character based cnn
English Model
该回购包含用于文本分类的角色级卷积神经网络的pytorch实现。
模型架构来自本文:https://arxiv.org/pdf/1509.01626.pdf
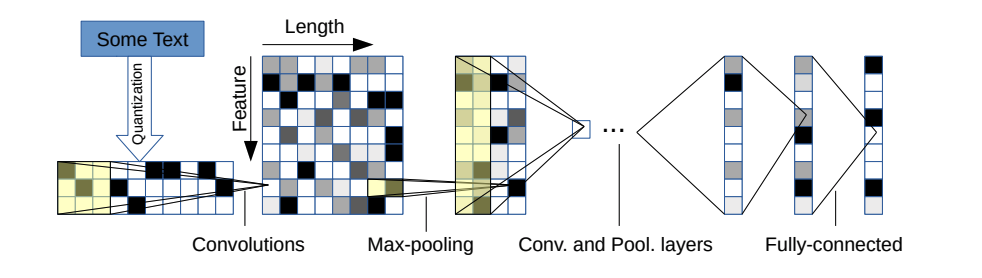
有两个变体:一个大和小。您可以通过更改配置文件在两者之间切换。
该体系结构有6个卷积层:
| 层 | 大型功能 | 小功能 | 核心 | 水池 |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N/A。 |
| 4 | 1024 | 256 | 3 | N/A。 |
| 5 | 1024 | 256 | 3 | N/A。 |
| 6 | 1024 | 256 | 3 | 3 |
和2个完全连接的层:
| 层 | 输出单位大 | 输出单元很小 |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | 取决于问题 | 取决于问题 |
如果您对角色CNN的工作方式以及该项目的演示感兴趣,则可以查看我的YouTube视频教程。
他们的特性非常好:
我已经在一组法国标记的客户评论(超过300万行)上测试了该模型。我报告了TensorboardX中的指标。
我得到以下结果
| F1得分 | 准确性 | |
|---|---|---|
| 火车 | 0.965 | 0.9366 |
| 测试 | 0.945 | 0.915 |
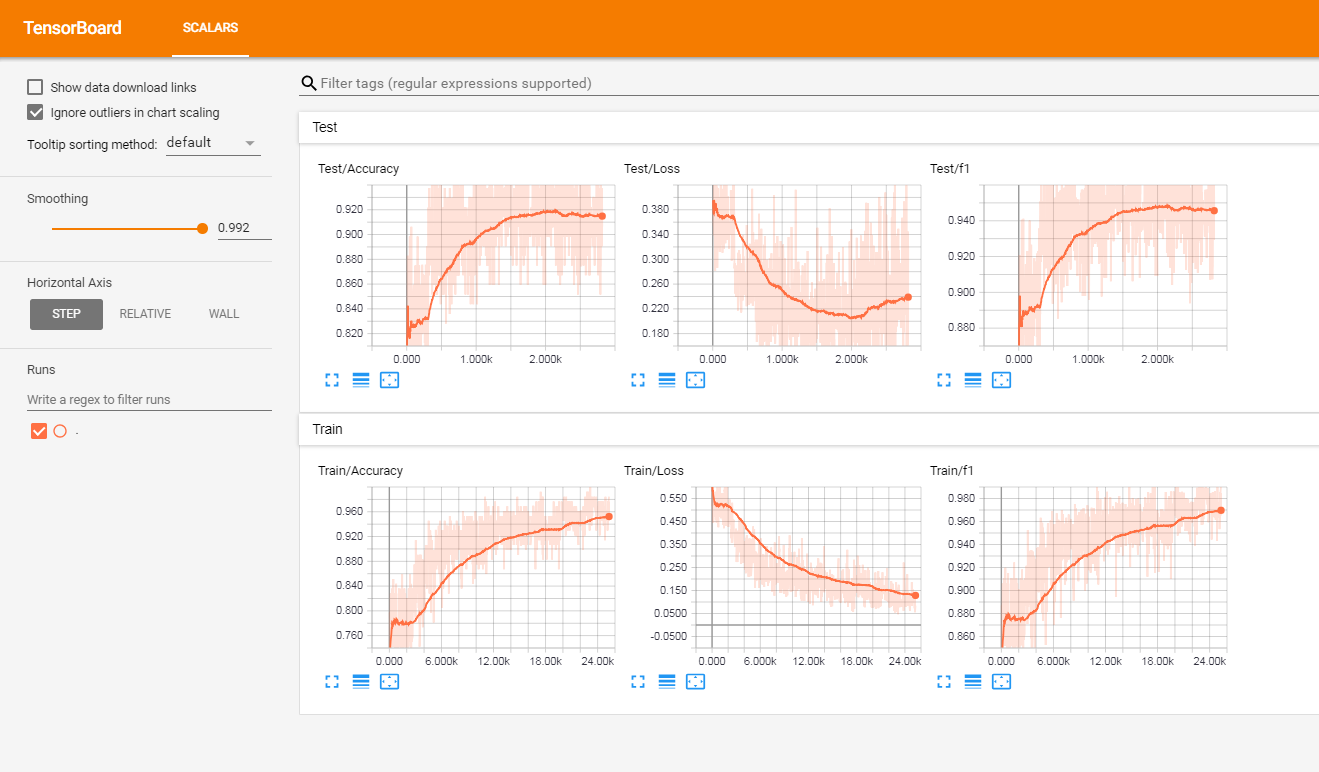
从项目的根源上,您将拥有:
该代码当前仅在二进制标签(0/1)上工作
启动train.py带有以下论点:
data_path :数据路径。数据应为CSV格式,至少具有文本列,并且标签的列validation_split :验证数据的比率。默认为0.2label_column :标签的列名称text_column :文本的列名称max_rows :从数据集加载的最大行数。 (我主要将其用于测试以进行更快)chunksize :使用熊猫加载数据时的块大小。默认为500000encoding :默认为UTF-8steps :文本预处理步骤,以将其包含在标签或URL删除等文本中group_labels :是否要组标签。默认为无。