character based cnn
English Model
Este repo contém uma implementação de Pytorch de uma rede neural convolucional no nível do caractere para classificação de texto.
A arquitetura do modelo vem deste artigo: https://arxiv.org/pdf/1509.01626.pdf
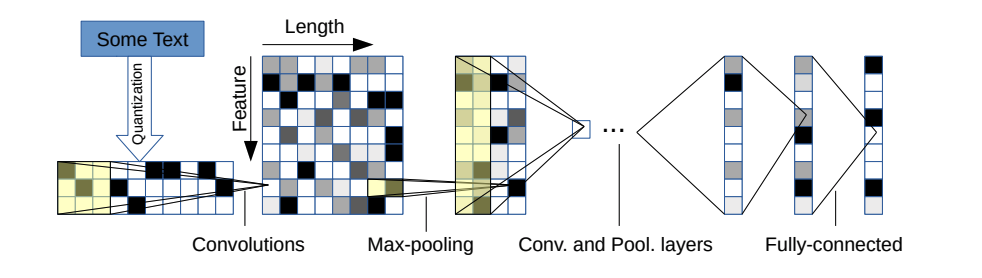
Existem duas variantes: uma grande e uma pequena. Você pode alternar entre os dois alterando o arquivo de configuração.
Esta arquitetura tem 6 camadas convolucionais:
| Camada | Grande característica | Pequena característica | Kernel | Piscina |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N / D |
| 4 | 1024 | 256 | 3 | N / D |
| 5 | 1024 | 256 | 3 | N / D |
| 6 | 1024 | 256 | 3 | 3 |
e 2 camadas totalmente conectadas:
| Camada | Unidades de saída grandes | Unidades de saída pequenas |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | Depende do problema | Depende do problema |
Se você estiver interessado em como o personagem CNN funciona, bem como na demonstração deste projeto, pode verificar meu tutorial em vídeo do YouTube.
Eles têm propriedades muito boas:
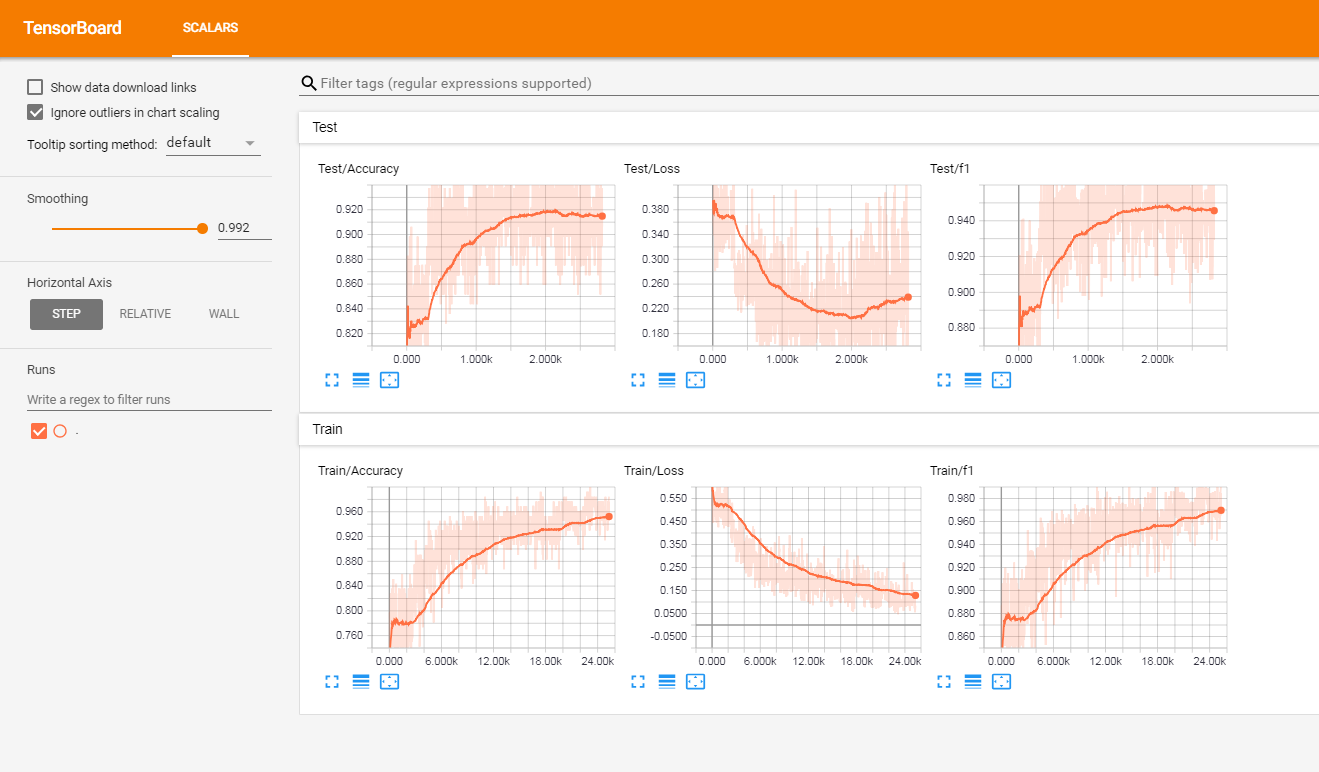
Eu testei esse modelo em um conjunto de análises de clientes rotuladas em francês (de mais de 3 milhões de linhas). Relatei as métricas no TensorboardX.
