One Shot Voice Cloning
1.0.0
Английский | 中文
❗ Теперь мы предоставляем код вывода и модели предварительного обучения. Вы можете генерировать любой текст, который вы хотите.
Обучение модели использует только корпус нейтральных эмоций и не использует какую -либо сильную эмоциональную речь.
Есть все еще большие проблемы в переводе с вне доменного стиля. Ограниченное учебным корпусом, методам, встроенным в стиль динамиков или без приспособленного стиля (например, GST), подражать невидимым данным.
С помощью Unet Network и Adain Layer наш предлагаемый алгоритм обладает мощными возможностями передачи динамиков и стиля.
Демо -результаты
Бумажная ссылка
Записная книжка Colab настоятельно рекомендуется для тестирования.
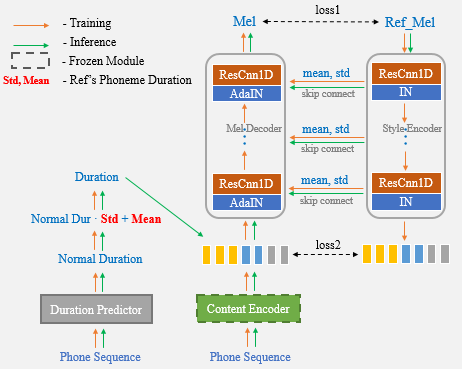
Теперь вам нужно только использовать справочную речь для одноразового клонирования голоса и больше не нужно вручную вводить статистику продолжительности дополнительно.
? Авторы готовит простой, четкий и хорошо документированный учебный процесс UNET-TTS на основе Aishell3.
Он содержит:
Следите за обновлениями!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)Вариант 1: Измените ссылочный аудиофайл, который будет клонирован в файле unettts_syn.py. (См. Этот файл для более подробной информации)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyВариант 2: ноутбук
Примечание . Пожалуйста, добавьте путь к клонированию с одним выстрелом в системный путь. В противном случае требуемый класс Unettts не может быть импортирован из файла unettts_syn.py.
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-cloning


