miners
1.0.0
 :多语言语言模型作为语义检索器
:多语言语言模型作为语义检索器⚡介绍矿工基准,旨在评估多语言LMS在语义检索任务中的能力,包括通过检索授权的上下文而无需进行微调,包括Bitext挖掘和分类。已经开发了一个全面的框架,以评估语言模型在检索200多种不同语言的样本中的有效性,包括具有挑战性的跨语言(XS)和代码转换(CS)设置中的低资源语言。结果表明,通过仅检索语义上相似的嵌入而无需进行任何微调,可以通过最先进的方法实现竞争性能。
该论文已在EMNLP 2024调查结果中接受。
这是论文[arxiv]的源代码:
此代码是使用Pytorch编写的。如果您在研究中使用此工具包中的任何代码或数据集,请引用相关论文。
@article {winata2024miners,
title = {矿工:多语言语言模型作为语义回收者},
作者= {Winata,Genta Indra和Zhang,Ruochen和Adelani,David Ifeoluwa},
日记= {arXiv预印arxiv:2406.07424},
年= {2024}
}
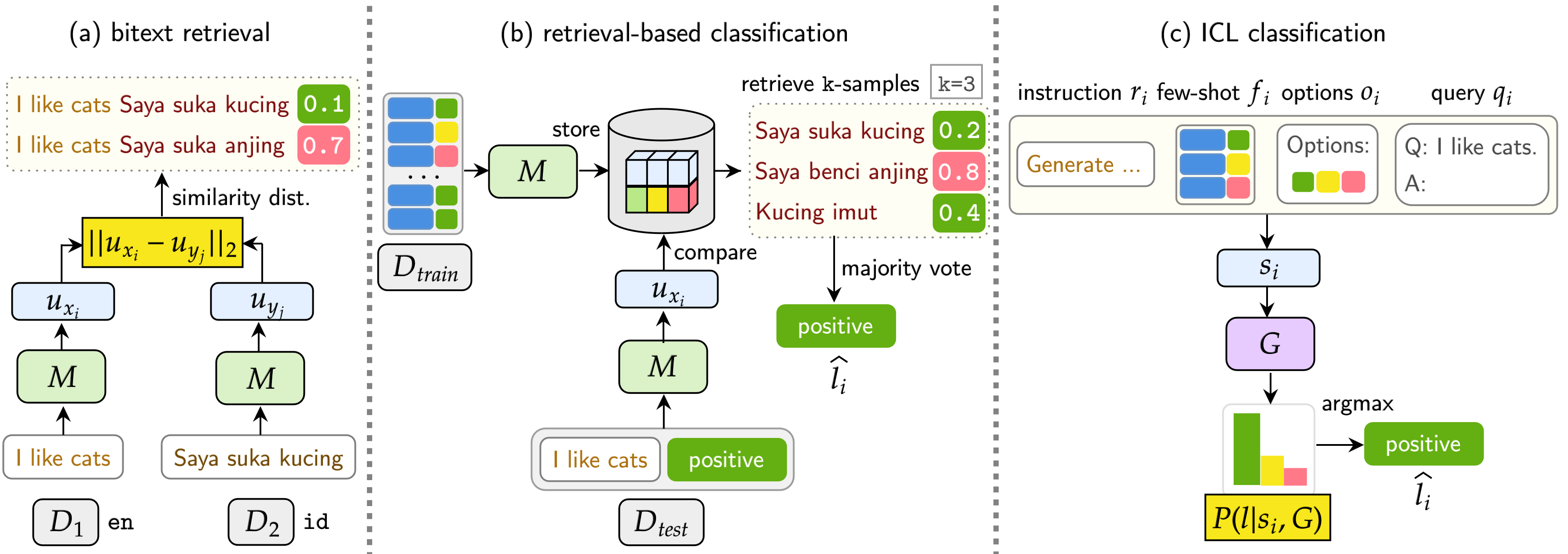
矿工包含11个数据集: 7个多语言和4个代码转换数据集,涵盖200多种语言,并涵盖并行和分类格式。并行数据集适用于BiteXT检索,因为它们包含对齐的多语言内容,促进Bitext挖掘和机器翻译任务。此外,分类数据集涵盖了意图分类,情感分析和主题分类,我们评估了基于检索和ICL分类分配。
我们的基准测试评估了LMS在三个任务上:BiteXT检索,基于检索的分类和ICL分类。这些设置包括单语(单声道) ,跨语义(XS) ,代码切换(CS)和跨语言代码转换(XS CS) 。
pip install -r requirements.txt
如果您想利用OpenAI,Cohere或Hugging Face的API或模型,请修改OPENAI_TOKEN , COHERE_TOKEN和HF_TOKEN 。请注意,大多数拥抱脸上的模型都不需要HF_TOKEN ,这是专门用于Llama和Gemma型号的。
如果您想使用Llama3.1,则需要升级变压器版本
pip install transformers==4.44.2
