One Shot Voice Cloning
1.0.0
Bahasa Inggris | 中文
❗ Sekarang kami menyediakan kode inferasi dan model pra-pelatihan. Anda dapat menghasilkan suara teks apa pun yang Anda inginkan.
Pelatihan model hanya menggunakan kumpulan emosi netral, dan tidak menggunakan ucapan yang sangat emosional.
Masih ada tantangan besar dalam transfer gaya out-of-domain. Dibatasi oleh corpus pelatihan, sulit untuk metode pembelajaran gaya pembicara atau tidak diawasi (seperti GST) untuk meniru data yang tidak terlihat.
Dengan bantuan NETET Network dan Adain Layer, algoritma yang kami usulkan memiliki kemampuan speaker dan gaya transfer yang kuat.
Hasil demo
Tautan kertas
Colab Notebook sangat disarankan untuk tes.
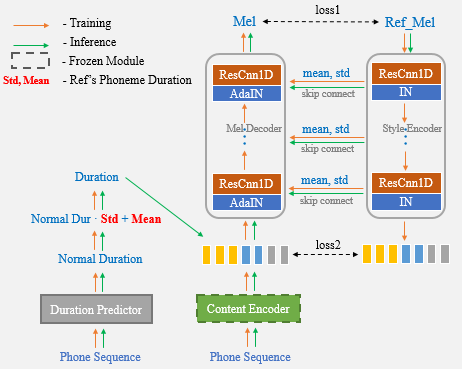
Sekarang, Anda hanya perlu menggunakan pidato referensi untuk kloning suara satu-shot dan tidak perlu lagi secara manual memasukkan statistik durasi tambahan.
? Para penulis sedang mempersiapkan proses pelatihan UNET-TTS yang sederhana, jelas, dan terdokumentasi dengan baik berdasarkan Aishell3.
Itu berisi:
Pantau terus!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)Opsi 1: Ubah file audio referensi yang akan dikloning dalam file unettts_syn.py. (Lihat file ini untuk lebih jelasnya)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyOpsi 2: Notebook
Catatan : Harap tambahkan jalur satu-shot-voice-cloning ke jalur sistem. Kalau tidak, kelas yang diperlukan tidak dapat diimpor dari file unettts_syn.py.
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-cloning


