character based cnn
English Model
يحتوي هذا الريبو على تطبيق Pytorch لشبكة عصبية تلافيفية على مستوى الشخصية لتصنيف النص.
تأتي بنية النموذج من هذه الورقة: https://arxiv.org/pdf/1509.01626.pdf
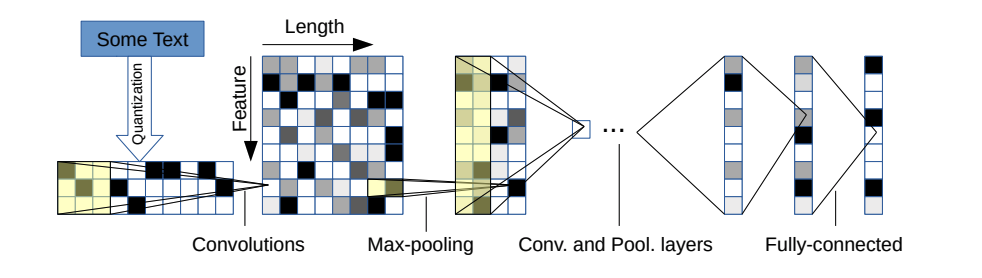
هناك نوعان من المتغيرات: كبيرة وصغيرة. يمكنك التبديل بين الاثنين عن طريق تغيير ملف التكوين.
هذه الهندسة المعمارية لها 6 طبقات تلافيفية:
| طبقة | ميزة كبيرة | ميزة صغيرة | نواة | حمام سباحة |
|---|---|---|---|---|
| 1 | 1024 | 256 | 7 | 3 |
| 2 | 1024 | 256 | 7 | 3 |
| 3 | 1024 | 256 | 3 | ن/أ |
| 4 | 1024 | 256 | 3 | ن/أ |
| 5 | 1024 | 256 | 3 | ن/أ |
| 6 | 1024 | 256 | 3 | 3 |
و 2 طبقات متصلة بالكامل:
| طبقة | وحدات الإخراج كبيرة | وحدات الإخراج صغيرة |
|---|---|---|
| 7 | 2048 | 1024 |
| 8 | 2048 | 1024 |
| 9 | يعتمد على المشكلة | يعتمد على المشكلة |
إذا كنت مهتمًا بكيفية عمل شخصية CNN وكذلك في عرض هذا المشروع ، فيمكنك التحقق من البرنامج التعليمي لفيديو YouTube الخاص بي.
لديهم خصائص جميلة جدا:
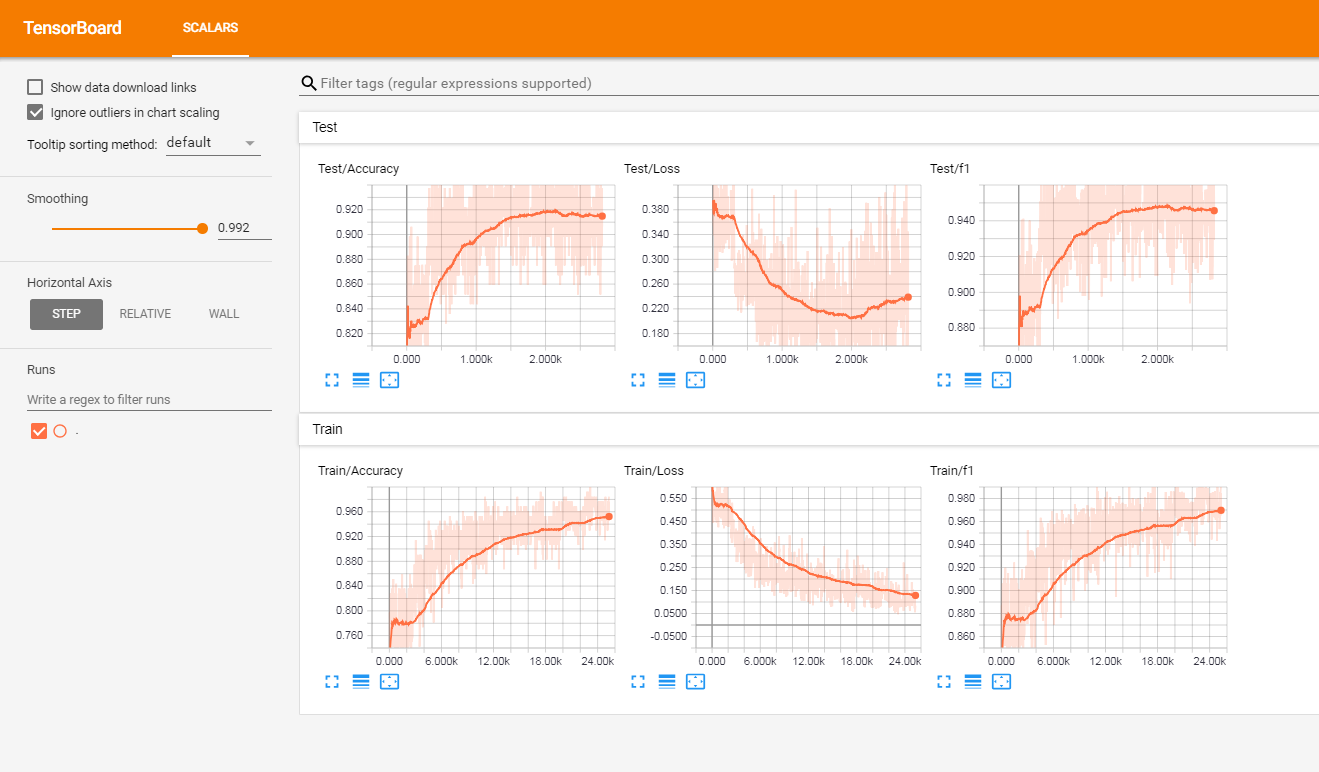
لقد اختبرت هذا النموذج على مجموعة من مراجعات العملاء الفرنسية المسمى (بأكثر من 3 ملايين الصفوف). أبلغت المقاييس في Tensorboardx.
