miners
1.0.0
 : نماذج اللغة متعددة اللغات كمستردين دلاليين
: نماذج اللغة متعددة اللغات كمستردين دلاليين⚡ إدخال معايير عمال المناجم ، المصممة لتقييم براعة LMS متعددة اللغات في مهام الاسترجاع الدلالية ، بما في ذلك تعدين لدغة وتصنيف من خلال السياقات التي يتم تجهيزها الاسترجاع دون صقل . تم تطوير إطار شامل لتقييم فعالية نماذج اللغة في استرداد العينات عبر أكثر من 200 لغة متنوعة ، بما في ذلك اللغات ذات الموارد المنخفضة في إعدادات التحدي عبر اللغات (XS) وإعدادات تبديل الكود (CS) . أظهرت النتائج أن تحقيق الأداء التنافسي مع أحدث الأساليب أمر ممكن من خلال استرداد التضمينات المتشابهة بشكل دلالي فقط ، دون الحاجة إلى أي صقل.
تم قبول الورقة في نتائج EMNLP 2024.
هذا هو الكود المصدري للورقة [arxiv]:
تمت كتابة هذا الرمز باستخدام Pytorch. إذا كنت تستخدم أي رمز أو مجموعات بيانات من مجموعة الأدوات هذه في بحثك ، فيرجى الاستشهاد بالورقة المرتبطة بها.
article {winata2024miners ،
title = {Miners: Multilingual Language Models as Defrid
المؤلف = {Winata ، Genta Indra و Zhang ، Ruochen و Adelani ، David Ifeoluwa} ،
Journal = {arxiv preprint arxiv: 2406.07424} ،
السنة = {2024}
}
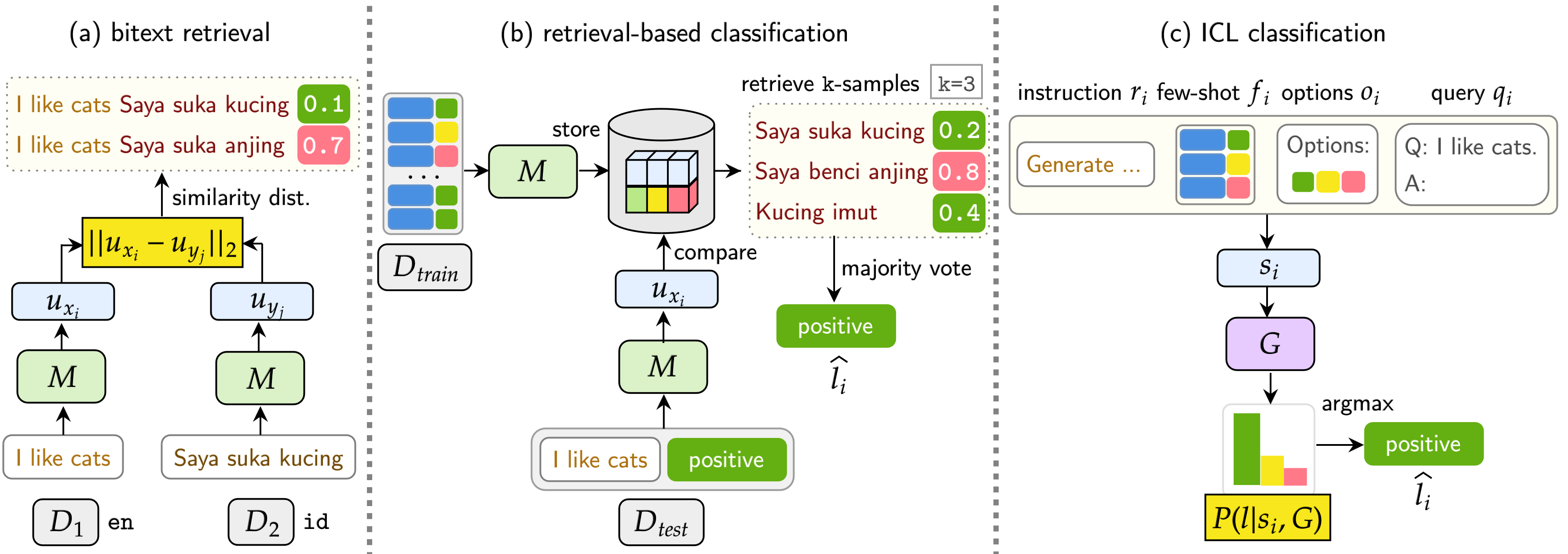
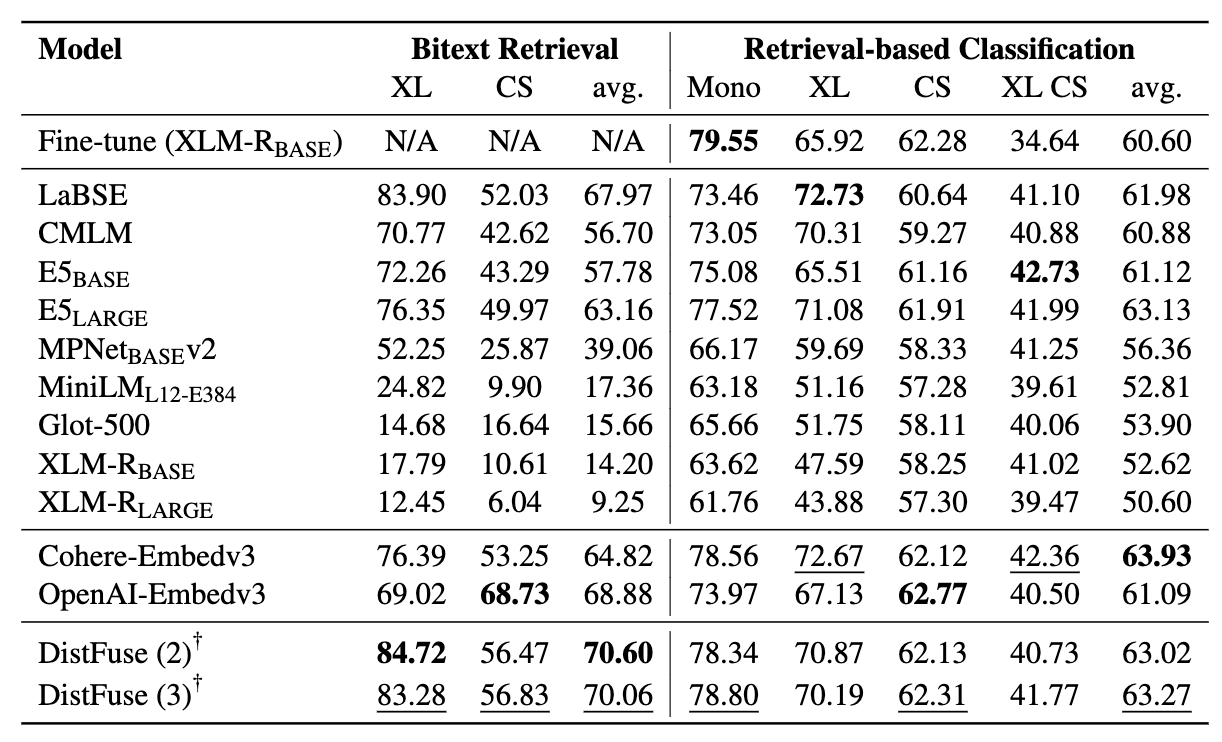
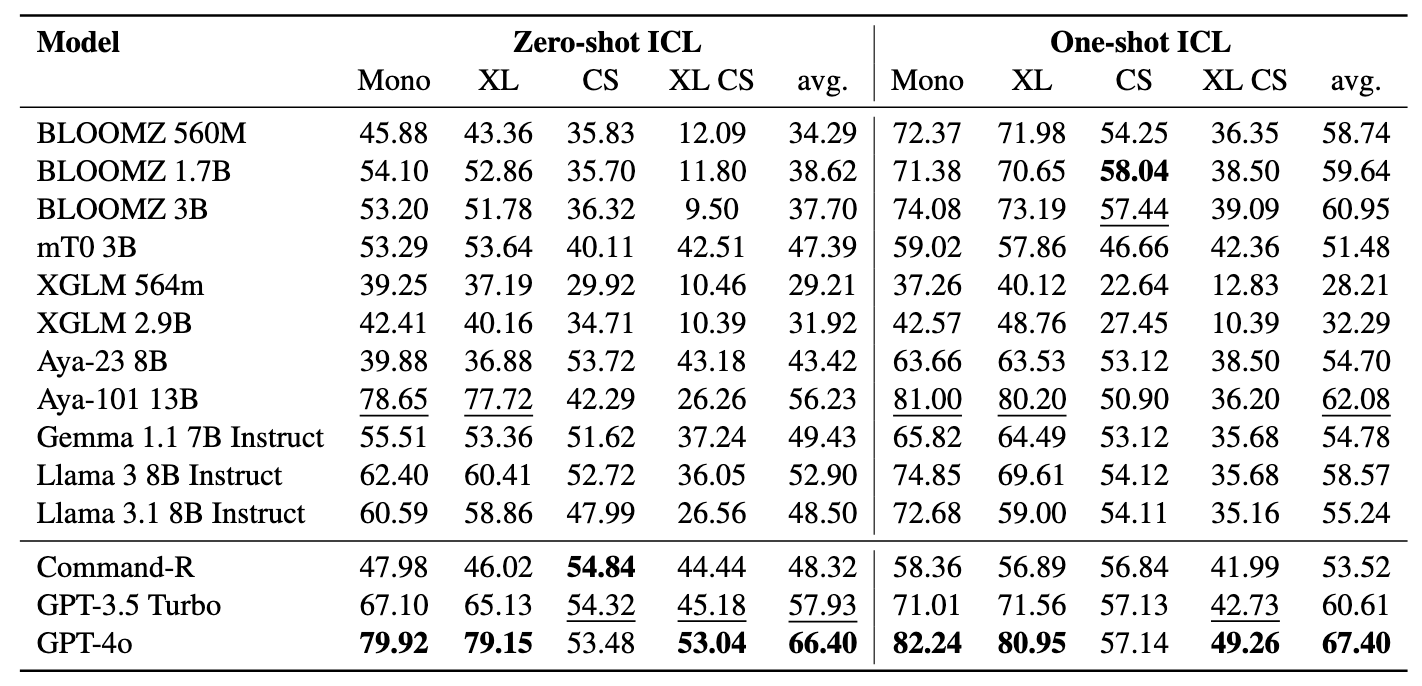
يتكون عمال المناجم من 11 مجموعة بيانات: 7 مجموعات بيانات متعددة اللغات و 4 رمز ، تغطي أكثر من 200 لغة وتشمل كل من تنسيقات الموازية والتصنيف. تعد مجموعات البيانات المتوازية مناسبة لاسترداد Bitext لأنها تحتوي على محتوى متعدد اللغات محاذاة ، مما يسهل تعدين اللدغة ومهام الترجمة الآلية. بالإضافة إلى ذلك ، تغطي مجموعات بيانات التصنيف تصنيف نية ، تحليل المشاعر ، وتصنيف الموضوع ، والتي نقوم بتقييمها لتخصيصات التصنيف القائمة على الاسترجاع وتصنيف ICL.
يقيم مؤشرنا LMS على ثلاث مهام: Bitext Retrieval ، وتصنيف الاسترجاع ، وتصنيف ICL. تشمل الإعدادات أحادية اللغة (أحادية) ، واضطراب (XS) ، وتبديل التعليمات البرمجية (CS) ، وتبديل الكود عبر اللغات (XS CS) .
pip install -r requirements.txt
إذا كنت ترغب في استخدام واجهات برمجة التطبيقات أو النماذج من Openai أو Cohere أو معانقة الوجه ، فقم بتعديل OPENAI_TOKEN و COHERE_TOKEN و HF_TOKEN . لاحظ أن معظم الطرز على وجه المعانقة لا تتطلب HF_TOKEN ، والتي تمثلها خصيصًا لنماذج Llama و Gemma.
