character based cnn
English Model
Ce dépôt contient une implémentation pytorch d'un réseau neuronal convolutionnel au niveau des caractères pour la classification du texte.
L'architecture modèle provient de cet article: https://arxiv.org/pdf/1509.01626.pdf
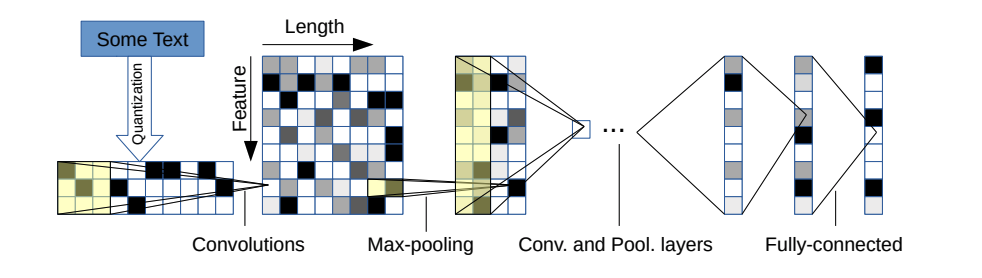
Il y a deux variantes: un grand et un petit. Vous pouvez basculer entre les deux en modifiant le fichier de configuration.
Cette architecture a 6 couches convolutionnelles:
| Couche | Grande fonctionnalité | Caractéristique | Noyau | Piscine |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | N / A |
| 4 | 1024 | 256 | 3 | N / A |
| 5 | 1024 | 256 | 3 | N / A |
| 6 | 1024 | 256 | 3 | 3 |
et 2 couches entièrement connectées:
| Couche | Unités de sortie grandes | Unités de sortie petites |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | Dépend du problème | Dépend du problème |
Si vous êtes intéressé par le fonctionnement du personnage CNN ainsi que par la démo de ce projet, vous pouvez consulter mon tutoriel vidéo YouTube.
Ils ont de très belles propriétés:
J'ai testé ce modèle sur un ensemble de critiques de clients étiquetées françaises (de plus de 3 millions de lignes). J'ai signalé les mesures dans Tensorboardx.
J'ai obtenu les résultats suivants
| Score F1 | Précision | |
|---|---|---|
| former | 0,965 | 0,9366 |
| test | 0,945 | 0,915 |
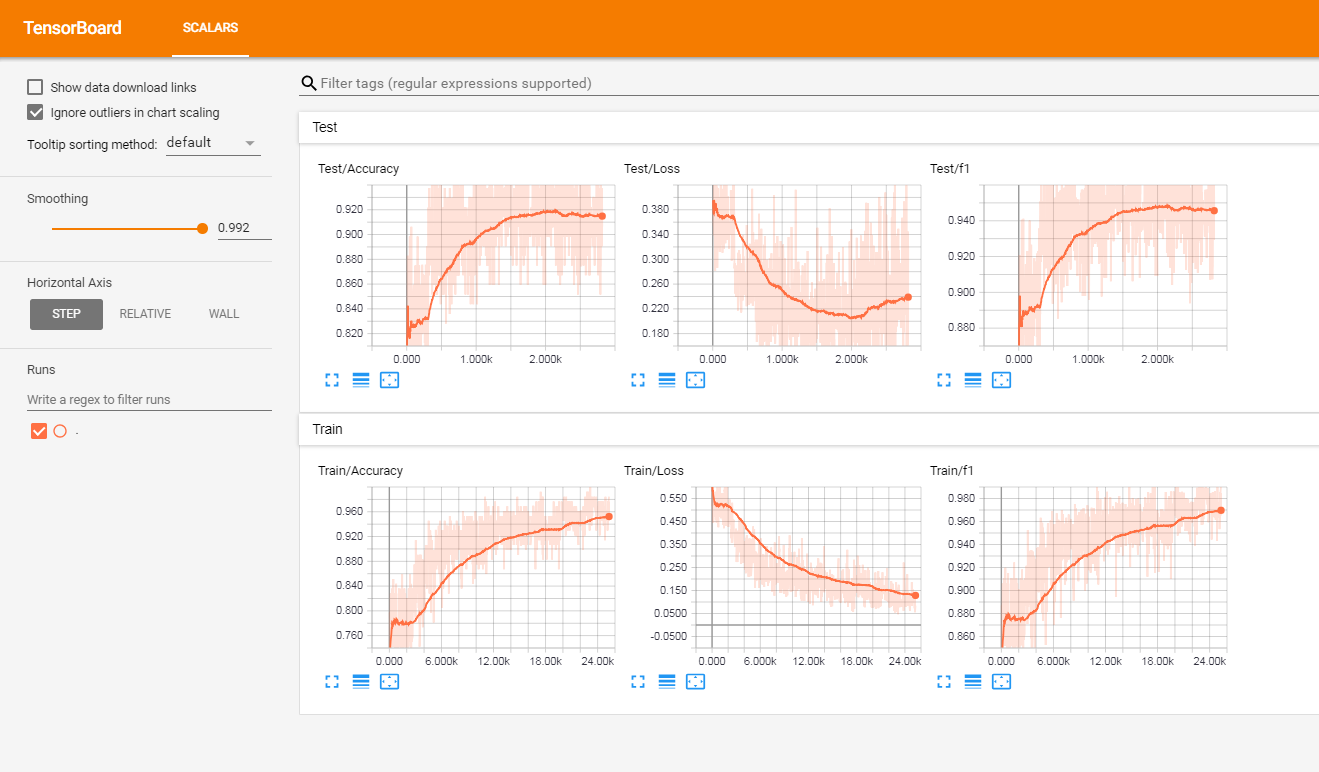
À l'origine du projet, vous aurez:
Le code ne fonctionne actuellement que sur les étiquettes binaires (0/1)
Lancez Train.py avec les arguments suivants:
data_path : chemin des données. Les données doivent être au format CSV avec au moins une colonne de texte et une colonne pour l'étiquettevalidation_split : le rapport des données de validation. par défaut à 0,2label_column : Nom de la colonne des étiquettestext_column : Nom de la colonne des textesmax_rows : le nombre maximum de lignes à charger à partir de l'ensemble de données. (J'utilise principalement ceci pour les tests pour aller plus vite)chunksize : Taille des morceaux lors du chargement des données à l'aide de pandas. par défaut à 500000encoding : par défaut vers UTF-8steps : étapes de prétraitement du texte à inclure sur le texte comme le hashtag ou la suppression d'URLgroup_labels : Que ce soit pour regrouper ou non des étiquettes. Par défaut à aucun.use_sampler : Que ce soit ou non un échantillonneur pondéré pour surmonter le déséquilibre des classesalphabet : par défaut à ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789,;.!?: '"/ | _ @ # $% ^ & * ~` + - = <> () [] {} (normalement vous ne devez pas le modifier)number_of_characters : par défaut 70extra_characters : caractères supplémentaires que vous ajouteriez à l'alphabet. Par exemple, lettres majuscules ou caractères accentuésmax_length : la longueur maximale à corriger pour tous les documents. par défaut à 150 mais devrait être adapté à vos donnéesepochs : nombre d'épochesbatch_size : Taille du lot, par défaut à 128.optimizer : Adam ou SGD, par défaut à SGDlearning_rate : par défaut à 0,01class_weights : Que ce soit pour utiliser ou non des poids de classe dans la perte d'entropie croiséefocal_loss : s'il faut utiliser ou non la perte focalegamma : paramètre gamma de la perte focale. par défaut à 2alpha : alpha de la perte focale. par défaut à 0,25schedule : Nombre d'époches par lesquelles le taux d'apprentissage diminue de moitié (la planification du taux d'apprentissage fonctionne uniquement pour SGD), par défaut à 3.patience : nombre maximum d'époches à attendre sans amélioration de la perte de validation, par défaut à 3early_stopping : pour choisir d'arrêter ou non la formation ou non. par défaut à 0. réglé sur 1 pour l'activer.checkpoint : pour choisir de sauvegarder le modèle sur le disque ou non. par défaut à 1, réglé sur 0 pour désactiver le point de contrôle du modèleworkers : Nombre de travailleurs dans Pytorch DatalOader, par défaut à 1log_path : Chemin du fichier journal de Tensorboardoutput : Chemin du dossier où les modèles sont enregistrésmodel_name : Nom du préfixe des modèles enregistrésExemple d'utilisation:
python train.py --data_path=/data/tweets.csv --max_rows=200000Exécutez cette commande à la racine du projet:
tensorboard --logdir=./logs/ --port=6006Ensuite, allez à: http: // localhost: 6006 (ou n'importe quel hôte que vous utilisez)
Lancez Predict.py avec les arguments suivants:
model : Chemin du modèle pré-formétext : Texte de saisiesteps : Liste des étapes de prétraitement, par défautalphabet : par défaut à 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 -,;.!?:' " / | _ @ # $% ^ & * ~` + - = <> () [] {} n 'number_of_characters : par défaut à 70extra_characters : caractères supplémentaires que vous ajouteriez à l'alphabet. Par exemple, lettres majuscules ou caractères accentuésmax_length : la longueur maximale à corriger pour tous les documents. par défaut à 150 mais devrait être adapté à vos donnéesExemple d'utilisation:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
Modèle d'analyse des sentiments sur les avis sur les clients français (documents 3M): Lien de téléchargement
Lorsque vous l'utilisez:
Voici une liste non exhaustive des fonctionnalités futures potentielles à ajouter:
Ce projet est concédé sous licence MIT


