character based cnn
English Model
Этот репо содержит внедрение Pytorch в сверточной нейронной сети на уровне символов для классификации текста.
Архитектура модели происходит от этой статьи: https://arxiv.org/pdf/1509.01626.pdf
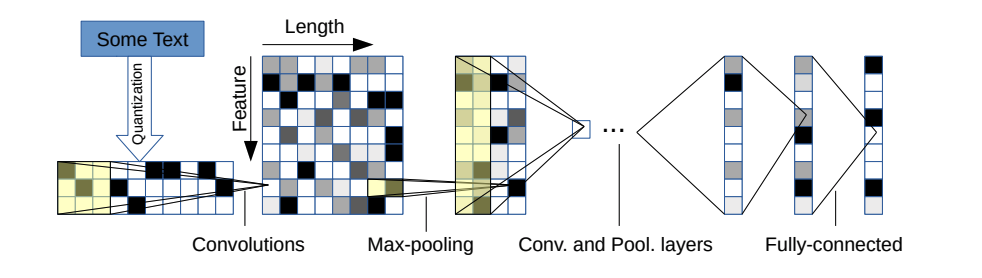
Есть два варианта: большой и маленький. Вы можете переключаться между ними, изменив файл конфигурации.
Эта архитектура имеет 6 сверточных слоев:
| Слой | Большая особенность | Небольшая особенность | Ядро | Бассейн |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N/a |
| 4 | 1024 | 256 | 3 | N/a |
| 5 | 1024 | 256 | 3 | N/a |
| 6 | 1024 | 256 | 3 | 3 |
и 2 полностью подключенных слоя:
| Слой | Выходные единицы большие | Выходные блоки маленькие |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | Зависит от проблемы | Зависит от проблемы |
Если вам интересно, как работает персонаж CNN, а также в демонстрации этого проекта, вы можете проверить мой видеоурок на YouTube.
У них очень хорошие свойства:
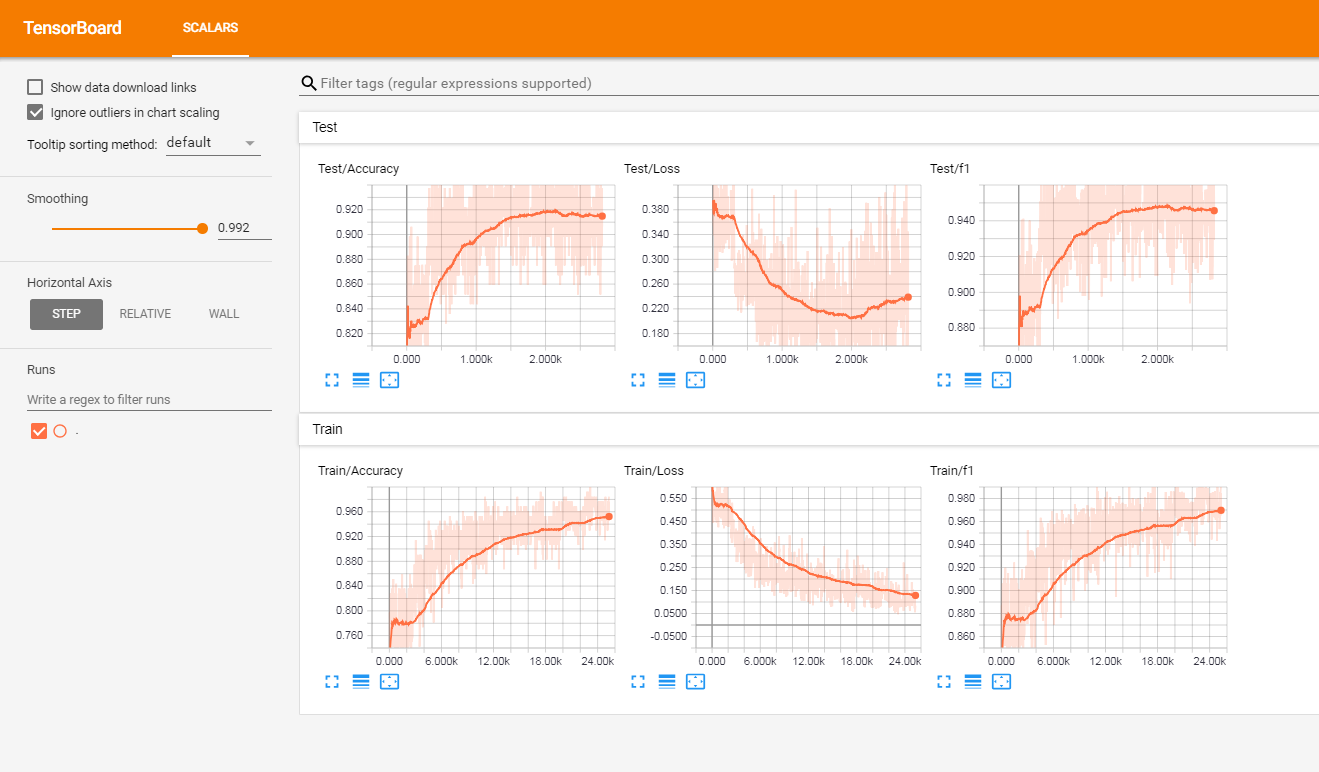
Я протестировал эту модель на наборе французских отзывов с маркировкой клиентов (более 3 миллионов строк). Я сообщил о метрик в Tensorboardx.