Eu recebi os seguintes resultados
| Pontuação F1 | Precisão | |
|---|---|---|
| trem | 0,965 | 0,9366 |
| teste | 0,945 | 0,915 |
Na raiz do projeto, você terá:
O código atualmente funciona apenas em rótulos binários (0/1)
Inicie o trem.py com os seguintes argumentos:
data_path : caminho dos dados. Os dados devem estar em formato CSV com pelo menos uma coluna para texto e uma coluna para o rótulovalidation_split : a proporção de dados de validação. padrão para 0,2label_column : Nome da coluna dos rótulostext_column : Nome da coluna dos textosmax_rows : o número máximo de linhas para carregar do conjunto de dados. (Eu uso principalmente isso para testar para ir mais rápido)chunksize : tamanho dos pedaços ao carregar os dados usando pandas. Padrão para 500000encoding : Padrão para UTF-8steps : Etapas de pré -processamento de texto para incluir no texto como hashtag ou remoção de URLgroup_labels : se deve ou não agrupar os rótulos. Padrão para nenhum.use_sampler : se deve ou não usar um amostrador ponderado para superar o desequilíbrio da classealphabet : padrão para abcdefghijklmnopqrstStuvwxyz0123456789;.!number_of_characters : padrão 70extra_characters : caracteres adicionais que você adicionaria ao alfabeto. Por exemplo, letras maiúsculas ou caracteres acentuadosmax_length : o comprimento máximo para corrigir para todos os documentos. padrão para 150, mas deve ser adaptado aos seus dadosepochs : número de épocasbatch_size : Tamanho do lote, padrão para 128.optimizer : Adam ou SGD, padrão para SGDlearning_rate : Padrão para 0,01class_weights : se deve ou não usar pesos de classe na perda de entropia cruzadafocal_loss : se deve ou não usar a perda focalgamma : parâmetro gama da perda focal. padrão para 2alpha : parâmetro alfa da perda focal. padrão para 0,25schedule : Número de épocas pelas quais a taxa de aprendizagem diminui pela metade (o agendamento da taxa de aprendizado funciona apenas para o SGD), padrão para 3. Defina -o para 0 para desativá -lopatience : Número máximo de épocas para esperar sem melhorar a perda de validação, padrão para 3early_stopping : escolher se para interromper ou não o treinamento. padrão para 0. Defina como 1 para ativá -lo.checkpoint : optar por salvar o modelo no disco ou não. Padrão para 1, defina como 0 para desativar o ponto de verificação do modeloworkers : Número de trabalhadores em Pytorch Dataloader, padrão para 1log_path : caminho do arquivo de log de tensorboardoutput : caminho da pasta onde os modelos são salvosmodel_name : Nome do prefixo de modelos salvosExemplo de uso:
python train.py --data_path=/data/tweets.csv --max_rows=200000Execute este comando na raiz do projeto:
tensorboard --logdir=./logs/ --port=6006Em seguida, vá para: http: // localhost: 6006 (ou qualquer host que você esteja usando)
Lançar prevc.py com os seguintes argumentos:
model : Caminho do modelo pré-treinadotext : texto de entradasteps : Lista de etapas de pré -processamento, padrão para diminuiralphabet : padrão 'abcdefghijklmnopqrstuvwxyz0123456789-,;.!?:' "/| _@#$%^&*~` `+-= <> () [] {} n 'number_of_characters : padrão para 70extra_characters : caracteres adicionais que você adicionaria ao alfabeto. Por exemplo, letras maiúsculas ou caracteres acentuadosmax_length : o comprimento máximo para corrigir para todos os documentos. padrão para 150, mas deve ser adaptado aos seus dadosExemplo de uso:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
Modelo de análise de sentimentos em análises francesas de clientes (documentos 3M): Link para download
Ao usá -lo:
Aqui está uma lista não exaustiva de possíveis recursos futuros a serem adicionados:
Este projeto está licenciado sob a licença do MIT


