One Shot Voice Cloning
1.0.0
Anglais | 中文
❗ Maintenant, nous fournissons du code d'inférence et des modèles de pré-formation. Vous pouvez générer des sons de texte que vous souhaitez.
La formation du modèle utilise uniquement le corpus d'émotion neutre et n'utilise aucun discours fortement émotionnel.
Il y a encore de grands défis dans le transfert de style hors du domaine. Limité par le corpus de formation, il est difficile pour les méthodes d'apprentissage de style ou de style non supervisé (comme la TPS) pour imiter les données invisibles.
Avec l'aide de UNET Network et Adain Layer, notre algorithme proposé a des capacités de transfert de haut-parleurs et de style puissantes.
Résultats de la démonstration
Lien papier
Le cahier Colab est fortement recommandé pour le test.
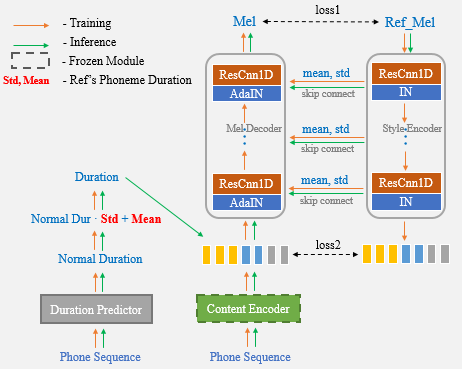
Maintenant, il vous suffit d'utiliser le discours de référence pour le clonage vocal à un coup et de ne plus saisir manuellement les statistiques de durée.
? Les auteurs préparent un processus de formation simple, clair et bien documenté de l'UNET-TTS basé sur Aishell3.
Il contient:
Restez à l'écoute!
cd One-Shot-Voice-Cloning/TensorFlowTTS
pip install .
(or python setup.py install)Option 1: Modifiez le fichier audio de référence à cloner dans le fichier unettts_syn.py. (Voir ce fichier pour plus de détails)
cd One-Shot-Voice-Cloning
CUDA_VISIBLE_DEVICES=0 python UnetTTS_syn.pyOption 2: cahier
Remarque : veuillez ajouter le chemin de clonage à voix unique vers le chemin du système. Sinon, la classe requise Unettts ne peut pas être importée du fichier unettts_syn.py.
import sys
sys . path . append ( "<your repository's parent directory>/One-Shot-Voice-Cloning" )
from UnetTTS_syn import UnetTTS
from tensorflow_tts . audio_process import preprocess_wav
"""Inint models"""
models_and_params = { "duration_param" : "train/configs/unetts_duration.yaml" ,
"duration_model" : "models/duration4k.h5" ,
"acous_param" : "train/configs/unetts_acous.yaml" ,
"acous_model" : "models/acous12k.h5" ,
"vocoder_param" : "train/configs/multiband_melgan.yaml" ,
"vocoder_model" : "models/vocoder800k.h5" }
feats_yaml = "train/configs/unetts_preprocess.yaml"
text2id_mapper = "models/unetts_mapper.json"
Tts_handel = UnetTTS ( models_and_params , text2id_mapper , feats_yaml )
"""Synthesize arbitrary text cloning voice using a reference speech"""
wav_fpath = "./reference_speech.wav"
ref_audio = preprocess_wav ( wav_fpath , source_sr = 16000 , normalize = True , trim_silence = True , is_sil_pad = True ,
vad_window_length = 30 ,
vad_moving_average_width = 1 ,
vad_max_silence_length = 1 )
# Inserting #3 marks into text is regarded as punctuation, and synthetic speech can produce pause.
text = "一句话#3风格迁移#3语音合成系统"
syn_audio , _ , _ = Tts_handel . one_shot_TTS ( text , ref_audio )https://github.com/tensorspeech/tensorflowtts
https://github.com/corentinj/real-time-voice-cloning


