character based cnn
English Model
Este repositorio contiene una implementación de Pytorch de una red neuronal convolucional a nivel de carácter para la clasificación de texto.
La arquitectura del modelo proviene de este documento: https://arxiv.org/pdf/1509.01626.pdf
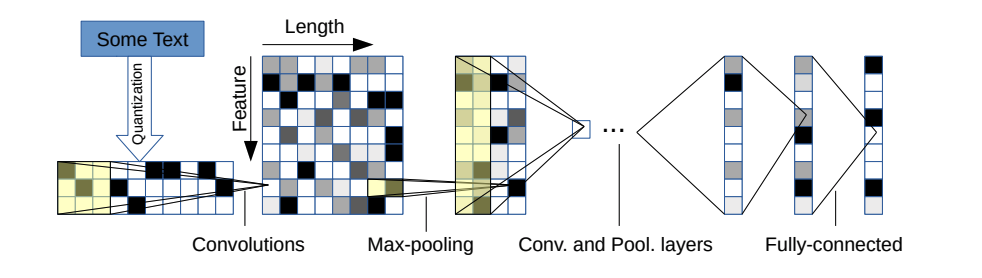
Hay dos variantes: una grande y una pequeña. Puede cambiar entre los dos cambiando el archivo de configuración.
Esta arquitectura tiene 6 capas convolucionales:
| Capa | Característica grande | Característica | Núcleo | Piscina |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N / A |
| 4 | 1024 | 256 | 3 | N / A |
| 5 | 1024 | 256 | 3 | N / A |
| 6 | 1024 | 256 | 3 | 3 |
y 2 capas totalmente conectadas:
| Capa | Unidades de salida grandes | Unidades de salida pequeñas |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | Depende del problema | Depende del problema |
Si está interesado en cómo funciona el personaje CNN, así como en la demostración de este proyecto, puede consultar mi video tutorial de YouTube.
Tienen muy buenas propiedades:
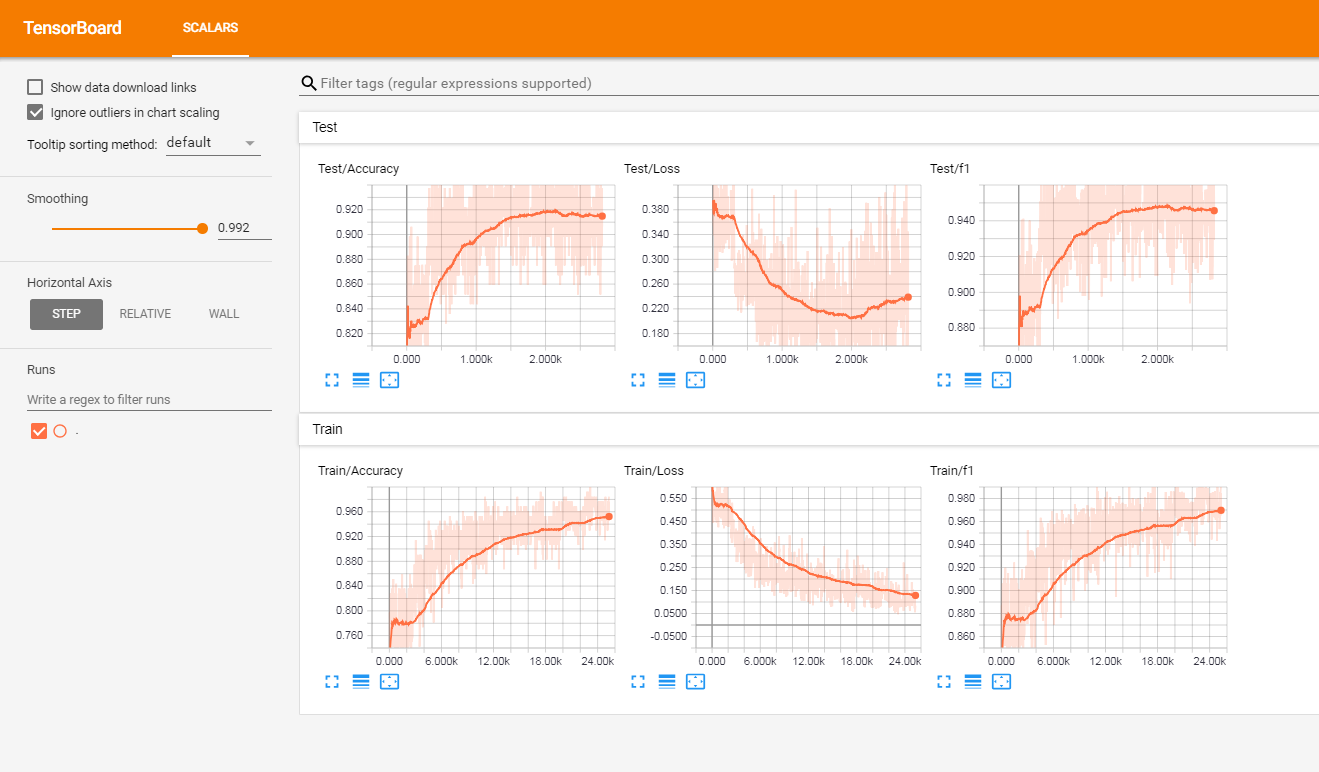
He probado este modelo en un conjunto de revisiones de clientes etiquetadas por francés (de más de 3 millones de filas). Informé las métricas en TensorBoardX.
