโคลนนิ่งเดียวกับการโคลนนิ่งลงในเส้นทางระบบ มิฉะนั้นคลาสที่ต้องการไม่สามารถนำเข้าจากไฟล์ unettts_syn.py
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-loning


