miners
1.0.0
 :多語言語言模型作為語義檢索器
:多語言語言模型作為語義檢索器⚡介紹礦工基準,旨在評估多語言LMS在語義檢索任務中的能力,包括通過檢索授權的上下文而無需進行微調,包括Bitext挖掘和分類。已經開發了一個全面的框架,以評估語言模型在檢索200多種不同語言的樣本中的有效性,包括具有挑戰性的跨語言(XS)和代碼轉換(CS)設置中的低資源語言。結果表明,通過僅檢索語義上相似的嵌入而無需進行任何微調,可以通過最先進的方法實現競爭性能。
該論文已在EMNLP 2024調查結果中接受。
這是論文[arxiv]的源代碼:
此代碼是使用Pytorch編寫的。如果您在研究中使用此工具包中的任何代碼或數據集,請引用相關論文。
@article {winata2024miners,
title = {礦工:多語言語言模型作為語義回收者},
作者= {Winata,Genta Indra和Zhang,Ruochen和Adelani,David Ifeoluwa},
日記= {arXiv預印arxiv:2406.07424},
年= {2024}
}
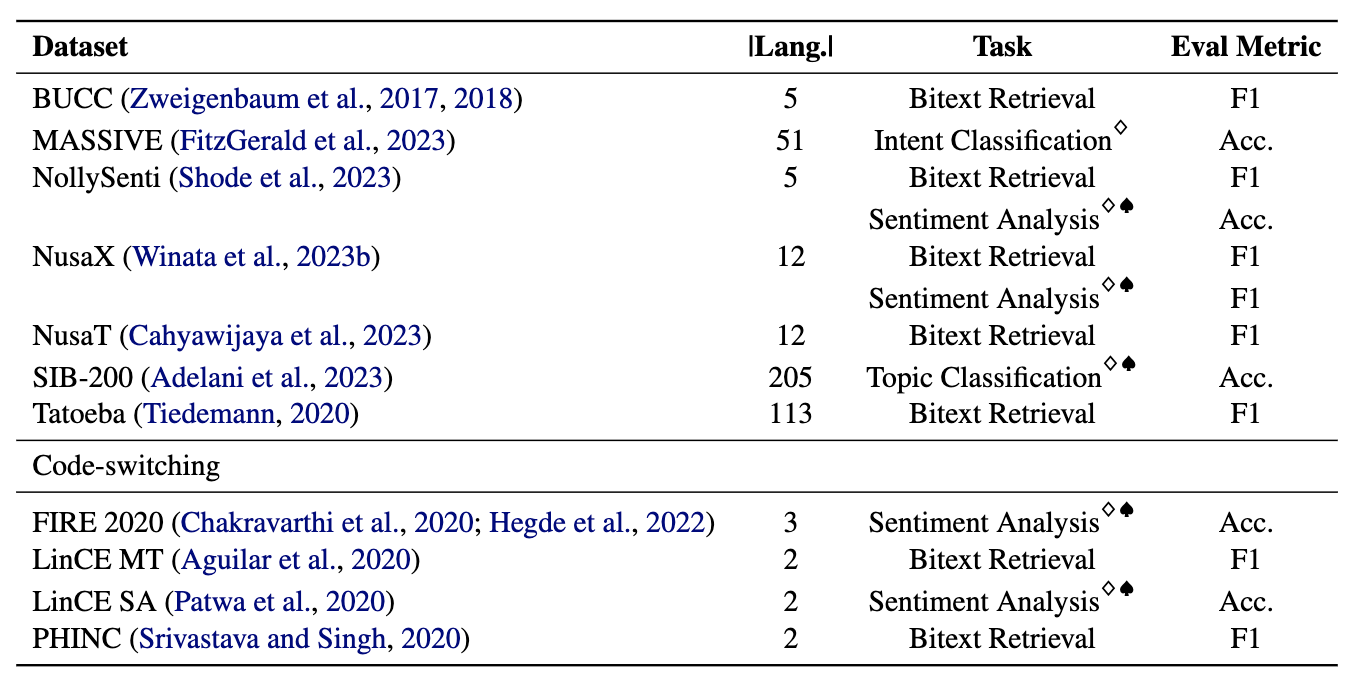
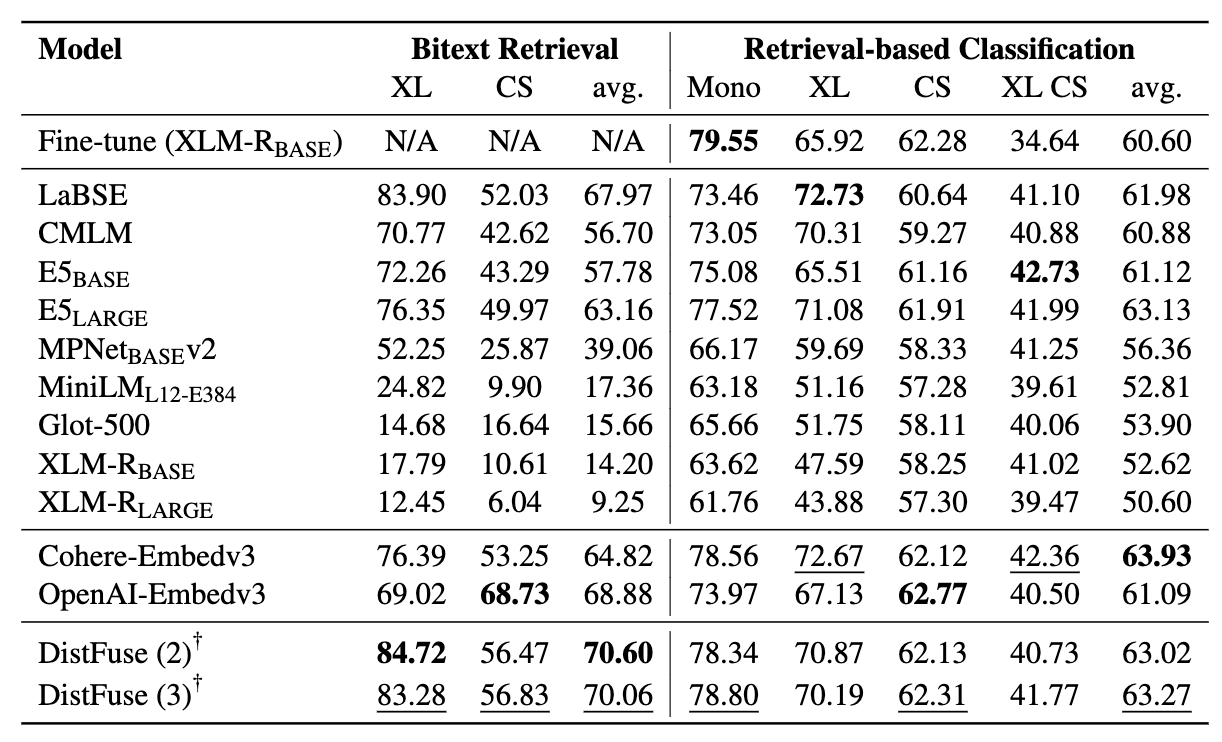
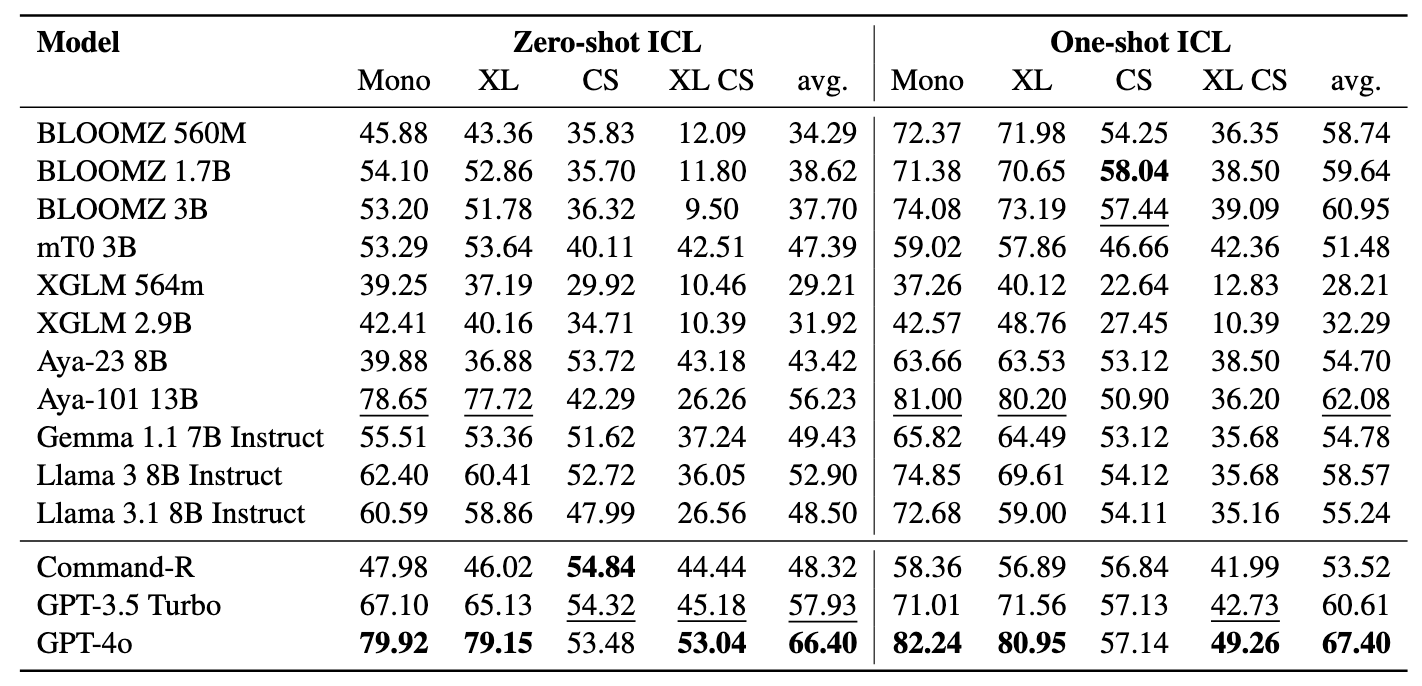
礦工包含11個數據集: 7個多語言和4個代碼轉換數據集,涵蓋200多種語言,並涵蓋並行和分類格式。並行數據集適用於BiteXT檢索,因為它們包含對齊的多語言內容,促進Bitext挖掘和機器翻譯任務。