One Shot Voice Cloning
1.0.0
English | 中文
❗ Now we provide inferencing code and pre-training models. You could generate any text sounds you want.
The model training only uses the corpus of neutral emotion, and does not use any strongly emotional speech.
There are still great challenges in out-of-domain style transfer. Limited by the training corpus, it is difficult for the speaker-embedding or unsupervised style learning (like GST) methods to imitate the unseen data.
With the help of Unet network and AdaIN layer, our proposed algorithm has powerful speaker and style transfer capabilities.
Demo results
Paper link
Colab notebook is Highly Recommended for test.
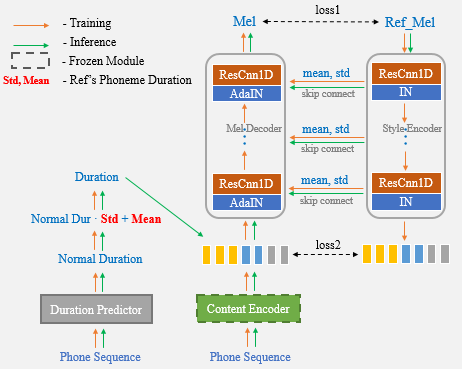
Now, you only need to use the reference speech for one-shot voice cloning and no longer need to manually enter the duration statistics additionally.
? The authors are preparing simple, clear, and well-documented training process of Unet-TTS based on Aishell3.
It contains:
Stay tuned!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)Option 1: Modify the reference audio file to be cloned in the UnetTTS_syn.py file. (See this file for more details)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyOption 2: Notebook
Note: Please add the One-Shot-Voice-Cloning path to the system path. Otherwise the required class UnetTTS cannot be imported from the UnetTTS_syn.py file.
import sys
sys.path.append("<your repository's parent directory>/One-Shot-Voice-Cloning")
from UnetTTS_syn import UnetTTS
from tensorflow_tts.audio_process import preprocess_wav
"""Inint models"""
models_and_params = {"duration_param": "train/configs/unetts_duration.yaml",
"duration_model": "models/duration4k.h5",
"acous_param": "train/configs/unetts_acous.yaml",
"acous_model": "models/acous12k.h5",
"vocoder_param": "train/configs/multiband_melgan.yaml",
"vocoder_model": "models/vocoder800k.h5"}
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS(models_and_params, text2id_mapper, feats_yaml)
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav(wav_fpath, source_sr=16000, normalize=True, trim_silence=True, is_sil_pad=True,
vad_window_length=30,
vad_moving_average_width=1,
vad_max_silence_length=1)
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio, _, _ = Tts_handel.one_shot_TTS(text, ref_audio)https://github.com/TensorSpeech/TensorFlowTTS
https://github.com/CorentinJ/Real-Time-Voice-Cloning


