character based cnn
English Model
repo นี้มีการใช้งาน pytorch ของเครือข่ายประสาทเทียมระดับอักขระสำหรับการจำแนกข้อความ
สถาปัตยกรรมโมเดลมาจากบทความนี้: https://arxiv.org/pdf/1509.01626.pdf
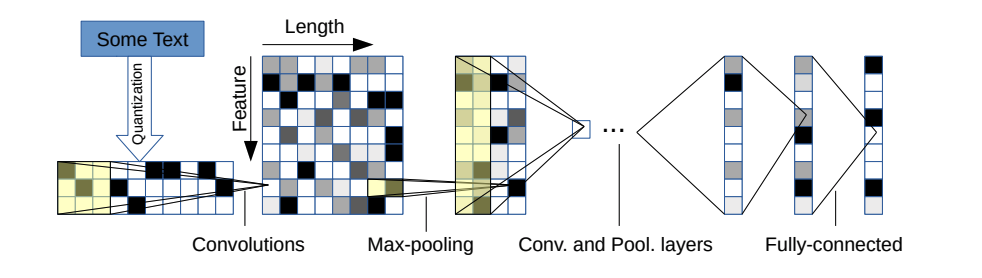
มีสองตัวแปร: ขนาดใหญ่และเล็ก คุณสามารถสลับระหว่างทั้งสองได้โดยการเปลี่ยนไฟล์การกำหนดค่า
สถาปัตยกรรมนี้มี 6 ชั้น convolutional:
| ชั้น | คุณสมบัติขนาดใหญ่ | ฟีเจอร์ขนาดเล็ก | เคอร์เนล | สระน้ำ |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N/A |
| 4 | 1024 | 256 | 3 | N/A |
| 5 | 1024 | 256 | 3 | N/A |
| 6 | 1024 | 256 | 3 | 3 |
และ 2 เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์:
| ชั้น | หน่วยเอาท์พุทขนาดใหญ่ | หน่วยเอาท์พุทขนาดเล็ก |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | ขึ้นอยู่กับปัญหา | ขึ้นอยู่กับปัญหา |
หากคุณสนใจว่าตัวละคร CNN ทำงานอย่างไรและในการสาธิตของโครงการนี้คุณสามารถตรวจสอบการสอนวิดีโอ YouTube ของฉันได้
พวกเขามีคุณสมบัติที่ดีมาก:
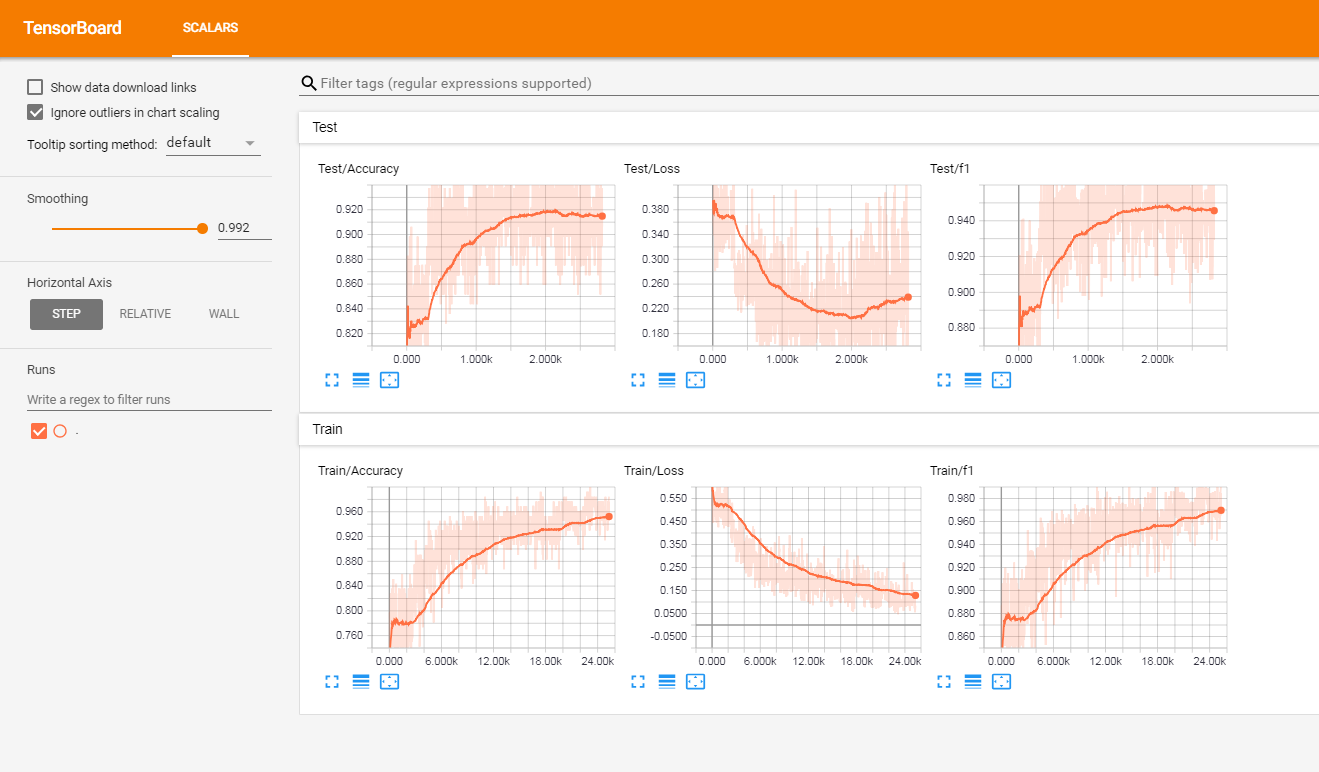
ฉันได้ทดสอบโมเดลนี้ในชุดบทวิจารณ์ของลูกค้าที่มีป้ายกำกับภาษาฝรั่งเศส (มากกว่า 3 ล้านแถว) ฉันรายงานตัวชี้วัดใน TensorboardX
ฉันได้ผลลัพธ์ต่อไปนี้
| คะแนน F1 | ความแม่นยำ | |
|---|---|---|
| รถไฟ | 0.965 | 0.9366 |
| ทดสอบ | 0.945 | 0.915 |
ที่รากของโครงการคุณจะมี:
รหัสนี้ใช้งานได้เฉพาะบนป้ายกำกับไบนารี (0/1)
Launch Train.py พร้อมข้อโต้แย้งต่อไปนี้:
