miners
1.0.0
 : Model bahasa multibahasa sebagai pengambil semantik
: Model bahasa multibahasa sebagai pengambil semantik⚡ Memperkenalkan tolok ukur penambang , yang dirancang untuk menilai kecakapan LMS multibahasa dalam tugas pengambilan semantik, termasuk penambangan dan klasifikasi Bitext melalui konteks pengambilan-pengambilan tanpa penyesuaian . Kerangka kerja yang komprehensif telah dikembangkan untuk mengevaluasi efektivitas model bahasa dalam mengambil sampel di lebih dari 200 bahasa yang beragam , termasuk bahasa sumber daya rendah dalam pengaturan cross-lingual (XS) dan pengalihan kode (CS) yang menantang. Hasilnya menunjukkan bahwa mencapai kinerja kompetitif dengan metode canggih dimungkinkan dengan hanya mengambil embeddings yang sama secara semantik, tanpa memerlukan penyesuaian.
Makalah ini telah diterima pada temuan EMNLP 2024.
Ini adalah kode sumber dari makalah [arxiv]:
Kode ini telah ditulis menggunakan Pytorch. Jika Anda menggunakan kode atau set data dari toolkit ini dalam penelitian Anda, silakan kutip kertas terkait.
@Article {winata2024miners,
title = {Miners: model bahasa multibahasa sebagai pengambil semantik},
penulis = {winata, genta indra dan zhang, ruochen dan adelani, david ifeoluwa},
Journal = {arxiv preprint arxiv: 2406.07424},
tahun = {2024}
}
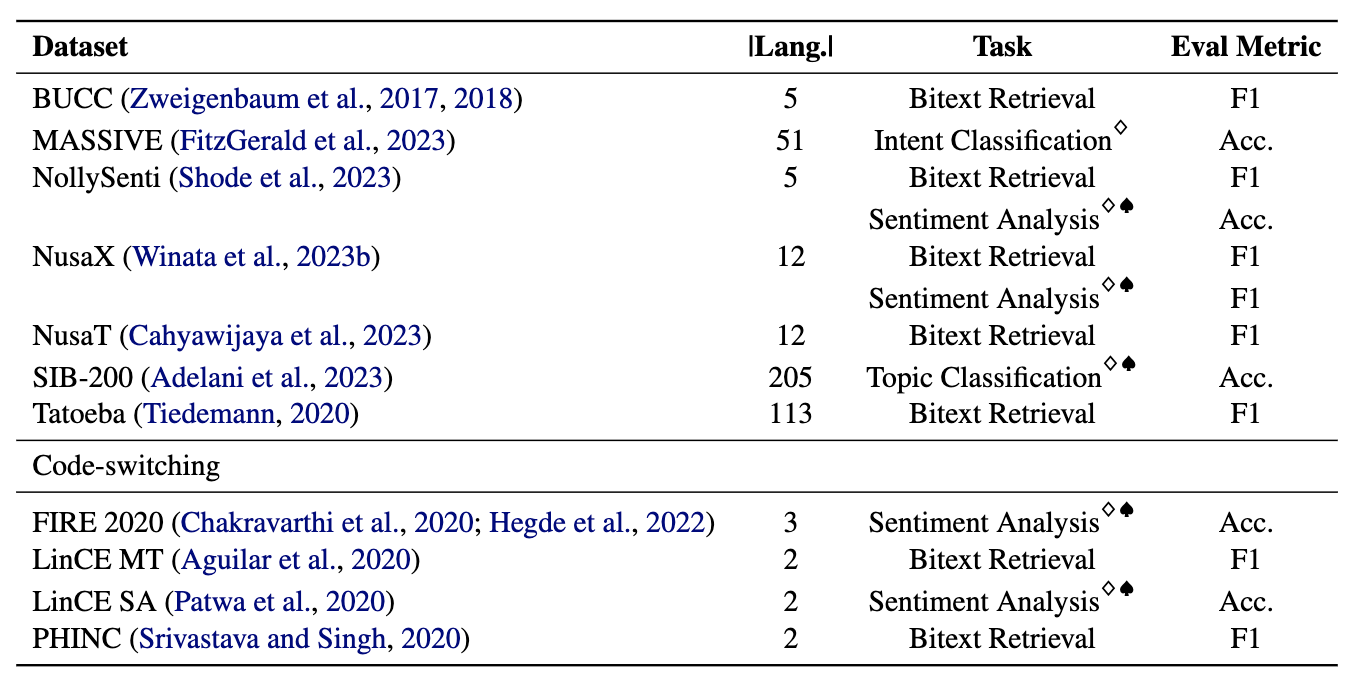
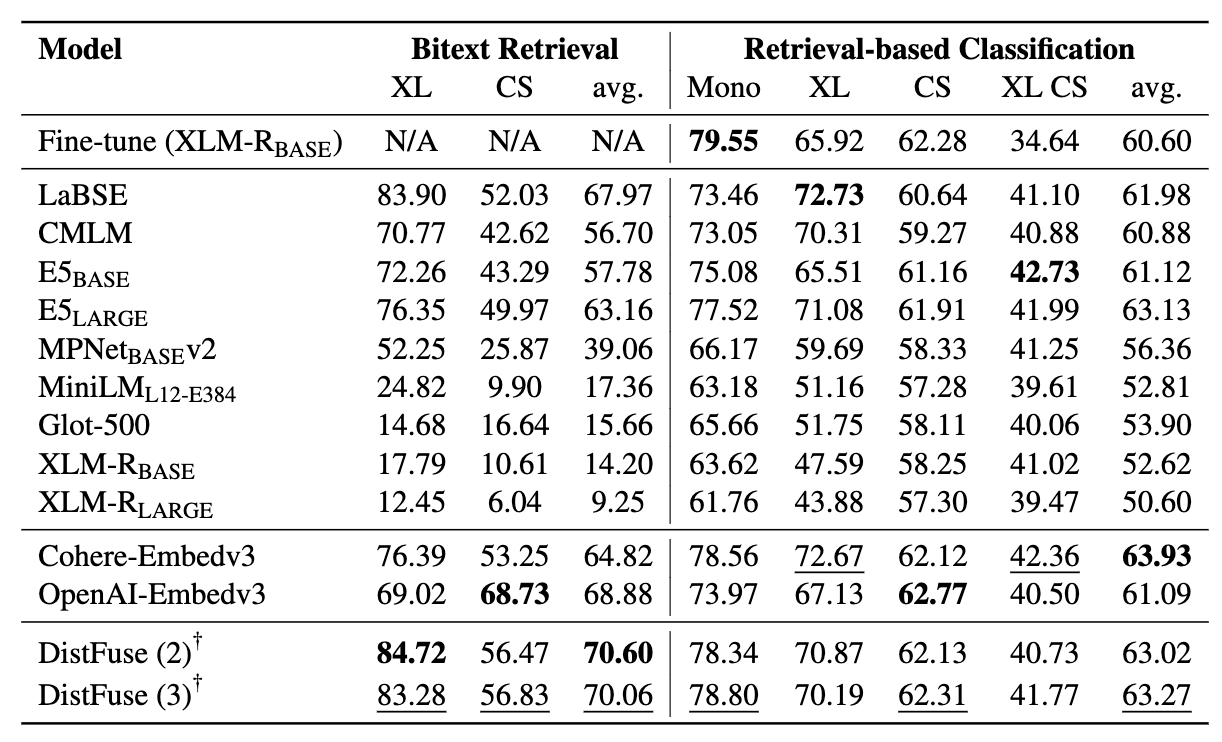
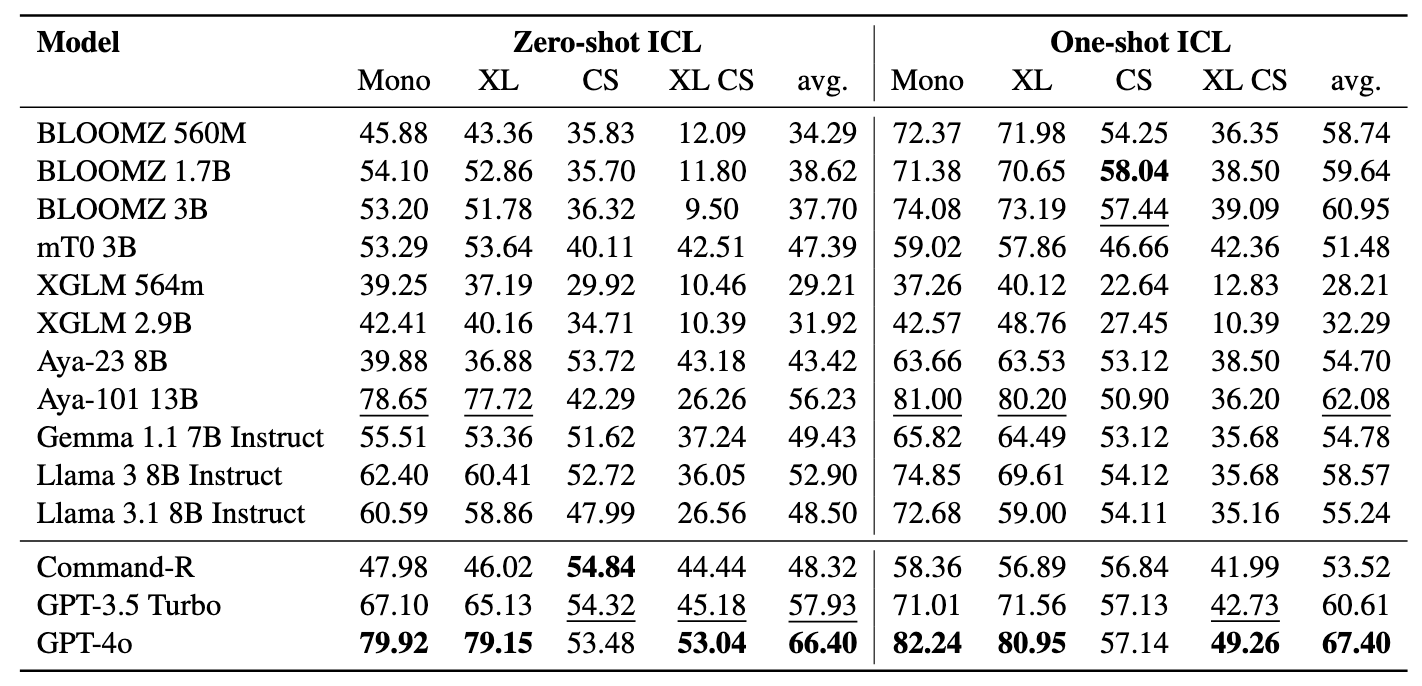