Я получил следующие результаты
| F1 Оценка | Точность | |
|---|---|---|
| тренироваться | 0,965 | 0,9366 |
| тест | 0,945 | 0,915 |
В корне проекта у вас будет:
Код в настоящее время работает только на бинарных метках (0/1)
Запустите Train.py со следующими аргументами:
data_path : путь данных. Данные должны быть в формате CSV, по крайней мере, столбцом для текста и столбцом для меткиvalidation_split : отношение данных проверки. по умолчанию до 0,2label_column : имя столбца меткиtext_column : имя столбца текстовmax_rows : максимальное количество строк для загрузки из набора данных. (Я в основном использую это для тестирования, чтобы идти быстрее)chunksize : размер кусков при загрузке данных с помощью пандов. по умолчанию до 500000encoding : по умолчанию UTF-8steps : Текст предварительной обработки, чтобы включить в текст, подобный хэштегу или удалению URL -адресаgroup_labels : Будь то группировать этикетки. По умолчанию никто.use_sampler : использовать ли взвешенный пробоотборник для преодоления дисбаланса классаalphabet : по умолчанию в ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 ,;.!?: '"/ | _@#$%^&*~`+-= <> () [] {} (обычно вы не должны модифицировать его)number_of_characters : по умолчанию 70extra_characters : дополнительные символы, которые вы добавили бы в алфавит. Напримерmax_length : максимальная длина для исправления для всех документов. по умолчанию до 150, но должно быть адаптировано к вашим даннымepochs : количество эпохbatch_size : размер партии, по умолчанию до 128.optimizer : Адам или SGD, по умолчанию в SGDlearning_rate : по умолчанию до 0,01class_weights : использовать веса классов в потерь потерь энтропии или нетfocal_loss : использовать или нетgamma : гамма -параметр потери фокуса. по умолчанию до 2alpha : альфа -параметр потери фокала. По умолчанию до 0,25schedule : количество эпох, с помощью которых скорость обучения уменьшается вдвое (планирование скорости обучения работает только для SGD), по умолчанию 3. Установите его на 0, чтобы отключить егоpatience : максимальное количество эпох, чтобы ждать без улучшения потери проверки, по умолчанию 3early_stopping : выбрать, остановите ли рано остановить обучение или нет. по умолчанию в 0. Установите на 1, чтобы включить его.checkpoint : выбрать, чтобы сохранить модель на диске или нет. по умолчанию в 1, установите на 0, чтобы отключить контрольную точку моделиworkers : количество работников в DataLoader Pytorch, по умолчанию до 1log_path : Путь файла журнала Tensorboardoutput : путь папки, где сохраняются моделиmodel_name : название префикса сохраненных моделейПример использования:
python train.py --data_path=/data/tweets.csv --max_rows=200000Запустите эту команду в корне проекта:
tensorboard --logdir=./logs/ --port=6006Затем перейдите по адресу: http: // localhost: 6006 (или какой -либо хост, который вы используете)
Запуск прогнозирует.py со следующими аргументами:
model : Путь предварительно обученной моделиtext : входной текстsteps : Список шагов предварительной обработки, по умолчанию, чтобы снизитьalphabet : по умолчанию в Abcdefghijklmnopqrstuvwxyz0123456789-,;.!?: '"/| _@#$%^&*~`+-= <> () [] {} n'number_of_characters : по умолчанию 70extra_characters : дополнительные символы, которые вы добавили бы в алфавит. Напримерmax_length : максимальная длина для исправления для всех документов. по умолчанию до 150, но должно быть адаптировано к вашим даннымПример использования:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
Модель анализа настроений на французских отзывах клиентов (3M документы): Ссылка загрузки
При использовании:
Вот неэкгартный список потенциальных будущих функций для добавления:
Этот проект лицензирован по лицензии MIT


