character based cnn
English Model
이 repo에는 텍스트 분류를위한 문자 수준 컨볼 루션 신경 네트워크의 Pytorch 구현이 포함되어 있습니다.
모델 아키텍처는이 논문에서 나옵니다 : https://arxiv.org/pdf/1509.01626.pdf
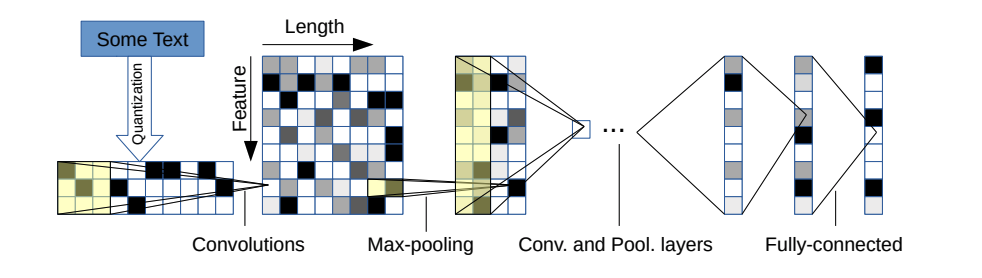
크고 작은 두 가지 변형이 있습니다. 구성 파일을 변경하여 둘을 전환 할 수 있습니다.
이 아키텍처에는 6 개의 컨볼 루션 레이어가 있습니다.
| 층 | 큰 기능 | 작은 기능 | 핵심 | 수영장 |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N/A |
| 4 | 1024 | 256 | 3 | N/A |
| 5 | 1024 | 256 | 3 | N/A |
| 6 | 1024 | 256 | 3 | 3 |
2 개의 완전히 연결된 레이어 :
| 층 | 출력 단위가 크다 | 출력 단위가 작습니다 |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | 문제에 따라 다릅니다 | 문제에 따라 다릅니다 |
이 프로젝트의 데모뿐만 아니라 캐릭터 CNN이 어떻게 작동하는지에 관심이 있다면 YouTube 비디오 자습서를 확인할 수 있습니다.
그들은 매우 좋은 속성을 가지고 있습니다.
프랑스 라벨이 붙은 고객 리뷰 세트 (3 백만 행 이상) 에서이 모델을 테스트했습니다. Tensorboardx에서 메트릭을보고했습니다.
다음 결과를 얻었습니다
| F1 점수 | 정확성 | |
|---|---|---|
| 기차 | 0.965 | 0.9366 |
| 시험 | 0.945 | 0.915 |
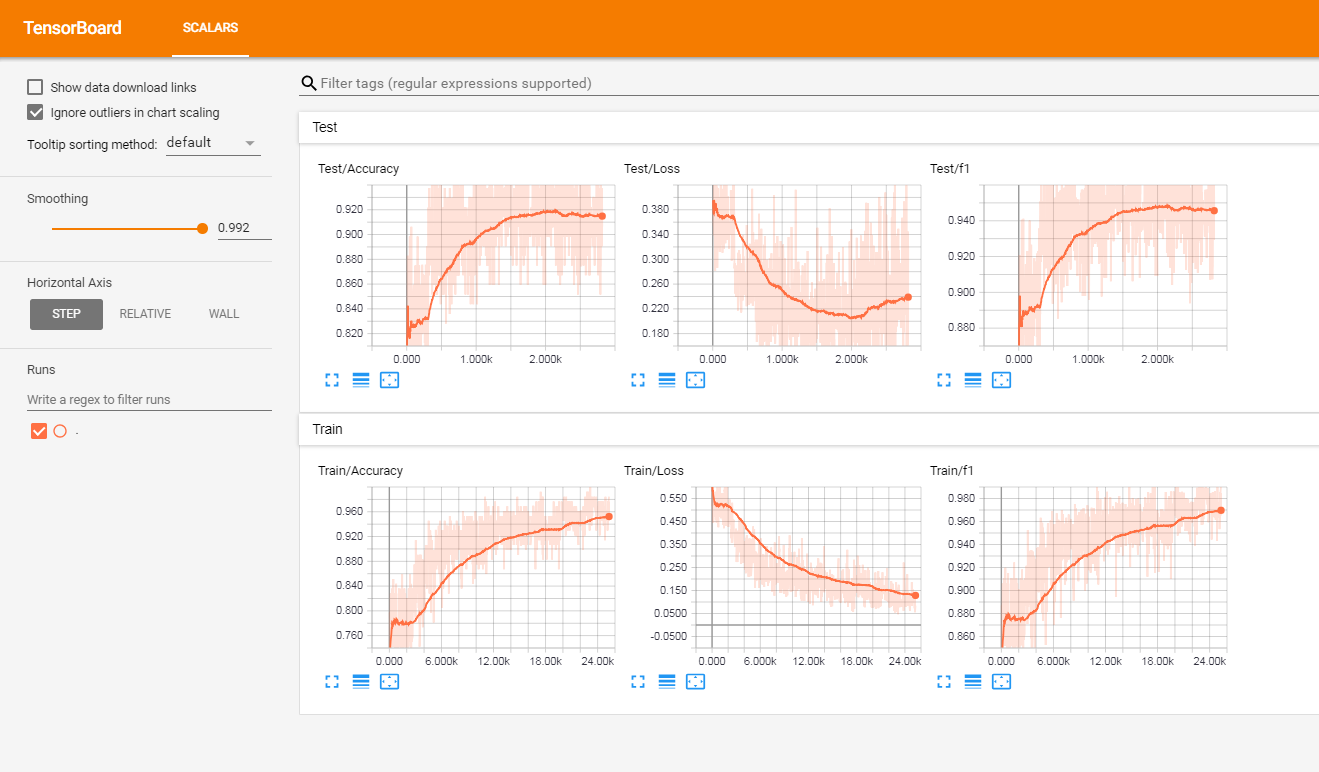
프로젝트의 근본 원인에는 다음과 같습니다.
