character based cnn
English Model
このレポは、テキスト分類のためのキャラクターレベルの畳み込みニューラルネットワークのPytorch実装が含まれています。
モデルアーキテクチャは、このペーパーからのものです:https://arxiv.org/pdf/1509.01626.pdf
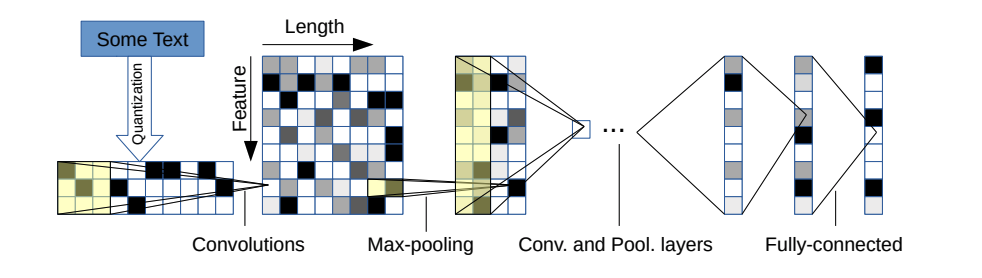
2つのバリエーションがあります。大きくて小さいです。構成ファイルを変更して、2つを切り替えることができます。
このアーキテクチャには6つの畳み込みレイヤーがあります。
| 層 | 大きな機能 | 小さな機能 | カーネル | プール |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | n/a |
| 4 | 1024 | 256 | 3 | n/a |
| 5 | 1024 | 256 | 3 | n/a |
| 6 | 1024 | 256 | 3 | 3 |
2つの完全に接続されたレイヤー:
| 層 | 出力ユニットは大きい | 出力ユニットは小さい |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | 問題に依存します | 問題に依存します |
キャラクターCNNがどのように機能するか、およびこのプロジェクトのデモに興味がある場合は、YouTubeビデオチュートリアルを確認できます。
彼らは非常に素晴らしい特性を持っています:
このモデルは、フランスのラベルの付いた顧客レビューのセット(300万列以上)でテストしました。 Tensorboardxのメトリックを報告しました。
次の結果が得られました
| F1スコア | 正確さ | |
|---|---|---|
| 電車 | 0.965 | 0.9366 |
| テスト | 0.945 | 0.915 |
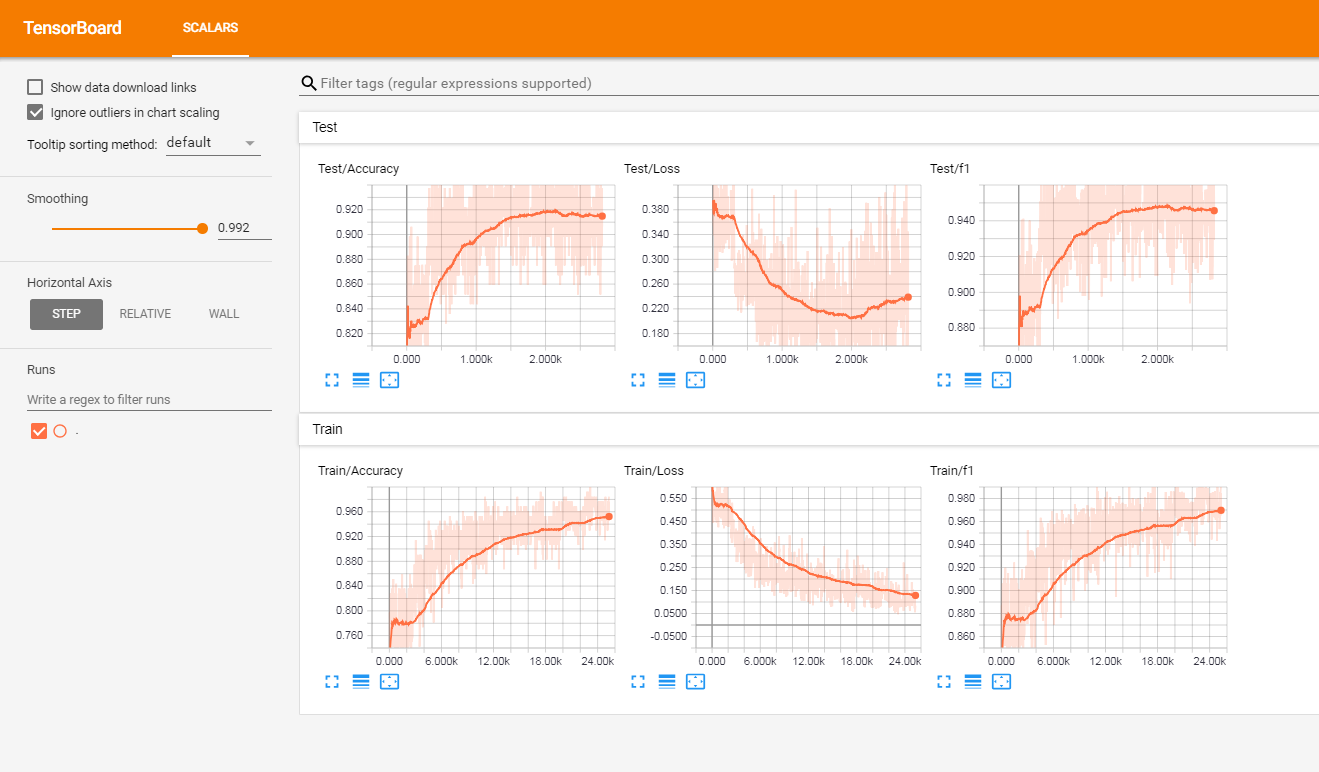
プロジェクトの根本には、次のようになります。
現在、コードはバイナリラベル(0/1)でのみ動作します
次の引数でtrain.pyを起動します。
data_path :データのパス。データはCSV形式で、少なくともテキスト用の列とラベルの列を使用する必要がありますvalidation_split :検証データの比率。デフォルトは0.2になりますlabel_column :ラベルの列名text_column :テキストの列名max_rows :データセットからロードする行の最大数。 (私は主にこれをテストに使用してより速く進む)chunksize :パンダを使用してデータをロードするときのチャンクのサイズ。デフォルトは500000になりますencoding :デフォルトはUTF-8になりますsteps :ハッシュタグやURLの削除などのテキストに含めるテキスト前処理手順group_labels :ラベルをグループ化するかどうか。デフォルトはありません。use_sampler :加重サンプラーを使用してクラスの不均衡を克服するかどうかalphabet :デフォルトでabcdefghijklmnopqrstuvwxyz0123456789、;。