如果您想从我们的实验中获取所有结果并迅速示例,请随时在此处下载它们(〜360MB)。
所有实验结果将存储在logs/目录中。您可以使用以下命令执行每个实验:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
这些参数与--weights --model_checkpoints
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
添加--src_lang和--cross到命令。
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
这些参数与--weights --model_checkpoints
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
添加--src_lang和--cross到命令。
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
添加--k修改检索样品的数量。
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
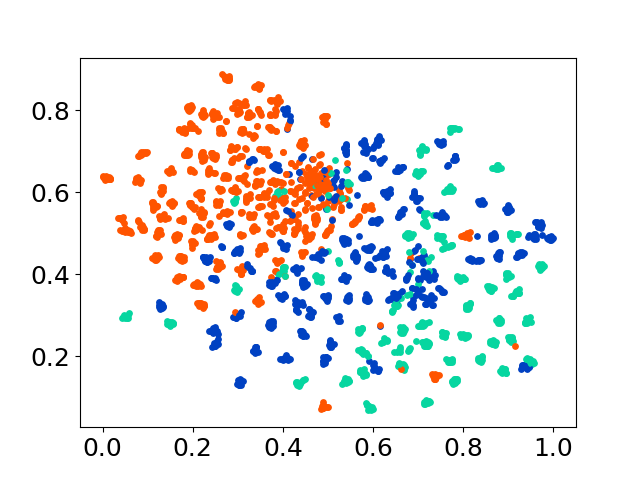
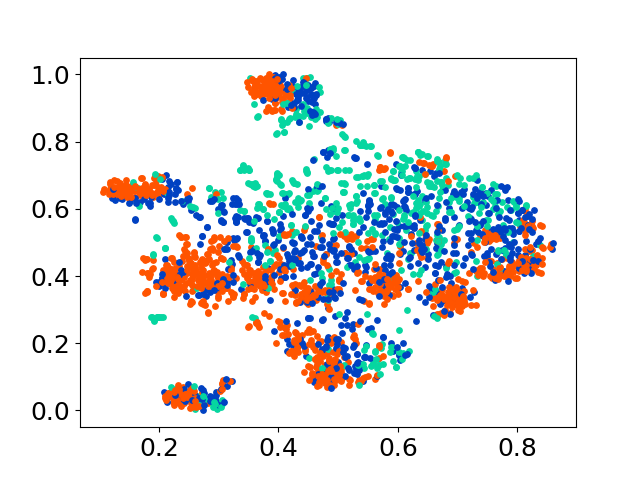
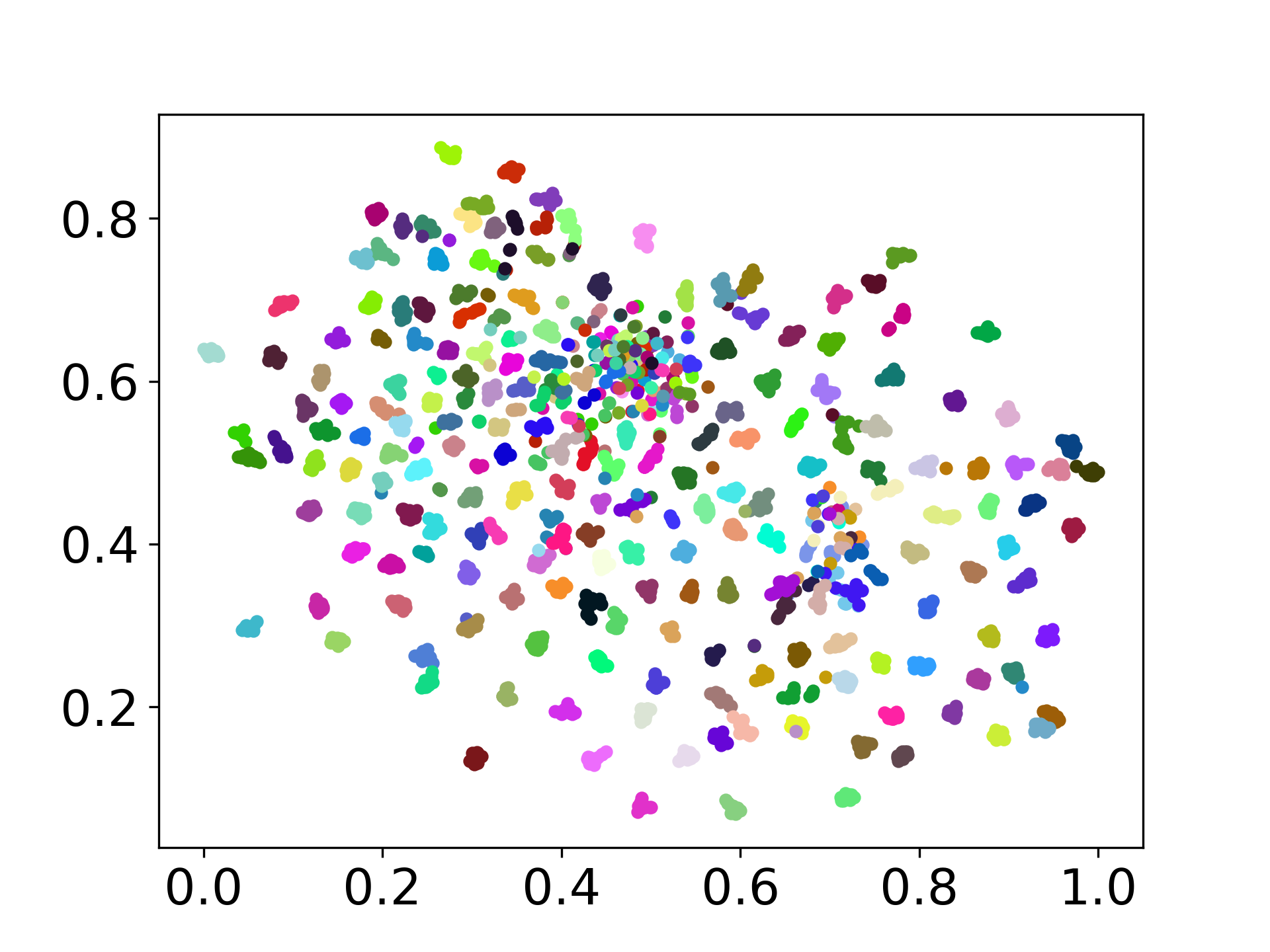
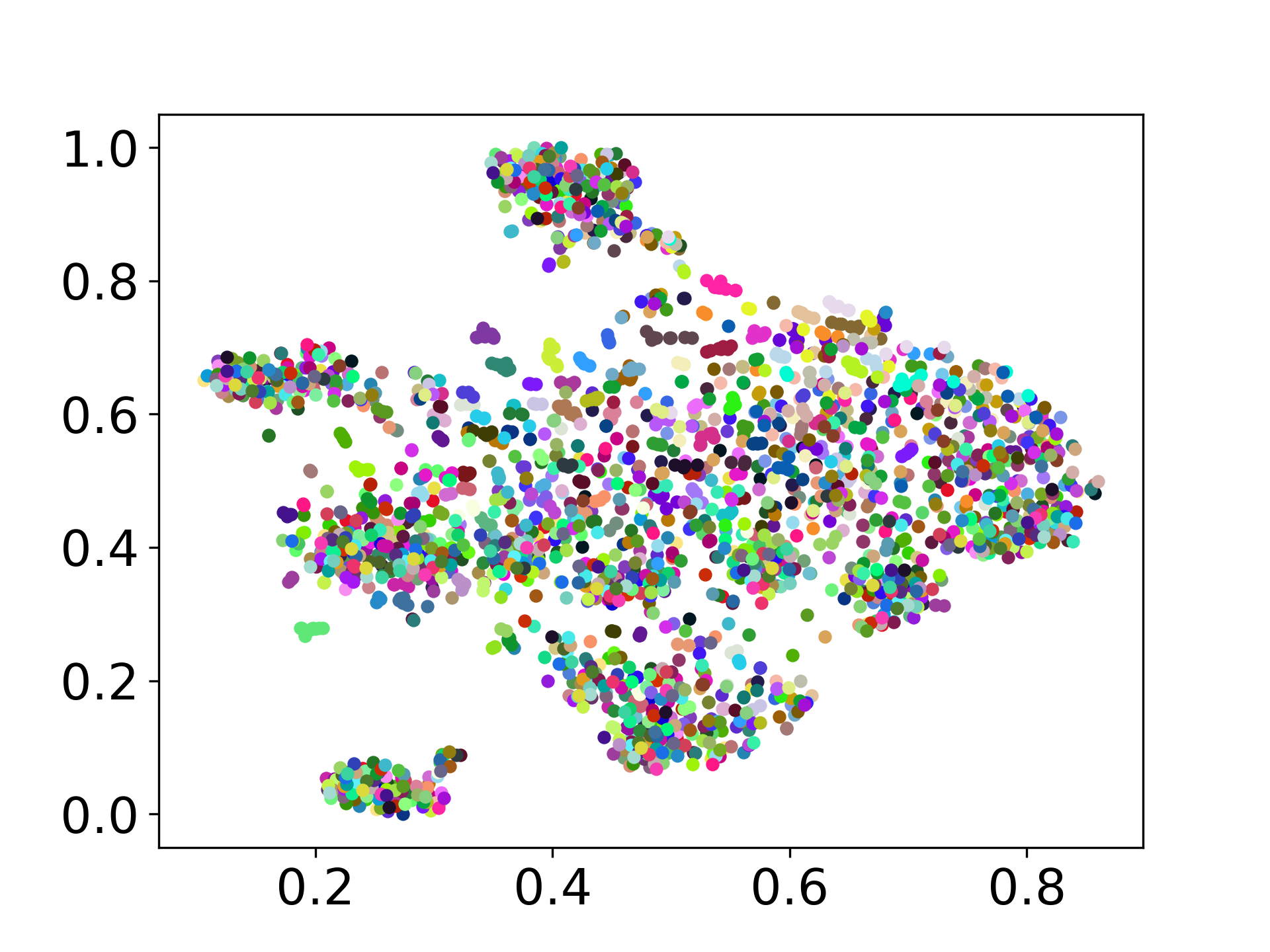
我们的代码库支持多个模型的实验使用,为自定义提供了灵活性,超出了以下所示的列表:
如果您有任何疑问,请随时创建问题。并且,创建用于修复错误或添加改进的PR(即,添加新数据集或模型)。
如果您有兴趣创建这项工作的扩展,请随时与我们联系!
支持我们的开源工作
我们正在改进代码,以使其更具用户友好和可自定义。我们已经创建了一个用于实现DistFuse的新存储库,该存储库可在https://github.com/gentaiscool/distfuse/上找到。您可以通过运行pip install distfuse来安装它。后来,它将集成到此存储库中。


