character based cnn
English Model
該回購包含用於文本分類的角色級卷積神經網絡的pytorch實現。
模型架構來自本文:https://arxiv.org/pdf/1509.01626.pdf
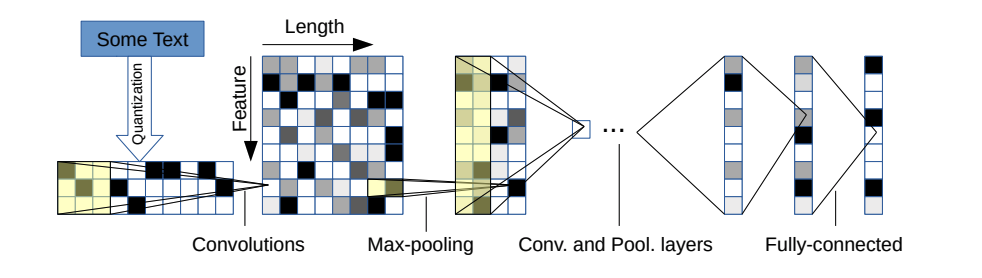
有兩個變體:一個大和小。您可以通過更改配置文件在兩者之間切換。
該體系結構有6個卷積層:
| 層 | 大型功能 | 小功能 | 核心 | 水池 |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N/A。 |
| 4 | 1024 | 256 | 3 | N/A。 |
| 5 | 1024 | 256 | 3 | N/A。 |
| 6 | 1024 | 256 | 3 | 3 |
和2個完全連接的層:
| 層 | 輸出單位大 | 輸出單元很小 |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | 取決於問題 | 取決於問題 |
如果您對角色CNN的工作方式以及該項目的演示感興趣,則可以查看我的YouTube視頻教程。
他們的特性非常好:
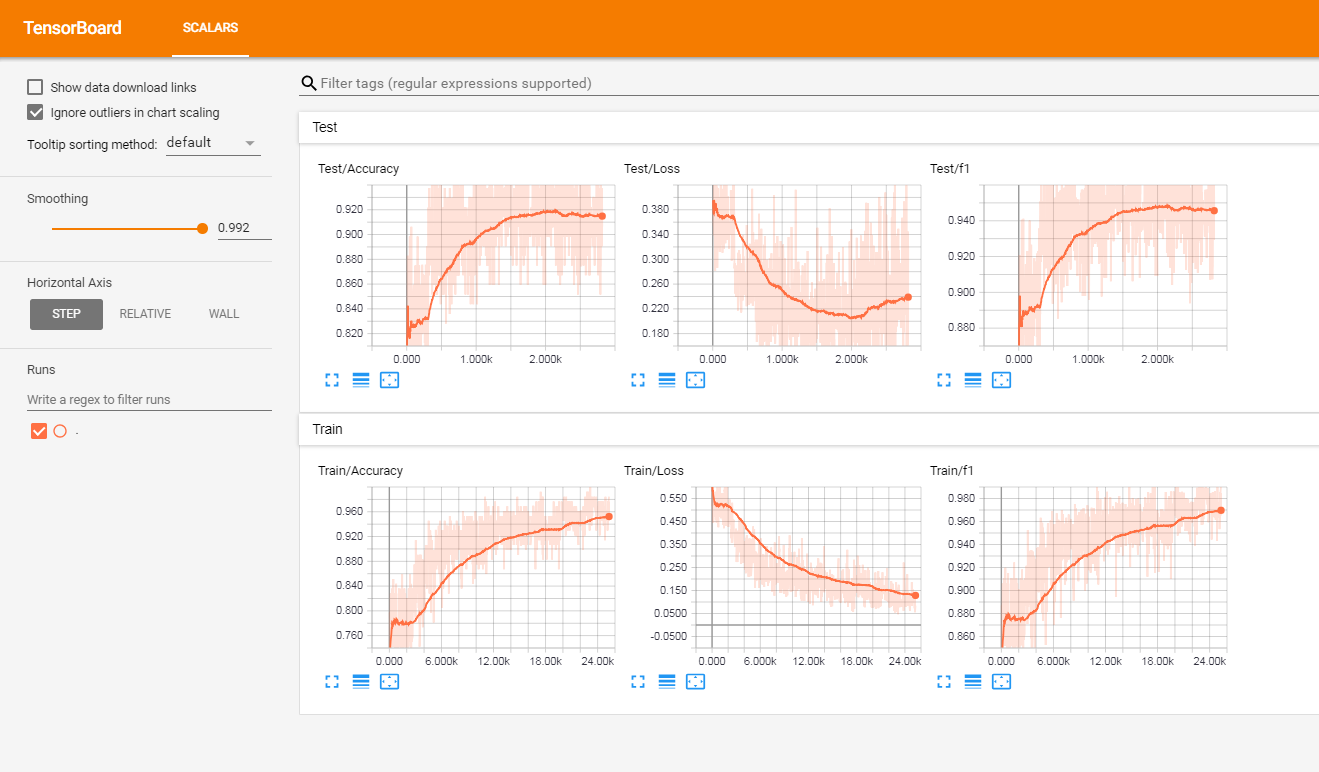
我已經在一組法國標記的客戶評論(超過300萬行)上測試了該模型。我報告了TensorboardX中的指標。
我得到以下結果
| F1得分 | 準確性 | |
|---|---|---|
| 火車 | 0.965 | 0.9366 |
| 測試 | 0.945 | 0.915 |
從項目的根源上,您將擁有:
該代碼當前僅在二進制標籤(0/1)上工作
啟動train.py帶有以下論點:
data_path :數據路徑。數據應為CSV格式,至少具有文本列,並且標籤的列validation_split :驗證數據的比率。默認為0.2label_column :標籤的列名稱text_column :文本的列名稱max_rows :從數據集加載的最大行數。 (我主要將其用於測試以進行更快)chunksize :使用熊貓加載數據時的塊大小。默認為500000encoding :默認為UTF-8steps :文本預處理步驟,以將其包含在標籤或URL刪除等文本中group_labels :是否要組標籤。默認為無。use_sampler :是否使用加權採樣器克服班級失衡alphabet :默認為Abcdefghijklmnopqrstuvwxyz0123456789;。 ! ? :'number_of_characters :默認70extra_characters :您要添加到字母的其他字符。例如大寫字母或重音字符max_length :用於修復所有文檔的最大長度。默認為150,但應適應您的數據epochs :時代的數量batch_size :批次大小,默認為128。optimizer :Adam或SGD,默認為SGDlearning_rate :默認為0.01class_weights :是否在交叉熵損失中使用班級權重focal_loss :是否使用焦點損失gamma :局灶性損失的伽馬參數。默認為2alpha :局灶性損失的α參數。默認為0.25schedule :學習率降低一半的時期數(學習率計劃僅適用於SGD),默認為3。將其設置為0以將其禁用patience :最大數量的時期數量等待而無需改善驗證損失,默認為3early_stopping :選擇是否早日停止培訓。默認為0。設置為1以啟用它。checkpoint :選擇是否將模型保存在磁盤上。默認為1,設置為0至禁用模型檢查點workers :Pytorch數據加載程序中的工人人數,默認為1log_path :張板的路徑日誌文件output :保存模型的文件夾的路徑model_name :保存模型的前綴名稱示例用法:
python train.py --data_path=/data/tweets.csv --max_rows=200000以項目的根源運行此命令:
tensorboard --logdir=./logs/ --port=6006然後轉到:http:// localhost:6006(或您使用的任何主機)
啟動預測。
model :預訓練模型的路徑text :輸入文字steps :預處理步驟列表,默認為較低alphabet :默認為'abcdefghijklmnopqrstuvwxyz0123456789 - ;。 ! ?number_of_characters :默認為70extra_characters :您要添加到字母的其他字符。例如大寫字母或重音字符max_length :用於修復所有文檔的最大長度。默認為150,但應適應您的數據示例用法:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
關於法國客戶評論(3M文檔)的情感分析模型:下載鏈接
使用時:
這是要添加的潛在未來功能的非詳盡清單:
該項目已根據麻省理工學院許可證