data_path : เส้นทางของข้อมูล ข้อมูลควรอยู่ในรูปแบบ CSV ที่มีคอลัมน์อย่างน้อยคอลัมน์สำหรับข้อความและคอลัมน์สำหรับฉลากvalidation_split : อัตราส่วนของข้อมูลการตรวจสอบความถูกต้อง ค่าเริ่มต้นเป็น 0.2label_column : ชื่อคอลัมน์ของป้ายกำกับtext_column : ชื่อคอลัมน์ของข้อความmax_rows : จำนวนแถวสูงสุดที่จะโหลดจากชุดข้อมูล (ฉันใช้สิ่งนี้เป็นหลักในการทดสอบเพื่อไปเร็วขึ้น)chunksize : ขนาดของชิ้นเมื่อโหลดข้อมูลโดยใช้แพนด้า ค่าเริ่มต้นเป็น 500000encoding : ค่าเริ่มต้นเป็น UTF-8steps : ขั้นตอนการประมวลผลข้อความล่วงหน้าเพื่อรวมไว้ในข้อความเช่นแฮชแท็กหรือการลบ URLgroup_labels : ไม่ว่าจะเป็นกลุ่มฉลากหรือไม่ ค่าเริ่มต้นเป็นไม่มีuse_sampler : ไม่ว่าจะใช้ตัวอย่างถ่วงน้ำหนักเพื่อเอาชนะความไม่สมดุลของชั้นเรียนหรือไม่alphabet : ค่าเริ่มต้นเป็น abcdefghijklmnopqrstuvwxyz0123456789,.!?: '"/ | _@#$%^&*~`+-= <> () [] {}number_of_characters : ค่าเริ่มต้น 70extra_characters : อักขระเพิ่มเติมที่คุณจะเพิ่มลงในตัวอักษร ตัวอย่างเช่นตัวอักษรตัวพิมพ์ใหญ่หรืออักขระที่เน้นเสียงmax_length : ความยาวสูงสุดในการแก้ไขสำหรับเอกสารทั้งหมด ค่าเริ่มต้นเป็น 150 แต่ควรปรับให้เข้ากับข้อมูลของคุณepochs : จำนวนยุคbatch_size : ขนาดแบทช์เริ่มต้นที่ 128optimizer : Adam หรือ SGD, ค่าเริ่มต้นเป็น SGDlearning_rate : ค่าเริ่มต้นเป็น 0.01class_weights : ไม่ว่าจะใช้น้ำหนักคลาสในการสูญเสียเอนโทรปีข้ามหรือไม่focal_loss : ไม่ว่าจะใช้การสูญเสียโฟกัสหรือไม่gamma : พารามิเตอร์แกมม่าของการสูญเสียโฟกัส ค่าเริ่มต้นเป็น 2alpha : พารามิเตอร์อัลฟ่าของการสูญเสียโฟกัส ค่าเริ่มต้นเป็น 0.25schedule : จำนวนยุคที่อัตราการเรียนรู้ลดลงครึ่งหนึ่ง (การจัดตารางอัตราการเรียนรู้ใช้งานได้สำหรับ SGD เท่านั้น), เริ่มต้นเป็น 3. ตั้งค่าเป็น 0 เพื่อปิดการใช้งานpatience : จำนวนสูงสุดของยุคที่จะรอโดยไม่ต้องปรับปรุงการสูญเสียการตรวจสอบความถูกต้องเริ่มต้นเป็น 