character based cnn
English Model
Dieses Repo enthält eine Pytorch-Implementierung eines Faltungsnetzes auf Charakterebene für die Textklassifizierung.
Die Modellarchitektur stammt aus diesem Artikel: https://arxiv.org/pdf/1509.01626.pdf
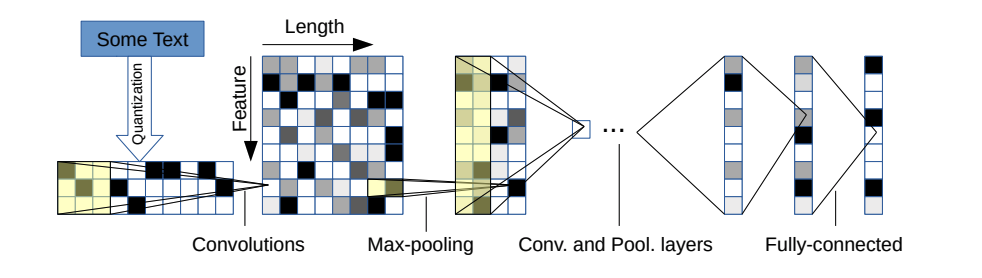
Es gibt zwei Varianten: eine große und eine kleine. Sie können zwischen den beiden wechseln, indem Sie die Konfigurationsdatei ändern.
Diese Architektur hat 6 Faltungsschichten:
| Schicht | Großes Merkmal | Kleines Merkmal | Kernel | Pool |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N / A |
| 4 | 1024 | 256 | 3 | N / A |
| 5 | 1024 | 256 | 3 | N / A |
| 6 | 1024 | 256 | 3 | 3 |
und 2 vollständig verbundene Schichten:
| Schicht | Ausgangseinheiten groß | Ausgabeeinheiten klein |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | Hängt vom Problem ab | Hängt vom Problem ab |
Wenn Sie daran interessiert sind, wie Charakter CNN und in der Demo dieses Projekts funktioniert, können Sie mein YouTube -Video -Tutorial überprüfen.
Sie haben sehr schöne Eigenschaften:
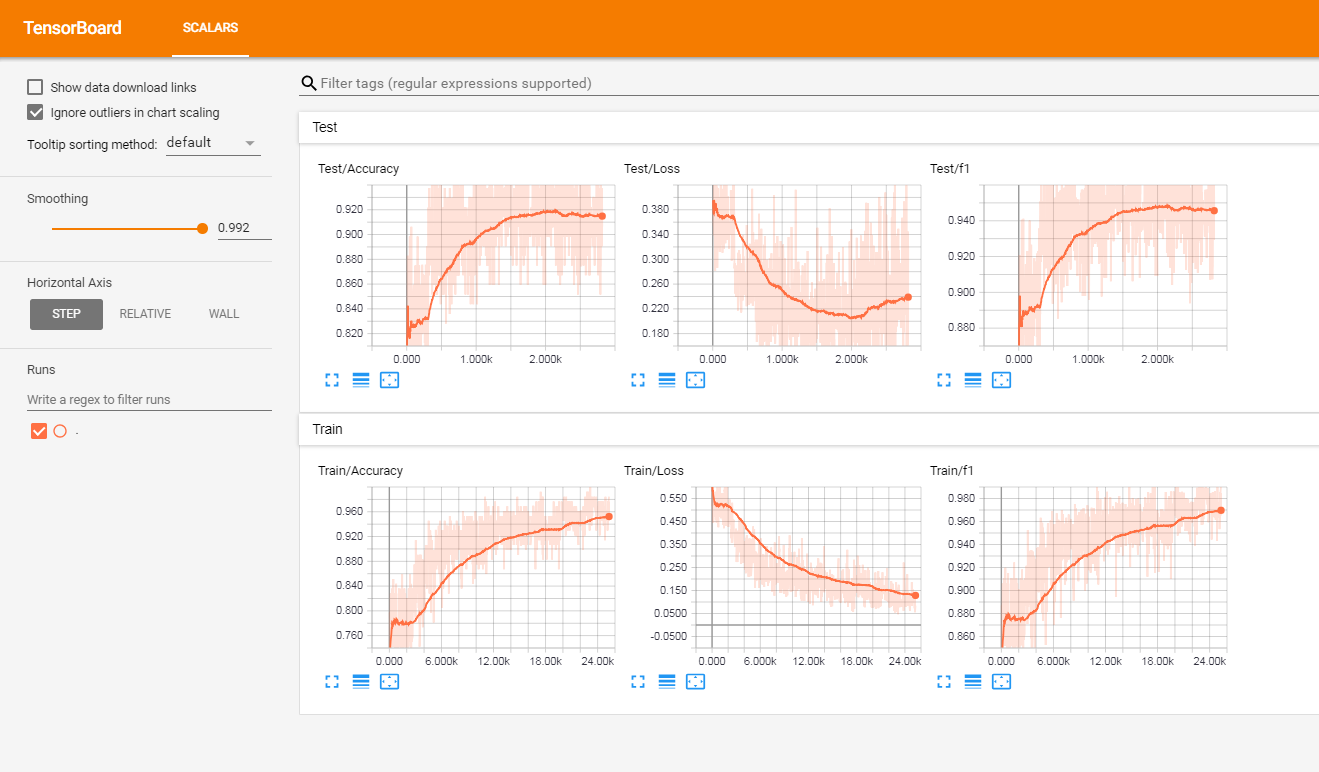
Ich habe dieses Modell auf einer Reihe von französischen Kundbewertungen (von über 3 Millionen Zeilen) getestet. Ich habe die Metriken in Tensorboardx gemeldet.
