One Shot Voice Cloning
1.0.0
英语| 中文
❗现在我们提供了推论代码和预训练模型。您可以生成想要的任何文本声音。
模型训练只会使用中性情绪的语料库,并且不使用任何强烈的情感语音。
台外风格转移仍然存在巨大的挑战。受培训语料库的限制,扬声器插入或无监督的样式学习(如GST)的方法很难模仿看不见的数据。
在UNET网络和ADAIN层的帮助下,我们提出的算法具有强大的扬声器和样式传输功能。
演示结果
纸链接
强烈建议使用COLAB笔记本进行测试。
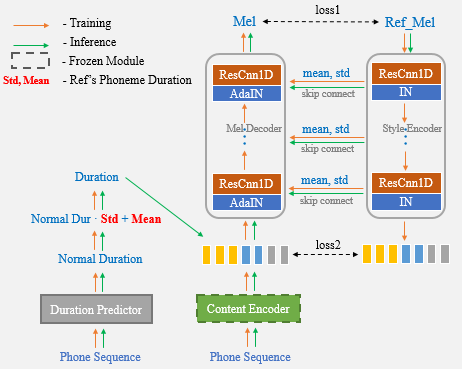
现在,您只需要使用参考语音进行一次性语音克隆,而不再需要手动输入持续时间统计信息。
?作者正在准备基于Aishell3的UNET-TTS的简单,清晰且有据可查的培训过程。
它包含:
敬请关注!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)选项1:修改要克隆在unettts_syn.py文件中的参考音频文件。 (有关更多详细信息,请参见此文件)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.py选项2:笔记本
注意:请在系统路径中添加单次弹药路径。否则将无法从unettts_syn.py文件导入所需类的UNETTT。
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/realtim-voice-cloning


