One Shot Voice Cloning
1.0.0
영어 | 中文
이제 우리는 추론 코드와 사전 훈련 모델을 제공합니다. 원하는 텍스트 사운드를 생성 할 수 있습니다.
모델 훈련은 중립적 감정의 코퍼스 만 사용하며 강력하게 감정적 인 연설을 사용하지 않습니다.
도메인 이외의 스타일 전송에는 여전히 큰 도전이 있습니다. 훈련 코퍼스에 의해 제한되면, 화자 엠 베딩 또는 감독되지 않은 스타일 학습 (GST) 방법이 보이지 않는 데이터를 모방하기가 어렵습니다.
UNET 네트워크 및 Adain 계층의 도움으로 제안 된 알고리즘에는 강력한 스피커 및 스타일 전송 기능이 있습니다.
데모 결과
종이 링크
Colab 노트북은 테스트에 적극 권장됩니다.
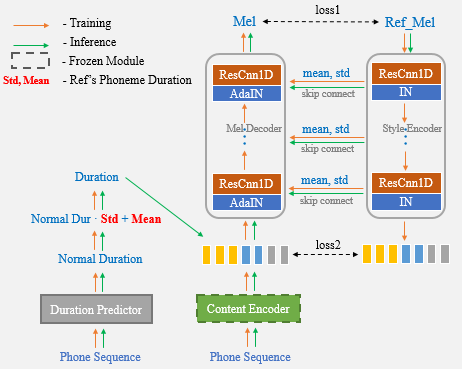
이제 원샷 음성 복제에 대한 참조 음성 만 사용하면 더 이상 지속 시간 통계를 수동으로 입력 할 필요가 없습니다.
? 저자는 Aishell3을 기반으로 UNET-TTS의 단순하고 명확하며 잘 문서화 된 교육 과정을 준비하고 있습니다.
그것은 포함한다 :
계속 지켜봐!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)옵션 1 : unettts_syn.py 파일에서 클로닝 할 참조 오디오 파일을 수정하십시오. (자세한 내용은이 파일을 참조하십시오)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.py옵션 2 : 노트북
참고 : 시스템 경로에 원샷-보이스 클로닝 경로를 추가하십시오. 그렇지 않으면 필수 클래스 유사는 unettts_syn.py 파일에서 가져올 수 없습니다.
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-cloning