إذا كنت ترغب في استخدام Llama3.1 ، فأنت بحاجة إلى ترقية إصدار Transformers
pip install transformers==4.44.2
إذا كنت ترغب في الحصول على جميع النتائج والأمثلة السريعة من تجاربنا ، فلا تتردد في تنزيلها هنا (حوالي 360 ميجابايت).
سيتم تخزين جميع نتائج التجربة في logs/ الدليل. يمكنك تنفيذ كل تجربة باستخدام الأوامر التالية:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
الوسيطات متشابهة على النحو الوارد أعلاه ، باستثناء أننا نستخدم --model_checkpoints و --weights
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
إضافة --src_lang و --cross إلى الأمر.
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
الوسيطات متشابهة على النحو الوارد أعلاه ، باستثناء أننا نستخدم --model_checkpoints و --weights
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
إضافة --src_lang و --cross إلى الأمر.
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
إضافة --k لتعديل عدد العينات التي تم استردادها.
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
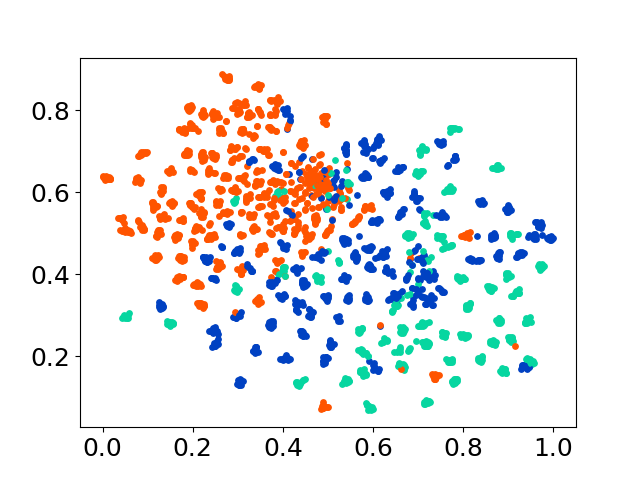
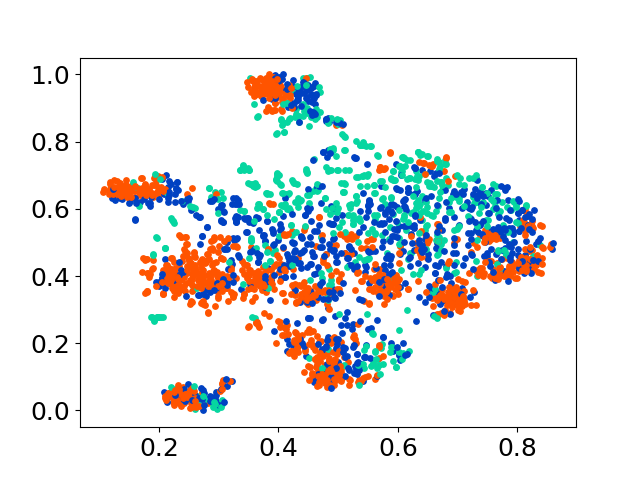
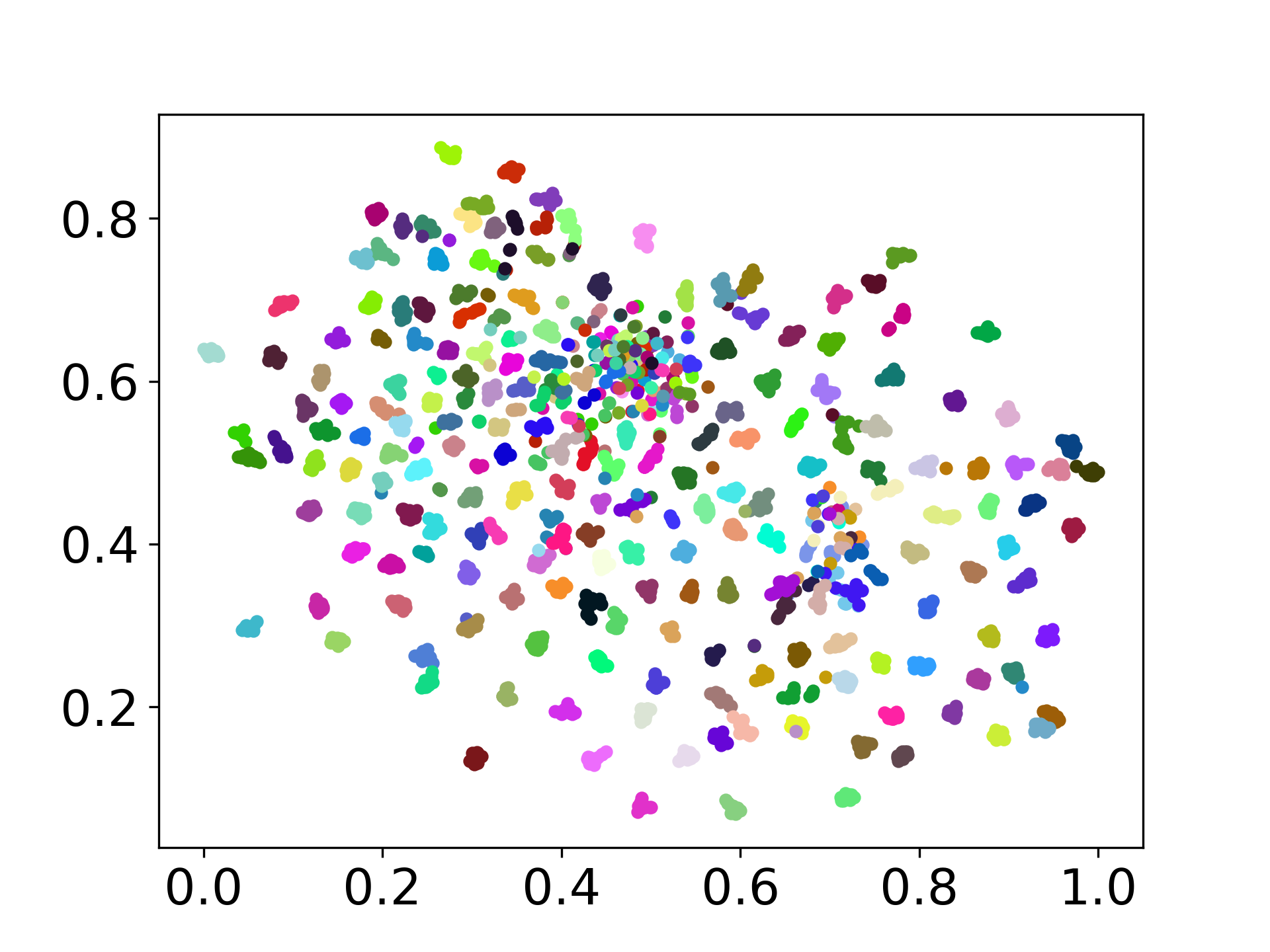
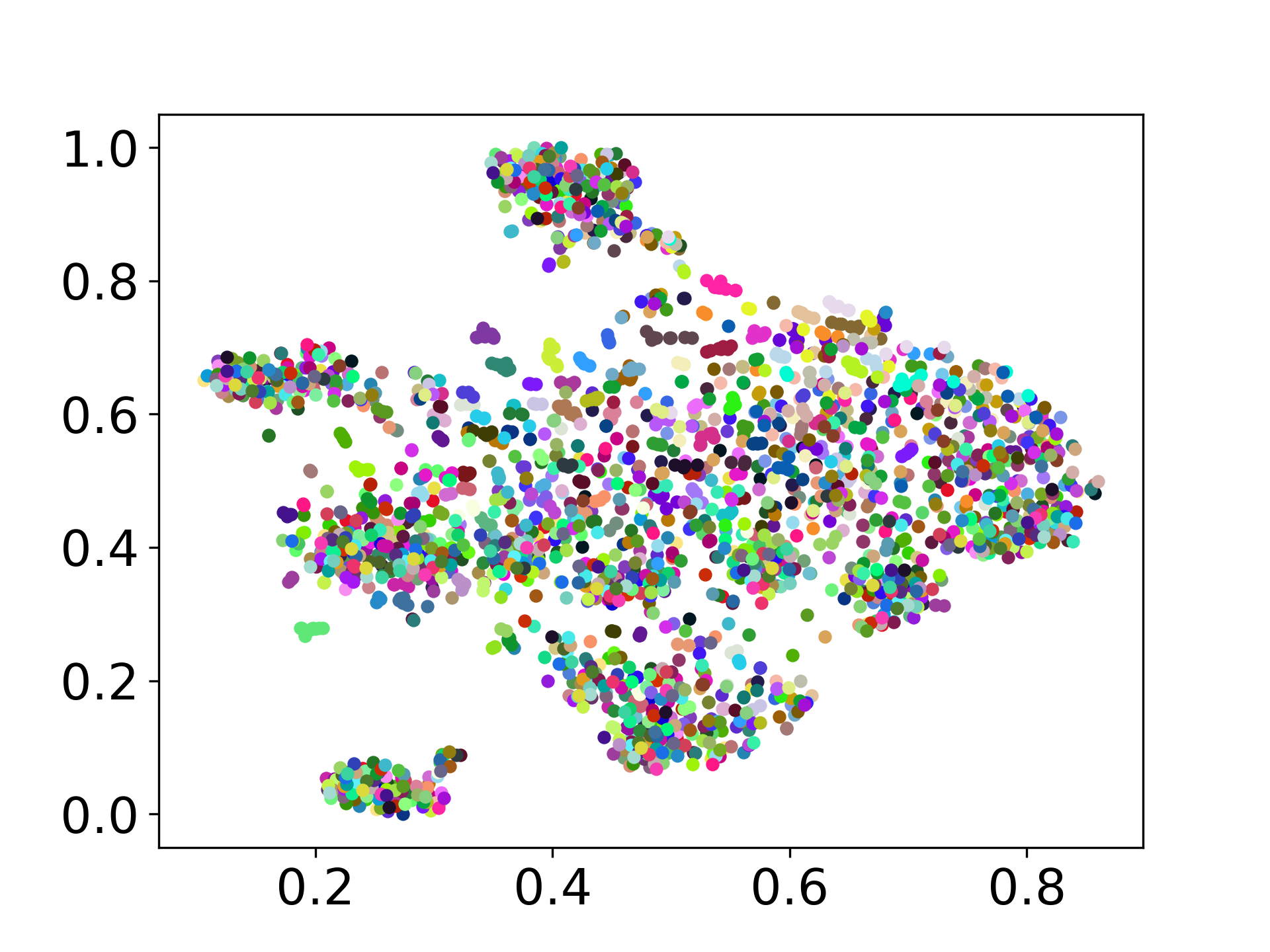
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
تدعم قاعدة كودنا استخدام نماذج متعددة للتجارب ، مما يوفر مرونة للتخصيص خارج القائمة الموضحة أدناه:
لا تتردد في إنشاء مشكلة إذا كان لديك أي أسئلة. وإنشاء PR لإصلاح الأخطاء أو إضافة تحسينات (أي إضافة مجموعات بيانات أو نماذج جديدة).
إذا كنت مهتمًا بإنشاء تمديد لهذا العمل ، فلا تتردد في التواصل معنا!
دعم جهدنا مفتوح المصدر
نحن نحسن الرمز لجعله أكثر سهولة في الاستخدام وقابل للتخصيص. لقد أنشأنا مستودعًا جديدًا لتنفيذ DistFuse ، وهو متاح على https://github.com/gentaiscool/distfuse/. يمكنك تثبيته عن طريق تشغيل pip install distfuse . في وقت لاحق ، سيتم دمجها في هذا المستودع.


