One Shot Voice Cloning
1.0.0
Englisch | 中文
❗ Jetzt liefern wir Inferenzcode und Vor-Training-Modelle. Sie können alle gewünschten Textgeräusche generieren.
Das Modelltraining verwendet nur den Korpus neutraler Emotionen und verwendet keine stark emotionale Sprache.
Es gibt immer noch große Herausforderungen beim Transfer außerhalb des Domänenstils. Durch das Trainingskorpus begrenzt ist es für die Lautsprecher-Embedding oder unbeaufsichtigten Style Learning (wie GST) -Methoden schwierig, um die unsichtbaren Daten zu imitieren.
Mit Hilfe von Unet Network und Adain Layer verfügt unser vorgeschlagener Algorithmus über leistungsstarke Lautsprecher- und Stilübertragungsfunktionen.
Demo -Ergebnisse
Papierverbindung
Colab Notebook ist für den Test sehr empfohlen.
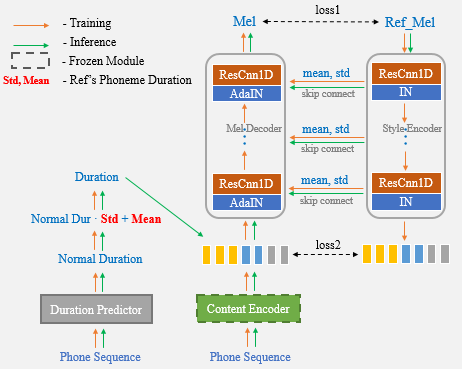
Jetzt müssen Sie nur noch die Referenzrede für das Klonen von One-Shot-Sprachklonen verwenden und müssen nicht mehr die Dauerstatistik nicht mehr manuell eingeben.
? Die Autoren bereiten einen einfachen, klaren und gut dokumentierten Trainingsprozess von UNET-TTs vor, der auf Aishell3 basiert.
Es enthält:
Bleiben Sie dran!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)Option 1: Ändern Sie die Referenz -Audio -Datei, die in die Datei unetts_syn.py kloniert werden soll. (Weitere Informationen finden Sie in dieser Datei)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyOption 2: Notebook
HINWEIS : Bitte fügen Sie den Ein-Shot-Voice-Kloning-Pfad zum Systempfad hinzu. Andernfalls können die erforderliche Klasse Unettts nicht aus der Datei Unetts_Syn.py importiert werden.
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-coning