Ich habe die folgenden Ergebnisse bekommen
| F1 -Punktzahl | Genauigkeit | |
|---|---|---|
| Zug | 0,965 | 0,9366 |
| prüfen | 0,945 | 0,915 |
Am Projekt haben Sie: Sie haben:
Der Code funktioniert derzeit nur auf binären Etiketten (0/1)
Starten Sie Train.py mit den folgenden Argumenten:
data_path : Pfad der Daten. Die Daten sollten im CSV -Format mit mindestens einer Spalte für Text und einer Spalte für die Beschriftung erfolgenvalidation_split : Das Verhältnis der Validierungsdaten. Standard auf 0,2label_column : Spaltenname der Etikettentext_column : Spaltenname der Textemax_rows : Die maximale Anzahl von Zeilen, die aus dem Datensatz geladen werden müssen. (Ich benutze dies hauptsächlich, damit das Testen schneller wird.)chunksize : Größe der Stücke beim Laden der Daten mit Pandas. Standard auf 500000encoding : Standard zu UTF-8steps : Textvorverarbeitungsschritte, die in den Text wie Hashtag oder URL -Entfernung aufgenommen werden sollengroup_labels : Ob Sie Beschriftungen gruppieren oder nicht. Standardmäßig keine.use_sampler : Ob Sie einen gewichteten Sampler verwenden möchten oder nicht, um das Ungleichgewicht des Klassenunterschieds zu überwindenalphabet : Standard zu AbcDefghijklMnopqrstuvwxyz0123456789,;number_of_characters : Standard 70extra_characters : Zusätzliche Zeichen, die Sie dem Alphabet hinzufügen würden. Zum Beispiel Großbuchstaben oder Akzentzeichenmax_length : Die maximale Länge, die für alle Dokumente festgelegt werden soll. Standard auf 150, sollte aber an Ihre Daten angepasst werdenepochs : Anzahl der Epochenbatch_size : Stapelgröße, Standard bis 128.optimizer : Adam oder SGD, Standard an SGDlearning_rate : Standard auf 0.01class_weights : ob du Klassengewichte im Cross -Entropy -Verlust anwenden soll oder nichtfocal_lossgamma : Gamma -Parameter des Schwerpunktverlusts. Standard auf 2alpha : Alpha -Parameter des Fokusverlusts. Standard auf 0,25schedule : Anzahl der Epochen, mit denen die Lernrate um die Hälfte abnimmt (Lernrateplanung funktioniert nur für SGD), standardmäßig auf 3. Stellen Sie es auf 0 ein, um sie zu deaktivierenpatience : Maximale Anzahl von Epochen, um ohne Verbesserung des Validierungsverlusts zu warten, Standard auf 3early_stopping : Um zu wählen, ob das Training frühzeitig eingestellt werden soll oder nicht. Standard auf 0. Setzen Sie auf 1, um es zu aktivieren.checkpoint : Um das Modell auf der Festplatte zu speichern oder nicht. Standard auf 1, auf 0 festlegen, um den Modell -Checkpoint für den Modell zu deaktivierenworkers : Anzahl der Arbeitnehmer in Pytorch Dataloader, Standard auf 1log_path : Pfad der Tensorboard -Protokolldateioutput : Pfad des Ordners, in dem Modelle gespeichert werdenmodel_name : Präfixname gespeicherter ModelleBeispiel Verwendung:
python train.py --data_path=/data/tweets.csv --max_rows=200000Führen Sie diesen Befehl zur Wurzel des Projekts aus:
tensorboard --logdir=./logs/ --port=6006Gehen Sie dann zu: http: // localhost: 6006 (oder welcher Host, den Sie verwenden)
Start Predict.py mit den folgenden Argumenten:
model : Pfad des vorgebildeten Modellstext : Text eingebensteps : Liste der Vorverarbeitungsschritte, standardmäßig nach niedrigeralphabet : Standard zu 'AbcDefghijklMnopqrstuvwxyz0123456789-,;number_of_characters : Standard zu 70extra_characters : Zusätzliche Zeichen, die Sie dem Alphabet hinzufügen würden. Zum Beispiel Großbuchstaben oder Akzentzeichenmax_length : Die maximale Länge, die für alle Dokumente festgelegt werden soll. Standard auf 150, sollte aber an Ihre Daten angepasst werdenBeispiel Verwendung:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
Modellanalysemodell für französische Kundenbewertungen (3M -Dokumente): Link herunterladen
Wenn Sie es verwenden:
Hier ist eine nicht exexhustive Liste potenzieller zukünftiger Funktionen, die hinzugefügt werden sollen:
Dieses Projekt ist unter der MIT -Lizenz lizenziert