Penambang terdiri dari 11 kumpulan data: 7 dataset multibahasa dan 4 kode-switching, mencakup lebih dari 200 bahasa dan mencakup format paralel dan klasifikasi. Kumpulan data paralel cocok untuk pengambilan Bitext karena berisi konten multibahasa yang selaras, memfasilitasi penambangan Bitext dan tugas terjemahan mesin. Selain itu, dataset klasifikasi mencakup klasifikasi niat, analisis sentimen, dan klasifikasi topik, yang kami nilai untuk penugasan pengambilan dan klasifikasi ICL.
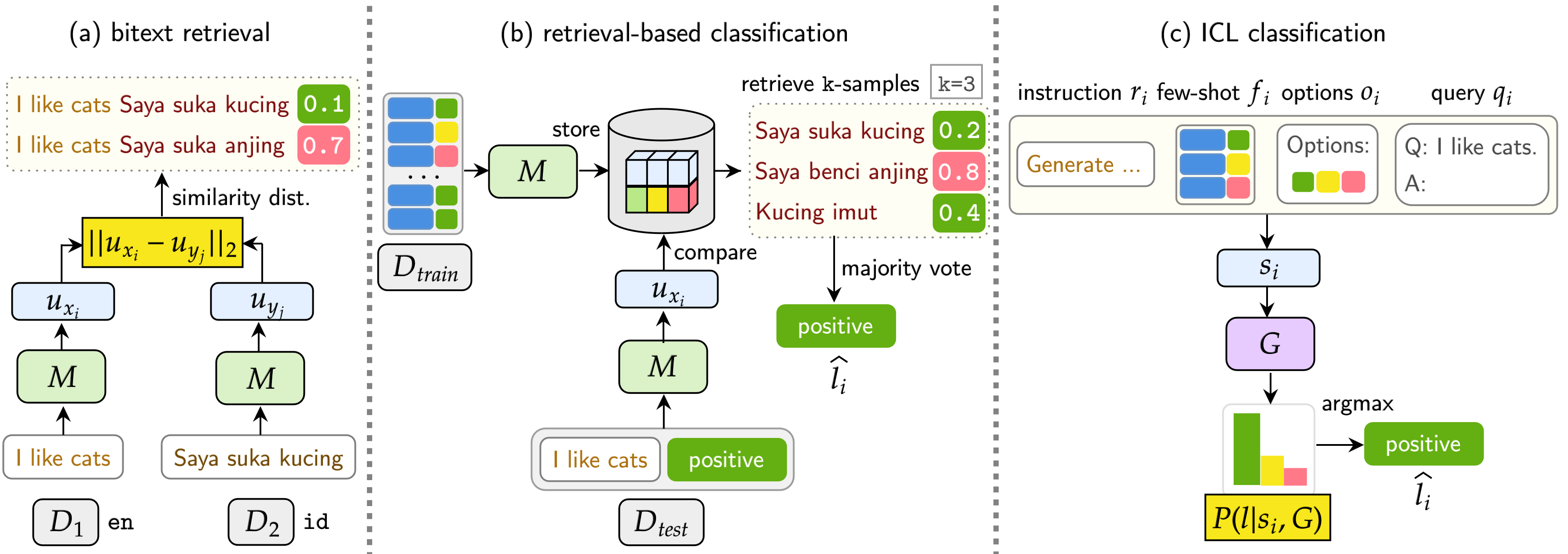
Benchmark kami mengevaluasi LMS pada tiga tugas: pengambilan Bitext, klasifikasi berbasis pengambilan, dan klasifikasi ICL. Pengaturan termasuk monolingual (mono) , cross-lingual (XS) , code-switching (CS) , dan cross-lingual code-switching (XS CS) .
