character based cnn
English Model
Repo ini berisi implementasi Pytorch dari jaringan saraf konvolusional tingkat karakter untuk klasifikasi teks.
Arsitektur model berasal dari makalah ini: https://arxiv.org/pdf/1509.01626.pdf
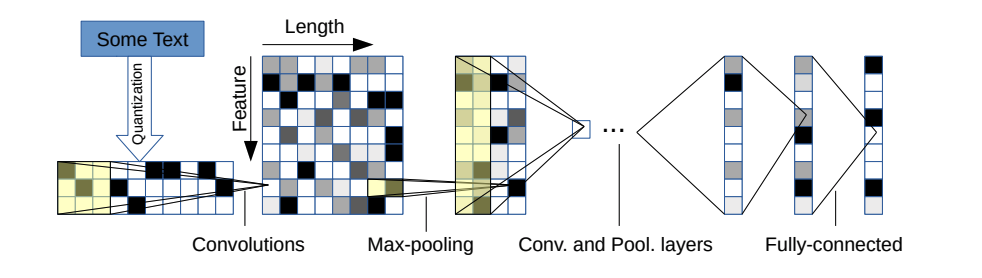
Ada dua varian: yang besar dan kecil. Anda dapat beralih di antara keduanya dengan mengubah file konfigurasi.
Arsitektur ini memiliki 6 lapisan konvolusional:
| Lapisan | Fitur besar | Fitur kecil | Inti | Kolam |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N/a |
| 4 | 1024 | 256 | 3 | N/a |
| 5 | 1024 | 256 | 3 | N/a |
| 6 | 1024 | 256 | 3 | 3 |
dan 2 lapisan yang sepenuhnya terhubung:
| Lapisan | Unit keluaran besar | Unit keluaran kecil |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | Tergantung masalahnya | Tergantung masalahnya |
Jika Anda tertarik pada cara kerja karakter CNN serta dalam demo proyek ini, Anda dapat memeriksa tutorial video YouTube saya.
Mereka memiliki properti yang sangat bagus:
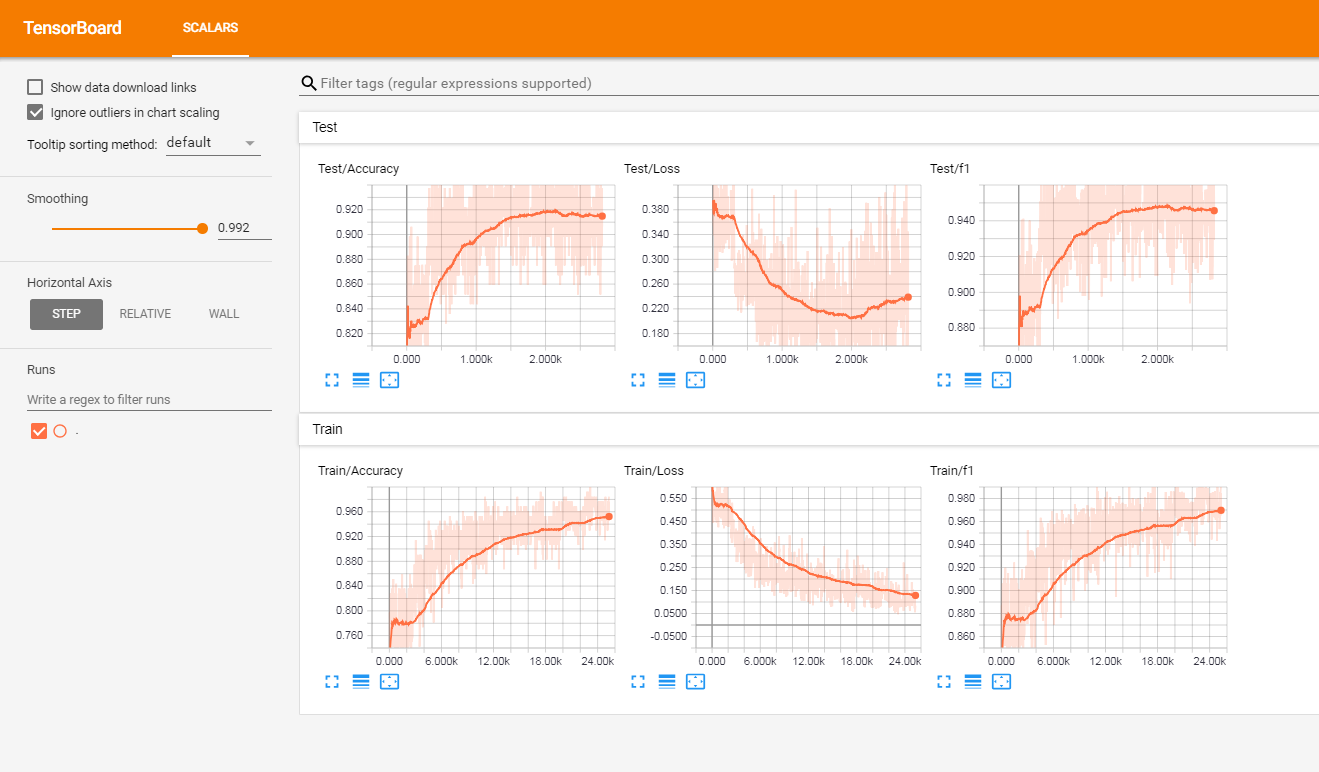
Saya telah menguji model ini pada satu set ulasan pelanggan berlabel Prancis (lebih dari 3 juta baris). Saya melaporkan metrik di Tensorboardx.