3early_stopping : เพื่อเลือกว่าจะหยุดการฝึกอบรมก่อนหรือไม่ ค่าเริ่มต้นเป็น 0. ตั้งค่าเป็น 1 เพื่อเปิดใช้งานcheckpoint : เพื่อเลือกที่จะบันทึกโมเดลบนดิสก์หรือไม่ ค่าเริ่มต้นเป็น 1 ตั้งค่าเป็น 0 เป็นจุดตรวจสอบรุ่นworkers : จำนวนคนงานใน Pytorch Dataloader, ค่าเริ่มต้นเป็น 1log_path : เส้นทางของไฟล์บันทึก Tensorboardoutput : เส้นทางของโฟลเดอร์ที่มีการบันทึกแบบจำลองmodel_name : ชื่อคำนำหน้าของรุ่นที่บันทึกไว้ตัวอย่างการใช้งาน:
python train.py --data_path=/data/tweets.csv --max_rows=200000เรียกใช้คำสั่งนี้ที่รูทของโครงการ:
tensorboard --logdir=./logs/ --port=6006จากนั้นไปที่: http: // localhost: 6006 (หรือโฮสต์อะไรก็ตามที่คุณใช้)
เปิดตัว Predict.py พร้อมข้อโต้แย้งต่อไปนี้:
model : เส้นทางของโมเดลที่ผ่านการฝึกอบรมมาก่อนtext : อินพุตข้อความsteps : รายการขั้นตอนการประมวลผลล่วงหน้าค่าเริ่มต้นถึงต่ำกว่าalphabet : ค่าเริ่มต้นเป็น 'abcdefghijklmnopqrstuvwxyz0123456789-,;.!?:' "/| _@#$%^&*`+-= <> () [] {} n 'number_of_characters : ค่าเริ่มต้นถึง 70extra_characters : อักขระเพิ่มเติมที่คุณจะเพิ่มลงในตัวอักษร ตัวอย่างเช่นตัวอักษรตัวพิมพ์ใหญ่หรืออักขระที่เน้นเสียงmax_length : ความยาวสูงสุดในการแก้ไขสำหรับเอกสารทั้งหมด ค่าเริ่มต้นเป็น 150 แต่ควรปรับให้เข้ากับข้อมูลของคุณตัวอย่างการใช้งาน:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
รูปแบบการวิเคราะห์ความเชื่อมั่นในบทวิจารณ์ลูกค้าฝรั่งเศส (เอกสาร 3M): ลิงค์ดาวน์โหลด
เมื่อใช้งาน:
นี่คือรายการที่ไม่ครบถ้วนของคุณสมบัติในอนาคตที่จะเพิ่ม:
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต MIT


