One Shot Voice Cloning
1.0.0
الإنجليزية | 中文
❗ نحن الآن نقدم رمز الاستدلال ونماذج ما قبل التدريب. يمكنك إنشاء أي نص نص تريده.
يستخدم التدريب النموذجي فقط مجموعة المشاعر المحايدة ، ولا يستخدم أي خطاب عاطفي قوي.
لا تزال هناك تحديات كبيرة في نقل أسلوب خارج المجال. محدودة من قبل مجموعة التدريب ، من الصعب على أساليب التعلم غير الخاضعة للإشراف أو غير خاضعة للإشراف (مثل GST) تقليد البيانات غير المرئية.
بمساعدة شبكة UNET وطبقة Adain ، تحتوي الخوارزمية المقترحة على إمكانيات نقل قوية ونقل الأسلوب.
النتائج التجريبية
رابط الورق
يوصى بشدة بمدفوعة كولاب للاختبار.
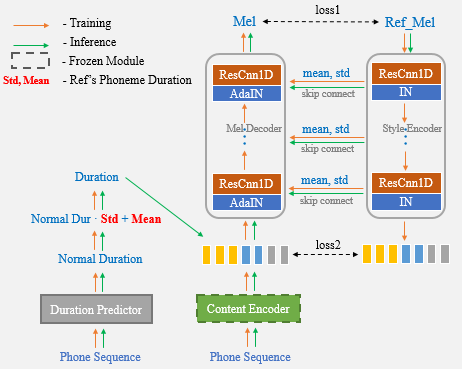
الآن ، تحتاج فقط إلى استخدام الكلام المرجعي لاستنساخ صوت واحد ولم تعد بحاجة إلى إدخال إحصائيات المدة يدويًا.
؟ يقوم المؤلفون بإعداد عملية تدريب بسيطة وواضحة وموثقة جيدًا لـ UNET-TTS استنادًا إلى AISHELL3.
يحتوي على:
ابقوا متابعين!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)الخيار 1: تعديل ملف الصوت المرجعي ليتم استنساخه في ملف unettts_syn.py. (انظر هذا الملف لمزيد من التفاصيل)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyالخيار 2: دفتر ملاحظات
ملاحظة : يرجى إضافة مسار ترسّم الخلاصة الواحدة إلى مسار النظام. وإلا فإن فئة Unettts المطلوبة لا يمكن استيرادها من ملف unettts_syn.py.
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/Real-Time-Voice-Cloning