Saya mendapatkan hasil berikut
| Skor F1 | Ketepatan | |
|---|---|---|
| kereta | 0.965 | 0.9366 |
| tes | 0.945 | 0.915 |
Pada akar proyek, Anda akan memiliki:
Kode saat ini hanya berfungsi pada label biner (0/1)
Luncurkan Train.py dengan argumen berikut:
data_path : jalur data. Data harus dalam format CSV dengan setidaknya kolom untuk teks dan kolom untuk labelvalidation_split : Rasio data validasi. default ke 0,2label_column : Nama kolom labeltext_column : nama kolom teksmax_rows : Jumlah maksimum baris untuk dimuat dari dataset. (Saya terutama menggunakan ini untuk pengujian lebih cepat)chunksize : Ukuran potongan saat memuat data menggunakan panda. Default ke 500000encoding : Default ke UTF-8steps : Langkah -langkah Preprocessing Teks untuk disertakan pada teks seperti tagar atau penghapusan URLgroup_labels : Apakah untuk mengelompokkan label atau tidak. Default untuk tidak ada.use_sampler : Apakah menggunakan sampler tertimbang atau tidak untuk mengatasi ketidakseimbangan kelasalphabet : default ke abcdefghijklmnopqrstuvwxyz0123456789,;.!??: '"/ | _@#$%^&*~`+-= <> () [] {} (biasanya Anda tidak boleh memodifikasinya)number_of_characters : default 70extra_characters : Karakter tambahan yang akan Anda tambahkan ke alfabet. Misalnya huruf besar atau karakter beraksenmax_length : Panjang maksimum untuk memperbaiki semua dokumen. default ke 150 tetapi harus disesuaikan dengan data Andaepochs : Jumlah zamanbatch_size : ukuran batch, default ke 128.optimizer : Adam atau SGD, default ke SGDlearning_rate : default ke 0,01class_weights : Apakah menggunakan bobot kelas atau tidak dalam kehilangan entropi silangfocal_loss : apakah akan menggunakan kehilangan fokus atau tidakgamma : Parameter gamma dari kehilangan fokus. default ke 2alpha : Parameter alfa dari kehilangan fokus. default ke 0,25schedule : Jumlah zaman yang dengannya tingkat pembelajaran berkurang setengahnya (penjadwalan tingkat pembelajaran hanya berfungsi untuk SGD), default ke 3. Atur ke 0 untuk menonaktifkannyapatience : Jumlah maksimum zaman untuk menunggu tanpa peningkatan kerugian validasi, default ke 3early_stopping : Untuk memilih apakah akan menghentikan pelatihan lebih awal atau tidak. Default ke 0. Set ke 1 untuk mengaktifkannya.checkpoint : Untuk memilih untuk menyimpan model di disk atau tidak. Default ke 1, atur ke 0 untuk menonaktifkan pemeriksaan modelworkers : Jumlah pekerja di Pytorch Dataloader, default ke 1log_path : File log Path of Tensorboardoutput : jalur folder tempat model disimpanmodel_name : nama awalan model yang disimpanContoh Penggunaan:
python train.py --data_path=/data/tweets.csv --max_rows=200000Jalankan perintah ini di akar proyek:
tensorboard --logdir=./logs/ --port=6006Lalu pergi ke: http: // localhost: 6006 (atau host apa pun yang Anda gunakan)
Luncurkan Predict.py dengan argumen berikut:
model : jalur model pra-terlatihtext : Teks Inputsteps : Daftar langkah preprocessing, default ke bawahalphabet : default ke 'abcdefghijklmnopqrstuvwxyz0123456789-,;.!??:' "/| _@#$%^&*~`+-= <>) [] {} n 'number_of_characters : default ke 70extra_characters : Karakter tambahan yang akan Anda tambahkan ke alfabet. Misalnya huruf besar atau karakter beraksenmax_length : Panjang maksimum untuk memperbaiki semua dokumen. default ke 150 tetapi harus disesuaikan dengan data AndaContoh Penggunaan:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
Model Analisis Sentimen tentang Ulasan Pelanggan Prancis (Dokumen 3M): Tautan Unduh
Saat menggunakannya:
Berikut adalah daftar fitur potensial yang tidak lengkap untuk ditambahkan:
Proyek ini dilisensikan di bawah lisensi MIT