Tengo los siguientes resultados
| Puntaje F1 | Exactitud | |
|---|---|---|
| tren | 0.965 | 0.9366 |
| prueba | 0.945 | 0.915 |
En la raíz del proyecto, tendrá:
El código actualmente funciona solo en etiquetas binarias (0/1)
Lanzar trenes.py con los siguientes argumentos:
data_path : ruta de los datos. Los datos deben estar en formato CSV con al menos una columna para el texto y una columna para la etiquetavalidation_split : la relación de los datos de validación. predeterminado a 0.2label_column : nombre de columna de las etiquetastext_column : nombre de columna de los textosmax_rows : el número máximo de filas para cargar desde el conjunto de datos. (Principalmente uso esto para las pruebas para ir más rápido)chunksize : tamaño de los fragmentos al cargar los datos usando pandas. predeterminado a 500000encoding : predeterminado a UTF-8steps : preprocesamiento de texto Pasos para incluir en el texto como el hashtag o la eliminación de URLgroup_labels : si a las etiquetas agrupar o no. Predeterminado a ninguno.use_sampler : si usa o no un muestreador ponderado para superar el desequilibrio de clasesalphabet : predeterminado a abcdefghijklmnopqrstuvwxyz0123456789,;.number_of_characters : predeterminado 70extra_characters : caracteres adicionales que agregarías al alfabeto. Por ejemplo, letras mayúsculas o caracteres acentuadosmax_length : la longitud máxima para arreglar todos los documentos. predeterminado a 150 pero debe adaptarse a sus datosepochs : número de épocasbatch_size : tamaño por lotes, predeterminado a 128.optimizer : Adam o SGD, predeterminado a SGDlearning_rate : predeterminado a 0.01class_weights : si usar pesos de clase o no en la pérdida de entropía cruzadafocal_loss : si usar o no la pérdida focalgamma : parámetro gamma de la pérdida focal. predeterminado a 2alpha : parámetro alfa de la pérdida focal. predeterminado a 0.25schedule : Número de épocas por las cuales la tasa de aprendizaje disminuye a la mitad (la programación de la tasa de aprendizaje solo funciona para SGD), predeterminado a 3. Configurarlo en 0 para deshabilitarlapatience : número máximo de épocas para esperar sin mejorar la pérdida de validación, por defecto a 3early_stopping : para elegir si detiene o no el entrenamiento temprano. predeterminado a 0. Establecer en 1 para habilitarlo.checkpoint : para elegir guardar el modelo en el disco o no. predeterminado en 1, establecer en 0 para deshabilitar el punto de control del modeloworkers : Número de trabajadores en Pytorch dataLoader, predeterminado a 1log_path : ruta del archivo de registro de TensorBoardoutput : ruta de la carpeta donde se guardan los modelosmodel_name : nombre de prefijo de modelos guardadosEjemplo de uso:
python train.py --data_path=/data/tweets.csv --max_rows=200000Ejecute este comando en la raíz del proyecto:
tensorboard --logdir=./logs/ --port=6006Luego vaya a: http: // localhost: 6006 (o cualquier host que esté usando)
Iniciar Predict.py con los siguientes argumentos:
model : ruta del modelo previamente capacitadotext : texto de entradasteps : Lista de pasos de preprocesamiento, predeterminado a bajaalphabet : predeterminado a 'abcdefghijklmnopqrstuvwxyz0123456789-,;.number_of_characters : predeterminado a 70extra_characters : caracteres adicionales que agregarías al alfabeto. Por ejemplo, letras mayúsculas o caracteres acentuadosmax_length : la longitud máxima para arreglar todos los documentos. predeterminado a 150 pero debe adaptarse a sus datosEjemplo de uso:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
Modelo de análisis de sentimientos en revisiones de clientes franceses (documentos de 3M): Descargar enlace
Al usarlo:
Aquí hay una lista no exhaustiva de posibles características futuras para agregar:
Este proyecto tiene licencia bajo la licencia MIT