use_sampler :是否使用加权采样器克服班级失衡alphabet :默认为Abcdefghijklmnopqrstuvwxyz0123456789;。!?:'number_of_characters :默认70extra_characters :您要添加到字母的其他字符。例如大写字母或重音字符max_length :用于修复所有文档的最大长度。默认为150,但应适应您的数据epochs :时代的数量batch_size :批次大小,默认为128。optimizer :Adam或SGD,默认为SGDlearning_rate :默认为0.01class_weights :是否在交叉熵损失中使用班级权重focal_loss :是否使用焦点损失gamma :局灶性损失的伽马参数。默认为2alpha :局灶性损失的α参数。默认为0.25schedule :学习率降低一半的时期数(学习率计划仅适用于SGD),默认为3。将其设置为0以将其禁用patience :最大数量的时期数量等待而无需改善验证损失,默认为3early_stopping :选择是否早日停止培训。默认为0。设置为1以启用它。checkpoint :选择是否将模型保存在磁盘上。默认为1,设置为0至禁用模型检查点workers :Pytorch数据加载程序中的工人人数,默认为1log_path :张板的路径日志文件output :保存模型的文件夹的路径model_name :保存模型的前缀名称示例用法:
python train.py --data_path=/data/tweets.csv --max_rows=200000以项目的根源运行此命令:
tensorboard --logdir=./logs/ --port=6006然后转到:http:// localhost:6006(或您使用的任何主机)
启动预测。
model :预训练模型的路径text :输入文字steps :预处理步骤列表,默认为较低alphabet :默认为'abcdefghijklmnopqrstuvwxyz0123456789 - ;。!?number_of_characters :默认为70extra_characters :您要添加到字母的其他字符。例如大写字母或重音字符max_length :用于修复所有文档的最大长度。默认为150,但应适应您的数据示例用法:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
关于法国客户评论(3M文档)的情感分析模型:下载链接
使用时:
这是要添加的潜在未来功能的非详尽清单:
该项目已根据麻省理工学院许可证