코드는 현재 이진 레이블 (0/1)에서만 작동합니다.
다음 논쟁과 함께 Train.py를 시작하십시오.
data_path : 데이터 경로. 데이터는 텍스트의 열이 최소한 CSV 형식이고 레이블의 열이 있어야합니다.validation_split : 유효성 검사 데이터의 비율. 기본값 0.2label_column : 라벨의 열 이름text_column : 텍스트의 열 이름max_rows : 데이터 세트에서로드 할 최대 행 수입니다. (테스트가 더 빨리 테스트하기 위해 이것을 주로 사용합니다)chunksize : 팬더를 사용하여 데이터를로드 할 때 청크의 크기. 기본값은 500000입니다encoding : UTF-8에 대한 기본값steps : 해시 태그 또는 URL 제거와 같은 텍스트에 포함시키는 텍스트 전처리 단계group_labels : 레이블 그룹의 여부. 기본값이 없습니다.use_sampler : 가중 샘플러를 사용하여 클래스 불균형을 극복할지 여부alphabet : abcdefghijklmnopqrstuvwxyz0123456789,;.number_of_characters : 기본 70extra_characters : 알파벳에 추가 할 추가 문자. 예를 들어 대문자 또는 악센트 캐릭터max_length : 모든 문서에 대해 수정하는 최대 길이. 기본값은 150이지만 데이터에 적합해야합니다.epochs : 에포크 수batch_size : 배치 크기, 기본값은 128입니다.optimizer : Adam 또는 SGD, SGD의 기본값learning_rate : 기본값 0.01class_weights : 크로스 엔트로피 손실에서 클래스 가중치를 사용할지 여부focal_loss : 초점 손실 사용 여부gamma : 초점 손실의 감마 매개 변수. 기본값 2alpha : 초점 손실의 알파 매개 변수. 기본값 0.25schedule : 학습 속도가 절반으로 감소하는 에포크 수 (학습 속도 스케줄링은 SGD에 대해서만 작동 함), 기본값 3에서 3을 비활성화하려면 0으로 설정합니다.patience : 유효성 검사 손실의 개선없이 대기 할 최대 에포크 수, 기본값 3early_stopping : 조기 훈련을 중지할지 여부를 선택합니다. 기본값 0에서 1로 설정하여 활성화하십시오.checkpoint : 디스크에 모델을 저장하도록 선택합니다. 기본값 1, 0으로 설정하여 모델 체크 포인트를 비활성화합니다.workers : Pytorch Dataloader의 근로자 수, 기본값 1log_path : Tensorboard 로그 파일의 경로output : 모델이 저장되는 폴더의 경로model_name : 저장된 모델의 접두사 이름예제 사용 :
python train.py --data_path=/data/tweets.csv --max_rows=200000프로젝트의 루트 에서이 명령을 실행하십시오.
tensorboard --logdir=./logs/ --port=6006그런 다음 이동 : http : // localhost : 6006 (또는 사용중인 호스트)
다음 인수와 함께 예측 .py를 시작하십시오.
model : 미리 훈련 된 모델의 경로text : 입력 텍스트steps : 전처리 단계 목록, 기본값은 더 낮습니다alphabet : 'abcdefghijklmnopqrstuvwxyz0123456789-,;.!?number_of_characters : 기본값은 70입니다extra_characters : 알파벳에 추가 할 추가 문자. 예를 들어 대문자 또는 악센트 캐릭터max_length : 모든 문서에 대해 수정하는 최대 길이. 기본값은 150이지만 데이터에 적합해야합니다.예제 사용 :
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
프랑스 고객 리뷰에 대한 감정 분석 모델 (3M 문서) : 다운로드 링크
그것을 사용할 때 :
다음은 추가 할 수있는 잠재적 인 미래 기능의 비 유명한 목록입니다.
이 프로젝트는 MIT 라이센스에 따라 라이센스가 부여됩니다