此外,分類數據集涵蓋了意圖分類,情感分析和主題分類,我們評估了基於檢索和ICL分類分配。
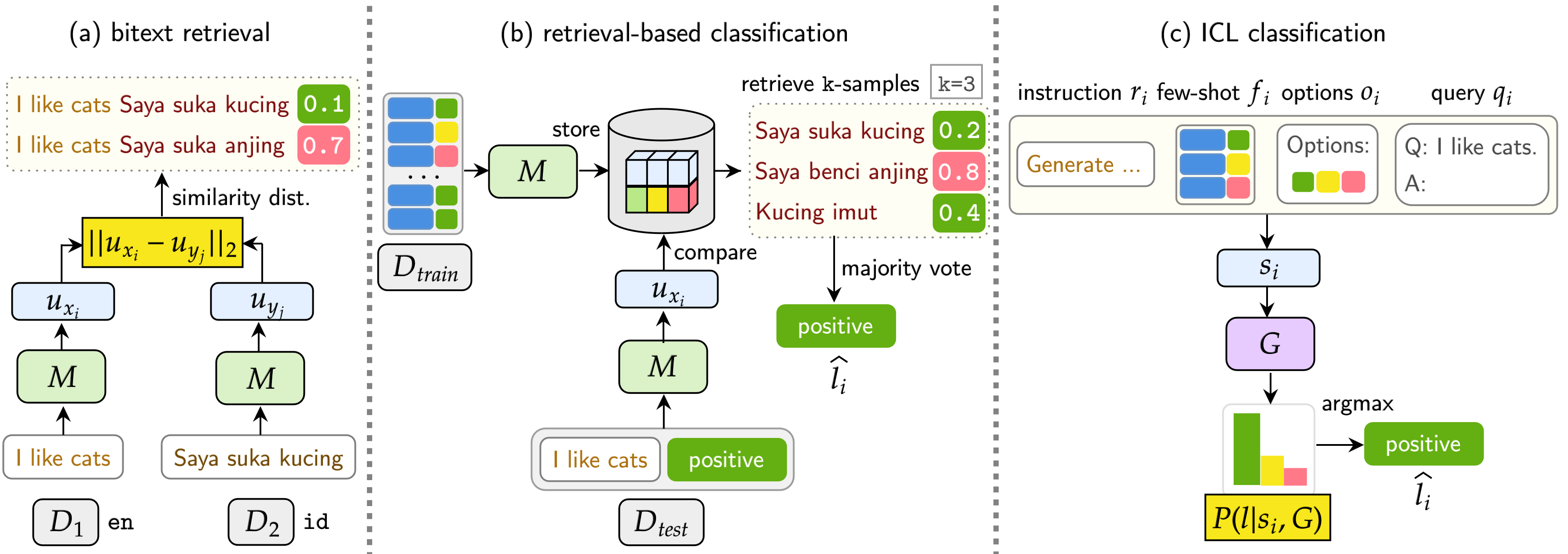
我們的基準測試評估了LMS在三個任務上:BiteXT檢索,基於檢索的分類和ICL分類。這些設置包括單語(單聲道) ,跨語義(XS) ,代碼切換(CS)和跨語言代碼轉換(XS CS) 。
pip install -r requirements.txt
如果您想利用OpenAI,Cohere或Hugging Face的API或模型,請修改OPENAI_TOKEN , COHERE_TOKEN和HF_TOKEN 。請注意,大多數擁抱臉上的模型都不需要HF_TOKEN ,這是專門用於Llama和Gemma型號的。
