One Shot Voice Cloning
1.0.0
Inglês | 中文
❗ Agora, fornecemos modelos de código e pré-treinamento. Você pode gerar qualquer sons de texto que desejar.
O treinamento do modelo usa apenas o corpus da emoção neutra e não usa nenhum discurso fortemente emocional.
Ainda existem grandes desafios na transferência de estilo fora do domínio. Limitado pelo corpus de treinamento, é difícil para os métodos de aprendizado de estilo de incorporação de alto-falante ou de estilo não supervisionado (como GST) imitar os dados invisíveis.
Com a ajuda da rede UNET e da Adain Cayer, nosso algoritmo proposto possui poderosos recursos de transferência de alto -falante e estilo.
Resultados da demonstração
Link em papel
O notebook COLAB é altamente recomendado para teste.
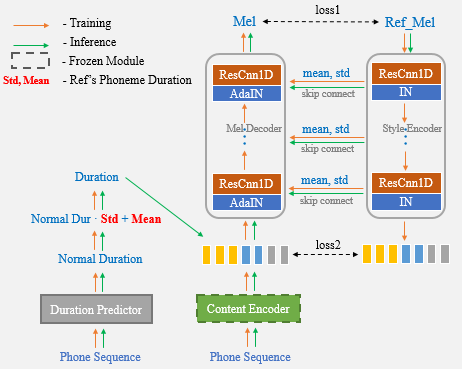
Agora, você só precisa usar o discurso de referência para a clonagem de voz de um tiro e não precisa mais inserir manualmente as estatísticas de duração adicionalmente.
? Os autores estão preparando o processo de treinamento simples, claro e bem documentado de UNET-TTS com base no Aishell3.
Ele contém:
Fique atento!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)Opção 1: Modifique o arquivo de áudio de referência a ser clonado no arquivo UNETTTS_SYN.PY. (Veja este arquivo para obter mais detalhes)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyOpção 2: Notebook
NOTA : Adicione o caminho de clonagem de uma viagem ao caminho do sistema. Caso contrário, a classe necessária unetts não poderá ser importada do arquivo UNETTTS_SYN.PY.
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-cloning