حصلت على النتائج التالية
| درجة F1 | دقة | |
|---|---|---|
| يدرب | 0.965 | 0.9366 |
| امتحان | 0.945 | 0.915 |
في جذر المشروع ، سيكون لديك:
يعمل الرمز حاليًا فقط على العلامات الثنائية (0/1)
إطلاق Train.py مع الحجج التالية:
data_path : مسار البيانات. يجب أن تكون البيانات بتنسيق CSV مع عمود على الأقل للنص وعمود للتسميةvalidation_split : نسبة بيانات التحقق من الصحة. الافتراضي إلى 0.2label_column : اسم عمود الملصقاتtext_column : اسم العمود للنصوصmax_rows : الحد الأقصى لعدد الصفوف التي يجب تحميلها من مجموعة البيانات. (أنا أستخدم هذا بشكل أساسي للاختبار للذهاب بشكل أسرع)chunksize : حجم القطع عند تحميل البيانات باستخدام pandas. الافتراضي إلى 500000encoding : افتراضي لـ UTF-8steps : نص معالجة مسبقًا لتضمينه على النص مثل علامة التجزئة أو إزالة عنوان URLgroup_labels : سواء لم يكن لعلامات المجموعة أم لا. الافتراضي إلى لا شيء.use_sampler : ما إذا كان يجب استخدام عينات مرجحة للتغلب على اختلال التوازن في الصف أم لاalphabet : افتراضي لـ ABCDefghijklMnopQRstuvWxyz0123456789 ، ؛number_of_characters : الافتراضي 70extra_characters : أحرف إضافية تقوم بإضافتها إلى الأبجدية. على سبيل المثال الأحرف الكبيرة أو الأحرف المعلنةmax_length : الحد الأقصى للطول لإصلاح جميع المستندات. الافتراضي إلى 150 ولكن يجب تكييفها مع بياناتكepochs : عدد الحقبةbatch_size : حجم الدُفعة ، الافتراضي إلى 128.optimizer : آدم أو SGD ، افتراضي لـ SGDlearning_rate : افتراضي إلى 0.01class_weights : سواء كان استخدام أوزان فئة في فقدان الانتروبيا أو لاfocal_loss : ما إذا كان استخدام الخسارة البؤرية أم لاgamma : معلمة جاما من فقدان البؤرة. الافتراضي إلى 2alpha : معلمة ألفا من فقدان البؤرة. الافتراضي إلى 0.25schedule : عدد الأحداث التي ينخفض بها معدل التعلم بمقدار النصف (جدولة معدل التعلم تعمل فقط لـ SGD) ، الافتراضي إلى 3. قم بتعيينه على 0 لتعطيلهpatience : الحد الأقصى لعدد الحصر للانتظار دون تحسين فقدان التحقق من الصحة ، الافتراضي إلى 3early_stopping : لاختيار ما إذا كان يجب إيقاف التدريب في وقت مبكر أم لا. الافتراضي إلى 0. تعيين على 1 لتمكينه.checkpoint : لاختيار حفظ النموذج على القرص أم لا. افتراضيًا إلى 1 ، قم بتعيينه على 0 لتعطيل نقطة تفتيش النموذجworkers : عدد العمال في Pytorch Dataloader ، افتراضي إلى 1log_path : مسار ملف سجل Tensorboardoutput : مسار المجلد حيث يتم حفظ النماذجmodel_name : اسم بادئة النماذج المحفوظةمثال الاستخدام:
python train.py --data_path=/data/tweets.csv --max_rows=200000قم بتشغيل هذا الأمر بجذر المشروع:
tensorboard --logdir=./logs/ --port=6006ثم انتقل إلى: http: // localhost: 6006 (أو أي مضيف تستخدمه)
إطلاق Predict.py مع الحجج التالية:
model : مسار النموذج الذي تم تدريبه مسبقًاtext : نص الإدخالsteps : قائمة خطوات المعالجة المسبقة ، الافتراضي إلى الانخفاضalphabet : الافتراضي لـ 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789-، ؛number_of_characters : افتراضي إلى 70extra_characters : أحرف إضافية تقوم بإضافتها إلى الأبجدية. على سبيل المثال الأحرف الكبيرة أو الأحرف المعلنةmax_length : الحد الأقصى للطول لإصلاح جميع المستندات. الافتراضي إلى 150 ولكن يجب تكييفها مع بياناتكمثال الاستخدام:
python predict.py ./models/pretrained_model.pth --text= " I love pizza ! " --max_length=150
نموذج تحليل المشاعر على مراجعات العملاء الفرنسية (وثائق 3M): رابط تنزيل
عند استخدامه:
فيما يلي قائمة غير شاملة بالميزات المستقبلية المحتملة لإضافة:
هذا المشروع مرخص بموجب ترخيص معهد ماساتشوستس للتكنولوجيا