如果您想使用Llama3.1,則需要升級變壓器版本
pip install transformers==4.44.2
如果您想從我們的實驗中獲取所有結果並迅速示例,請隨時在此處下載它們(〜360MB)。
所有實驗結果將存儲在logs/目錄中。您可以使用以下命令執行每個實驗:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
這些參數與--weights --model_checkpoints
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
添加--src_lang和--cross到命令。
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
這些參數與--weights --model_checkpoints
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
添加--src_lang和--cross到命令。
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
添加--k修改檢索樣品的數量。
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
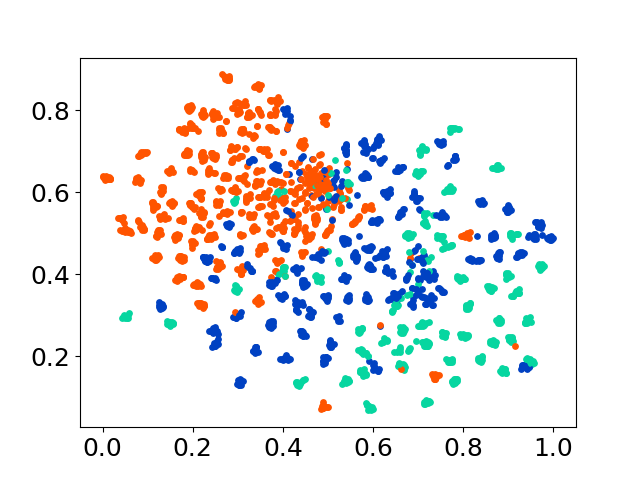
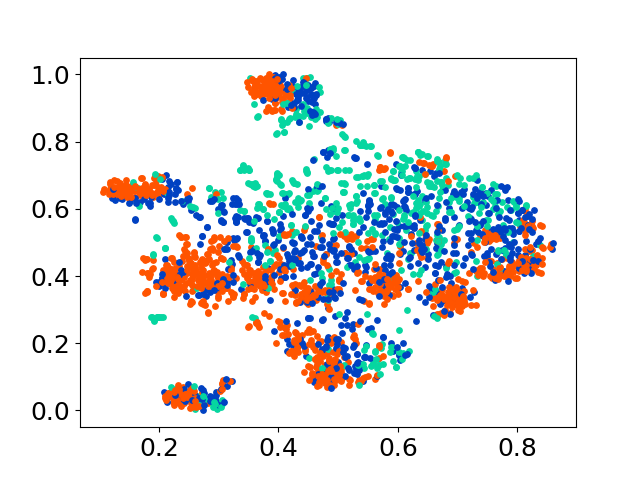