pip install -r requirements.txt
Jika Anda ingin memanfaatkan API atau model dari OpenAi, Cohere, atau memeluk wajah, memodifikasi OPENAI_TOKEN , COHERE_TOKEN , dan HF_TOKEN . Perhatikan bahwa sebagian besar model pada wajah memeluk tidak memerlukan HF_TOKEN , yang secara khusus dimaksudkan untuk model Llama dan Gemma.
Jika Anda ingin menggunakan LLAMA3.1, Anda perlu meningkatkan versi Transformers
pip install transformers==4.44.2
Jika Anda ingin mendapatkan semua hasil dan contoh cepat dari eksperimen kami, jangan ragu untuk mengunduhnya di sini (~ 360MB).
Semua hasil percobaan akan disimpan di logs/ direktori. Anda dapat menjalankan setiap percobaan menggunakan perintah berikut:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Argumennya serupa seperti di atas, kecuali yang kami gunakan --model_checkpoints dan --weights
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Tambahkan --src_lang dan --cross ke perintah.
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Argumennya serupa seperti di atas, kecuali yang kami gunakan --model_checkpoints dan --weights
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Tambahkan --src_lang dan --cross ke perintah.
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Tambahkan --k untuk memodifikasi jumlah sampel yang diambil.
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
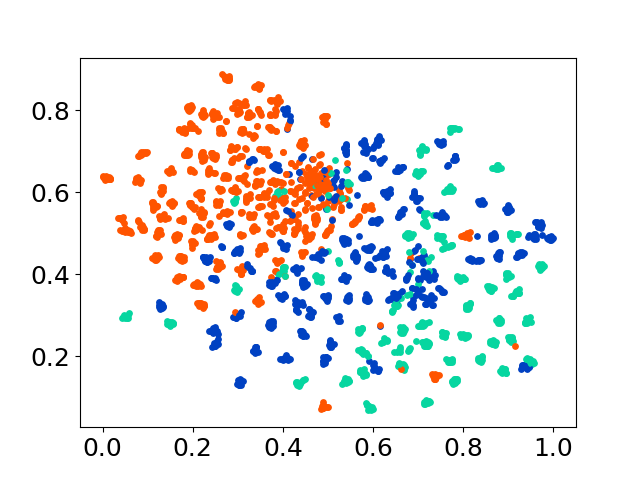
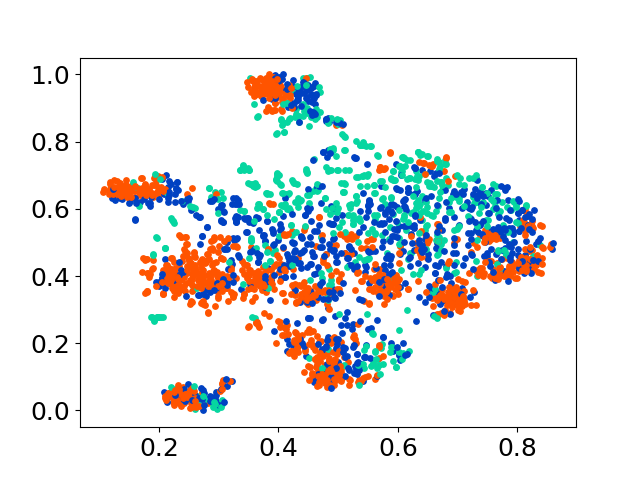
Basis kode kami mendukung penggunaan beberapa model untuk percobaan, memberikan fleksibilitas untuk kustomisasi di luar daftar yang ditunjukkan di bawah ini:
Jangan ragu untuk membuat masalah jika Anda memiliki pertanyaan. Dan, buat PR untuk memperbaiki bug atau menambahkan perbaikan (yaitu, menambahkan set data atau model baru).
Jika Anda tertarik untuk membuat perpanjangan dari pekerjaan ini, jangan ragu untuk menjangkau kami!
Dukung upaya open source kami
Kami meningkatkan kode untuk membuatnya lebih ramah pengguna dan dapat disesuaikan. Kami telah membuat repositori baru untuk mengimplementasikan Distfuse, yang tersedia di https://github.com/gentaiscool/distfuse/. Anda dapat menginstalnya dengan menjalankan pip install distfuse . Kemudian, itu akan diintegrasikan ke repositori ini.


