One Shot Voice Cloning
1.0.0
英語| 中文
ここで、推論コードとトレーニング前モデルを提供します。必要なテキストサウンドを生成できます。
モデルトレーニングは、ニュートラルな感情のコーパスのみを使用し、強く感情的なスピーチを使用しません。
ドメイン外スタイルの転送にはまだ大きな課題があります。トレーニングコーパスによって制限されているため、目に見えないデータを模倣するために、スピーカーの埋め込みや監視なしのスタイル学習(GSTなど)の方法が困難です。
UNETネットワークとAdainレイヤーの助けを借りて、提案されたアルゴリズムには強力なスピーカーとスタイルの転送機能があります。
デモの結果
紙のリンク
Colabノートブックはテストに強くお勧めします。
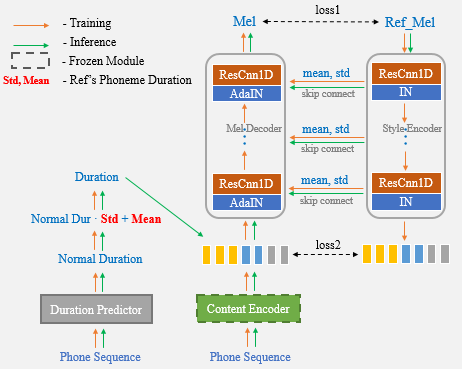
これで、1-Shot Voiceのクローン化には参照スピーチを使用するだけで、期間統計をさらに手動で入力する必要がなくなります。
?著者は、Aishell3に基づいたUNET-TTのシンプルで明確な、文書化されたトレーニングプロセスを準備しています。
含む:
乞うご期待!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)オプション1:unettts_syn.pyファイルでクローン化される参照オーディオファイルを変更します。 (詳細については、このファイルを参照してください)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyオプション2:ノートブック
注:One-Shot-Voice-Cloningパスをシステムパスに追加してください。それ以外の場合、必要なクラスUnetttsをunettts_syn.pyファイルからインポートすることはできません。
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-cloning