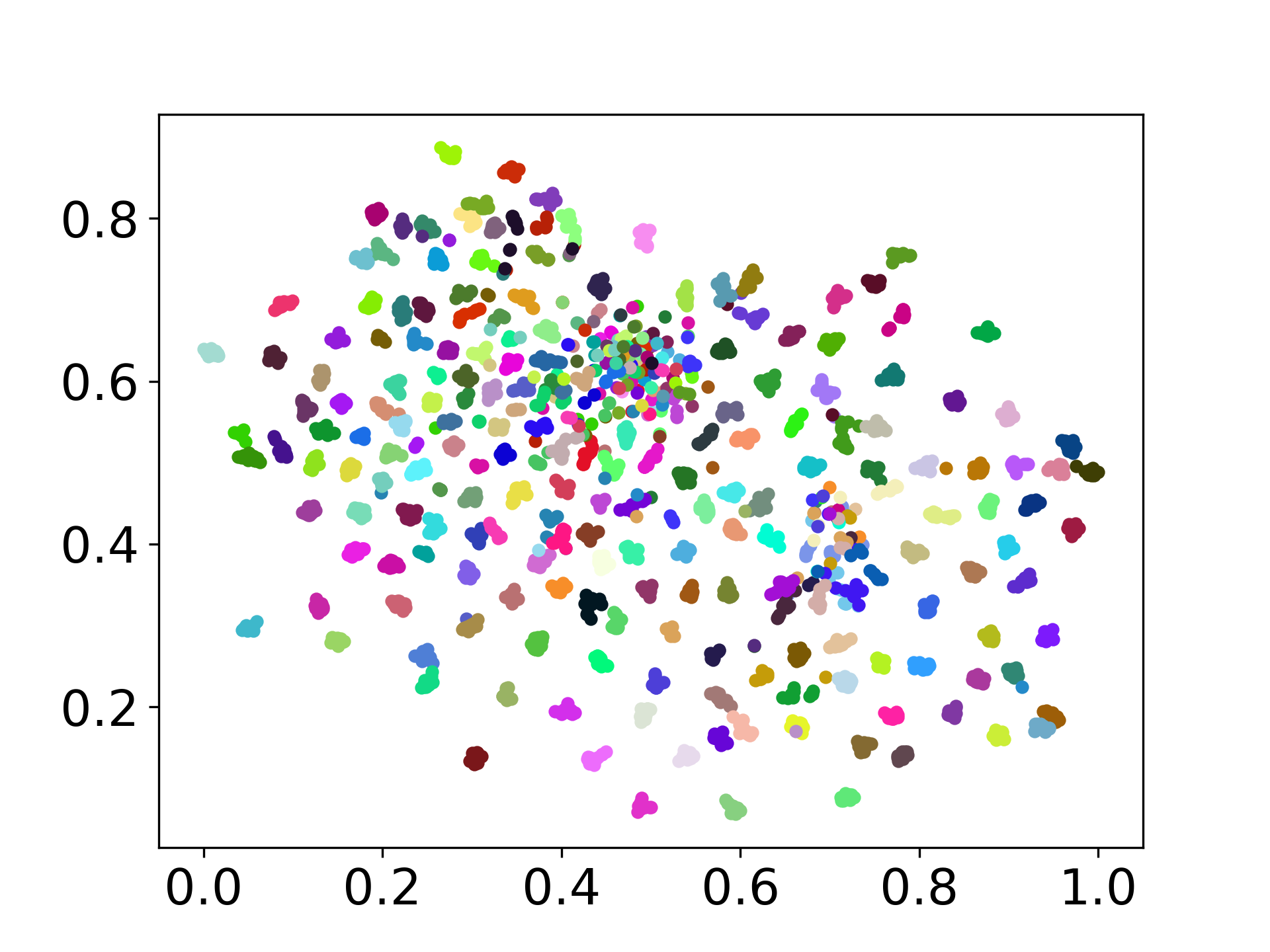
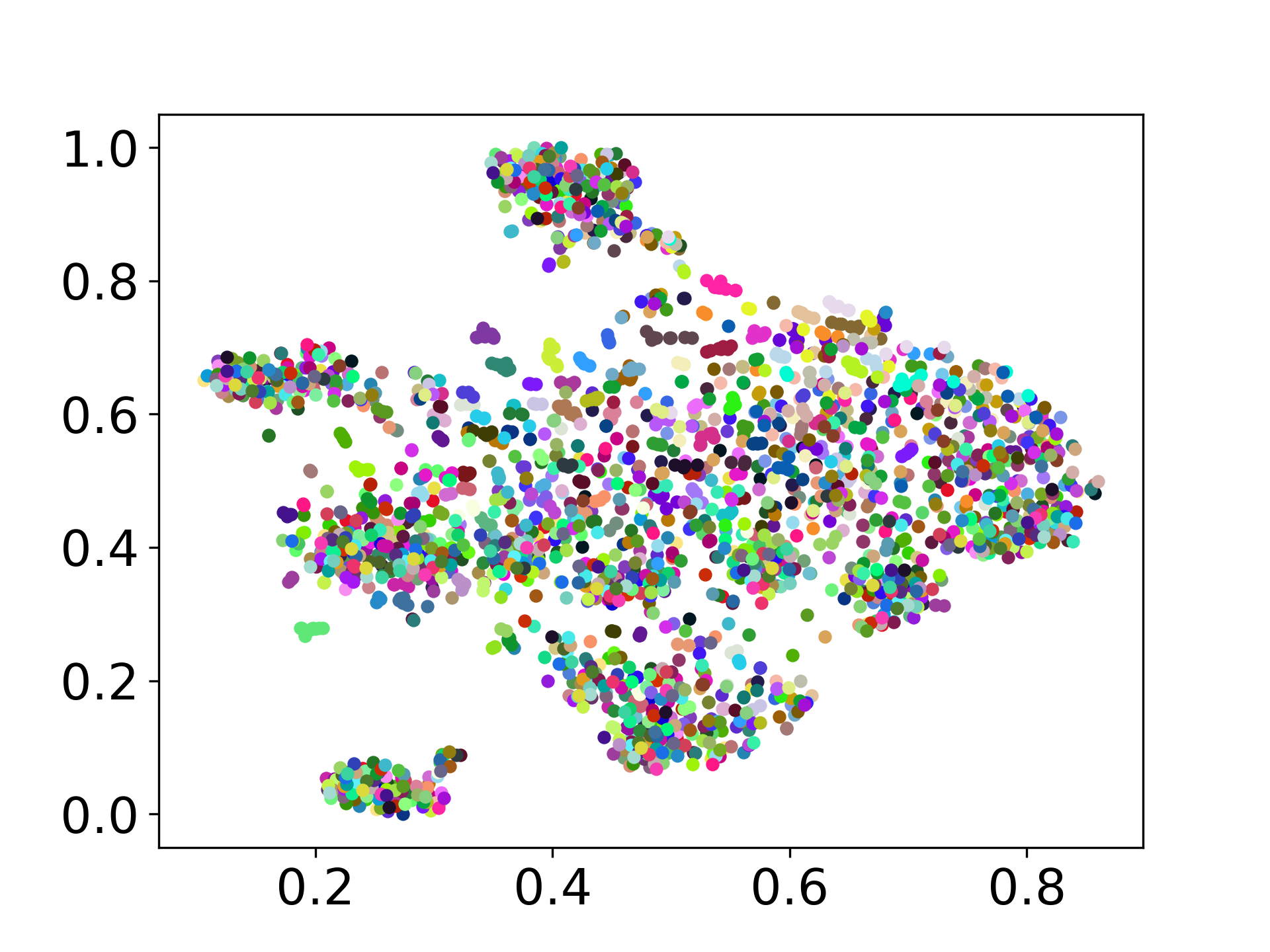
我們的代碼庫支持多個模型的實驗使用,為自定義提供了靈活性,超出了以下所示的列表:
如果您有任何疑問,請隨時創建問題。並且,創建用於修復錯誤或添加改進的PR(即,添加新數據集或模型)。
如果您有興趣創建這項工作的擴展,請隨時與我們聯繫!
支持我們的開源工作
我們正在改進代碼,以使其更具用戶友好和可自定義。我們已經創建了一個用於實現DistFuse的新存儲庫,該存儲庫可在https://github.com/gentaiscool/distfuse/上找到。您可以通過運行pip install distfuse來安裝它。後來,它將集成到此存儲庫中。