number_of_characters :デフォルト70extra_characters :アルファベットに追加する追加の文字。たとえば、大文字またはアクセントされた文字max_length :すべてのドキュメントを修正する最大長。デフォルトは150になりましたが、データに適応する必要がありますepochs :エポックの数batch_size :バッチサイズ、デフォルトは128になります。optimizer :AdamまたはSGD、デフォルトのSGDlearning_rate :デフォルトは0.01になりますclass_weights :クロスエントロピー損失でクラスのウェイトを使用するかどうかfocal_loss :焦点損失を使用するかどうかgamma :焦点損失のガンマパラメーター。デフォルトは2になりますalpha :焦点損失のアルファパラメーター。デフォルトは0.25になりますschedule :学習率が半分減少するエポックの数(学習率のスケジューリングはSGDでのみ機能します)、デフォルト3になります。patience :検証損失を改善せずに待つために最大数のエポック数、デフォルト3にearly_stopping :トレーニングを早期に停止するかどうかを選択します。デフォルト0になります。1に設定して有効にします。checkpoint :ディスクにモデルを保存するかどうかを選択します。デフォルト1に、モデルチェックポイントを無効にするために0に設定workers :Pytorch Dataloaderの労働者数、デフォルト1log_path :テンソルボードログファイルのパスoutput :モデルが保存されているフォルダーのパスmodel_name :保存されたモデルのプレフィックス名使用例:
python train.py --data_path=/data/tweets.csv --max_rows=200000このコマンドをプロジェクトのルートで実行します。
tensorboard --logdir=./logs/ --port=6006次に、http:// localhost:6006(または使用しているホスト)に移動します
次の引数でpredict.pyを起動します。
model :事前に訓練されたモデルのパスtext :入力テキストsteps :デフォルトで低い手順のリスト:低下しますalphabet :デフォルトで「abcdefghijklmnopqrstuvwxyz0123456789 - 、;。number_of_characters :デフォルトは70になりますextra_characters :アルファベットに追加する追加の文字。たとえば、大文字またはアクセントされた文字max_length :すべてのドキュメントを修正する最大長。デフォルトは150になりましたが、データに適応する必要があります使用例:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
フランスの顧客レビューに関するセンチメント分析モデル(3Mドキュメント):リンクをダウンロード
使用する場合:
追加する潜在的な将来の機能の非網羅的なリストは次のとおりです。
このプロジェクトは、MITライセンスの下でライセンスされています


