miners
1.0.0
 : Modelos de idiomas multilingües como retrievers semánticos
: Modelos de idiomas multilingües como retrievers semánticos⚡ Introducir el punto de referencia de los mineros , diseñado para evaluar la destreza de LMS multilingüe en tareas de recuperación semántica, incluida la minería y la clasificación de BITEXT a través de contextos acuáticos de recuperación sin ajustar . Se ha desarrollado un marco integral para evaluar la efectividad de los modelos de idiomas en la recuperación de muestras en más de 200 idiomas diversos , incluidos los idiomas de baja recursos en la desafiante entornos interlingües (XS) y de cambio de código (CS) . Los resultados muestran que lograr el rendimiento competitivo con los métodos de última generación es posible recuperando únicamente incrustaciones semánticamente similares, sin requerir ningún ajuste fino.
El documento ha sido aceptado en los hallazgos de EMNLP 2024.
Este es el código fuente del documento [ARXIV]:
Este código ha sido escrito con Pytorch. Si usa algún código o conjunto de datos de este conjunto de herramientas en su investigación, cita el documento asociado.
@article {winata2024miners,
title = {mineros: modelos de lenguaje multilingüe como retrievers semánticos},
Autor = {Winata, Genta Indra y Zhang, Ruochen y Adelani, David Ifeoluwa},
Journal = {arxiv preprint arxiv: 2406.07424},
año = {2024}
}
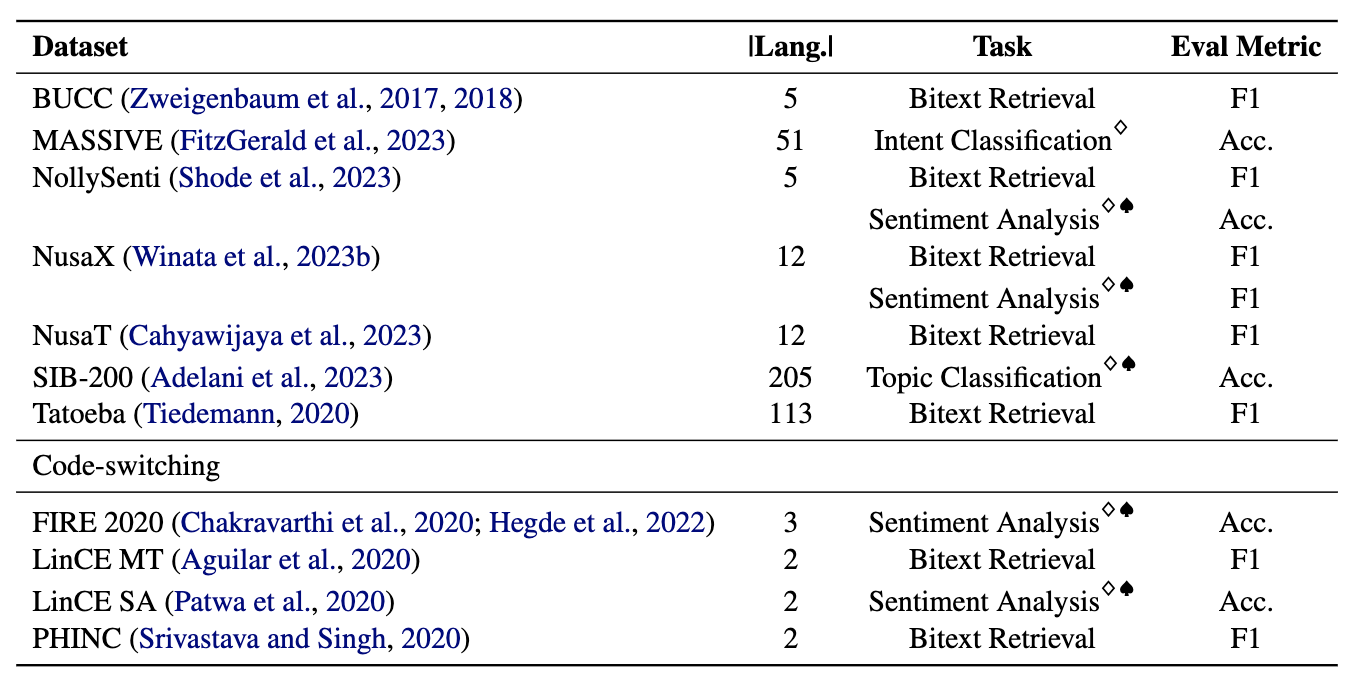
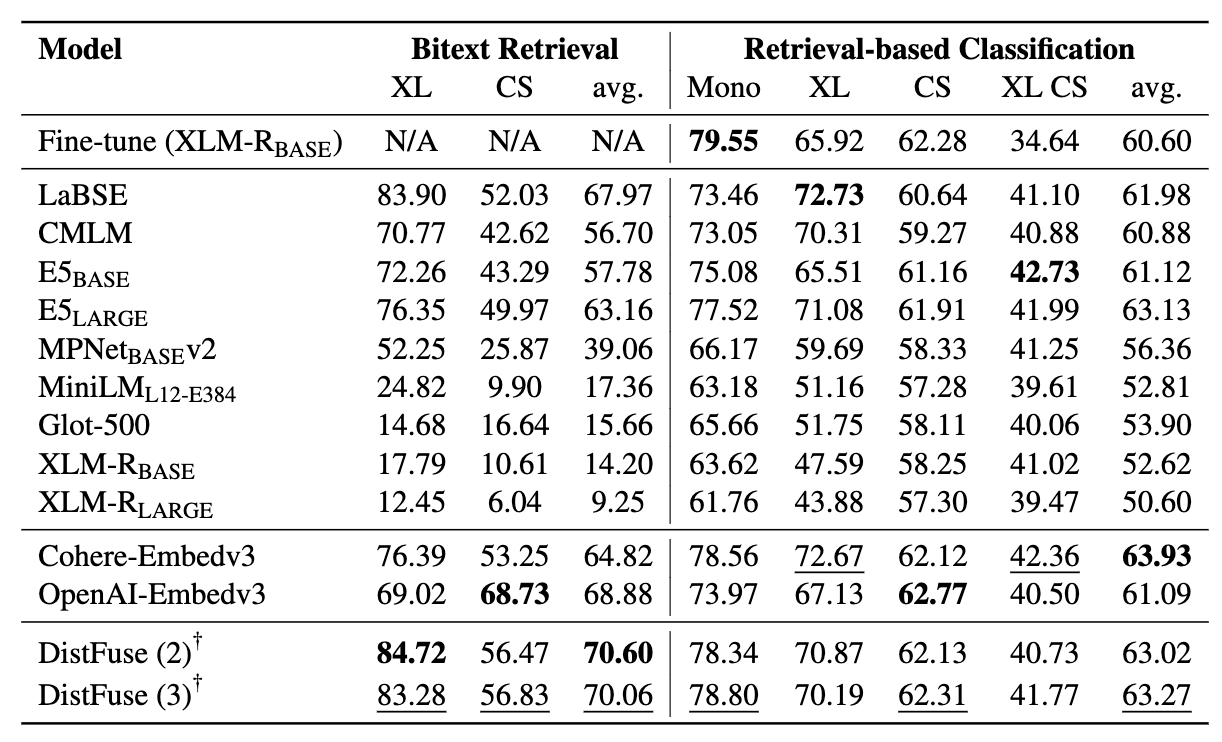
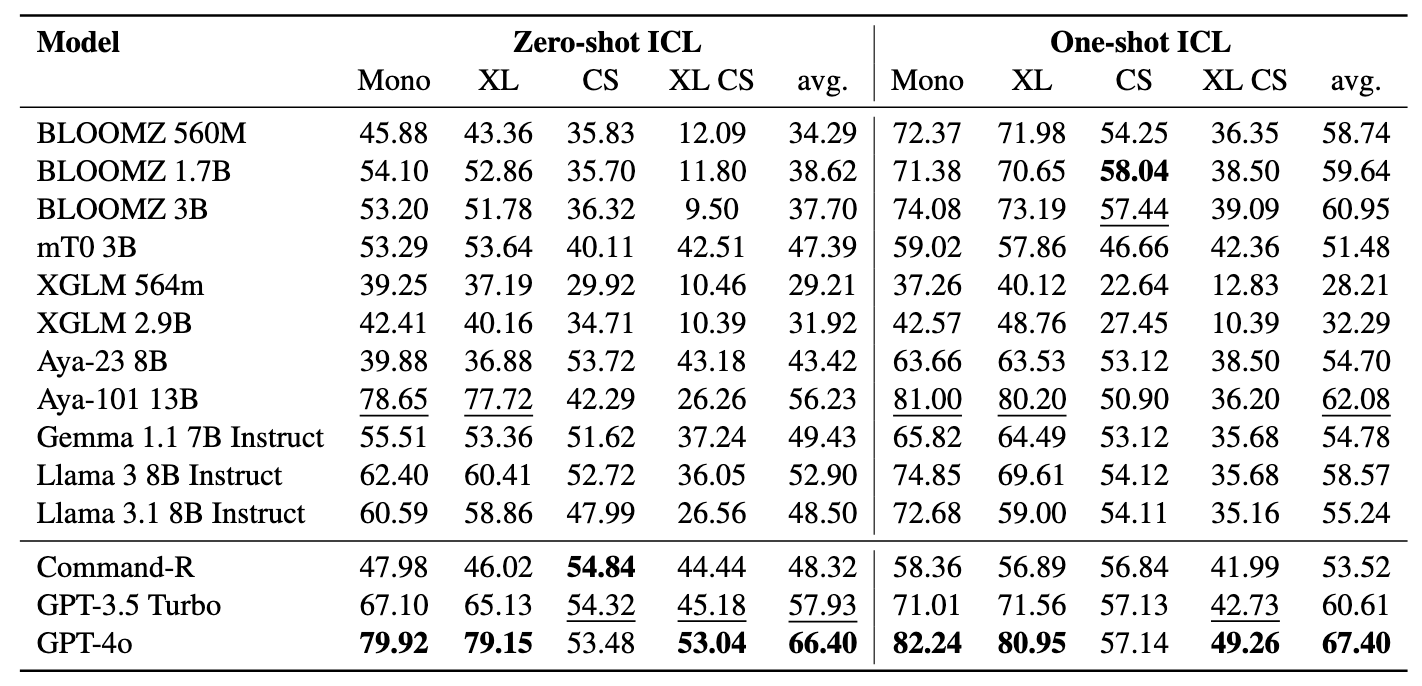
Los mineros comprenden 11 conjuntos de datos: 7 conjuntos de datos multilingües y 4 de conmutación de código, que cubren más de 200 idiomas y abarcan formatos paralelos y de clasificación. Los conjuntos de datos paralelos son adecuados para la recuperación de BITEXT, ya que contienen contenido multilingüe alineado, facilitando las tareas de minería y traducción automática de BITEXT. Además, los conjuntos de datos de clasificación cubren la clasificación de la intención, el análisis de sentimientos y la clasificación de temas, que evaluamos las tareas basadas en la recuperación y la clasificación de ICL.
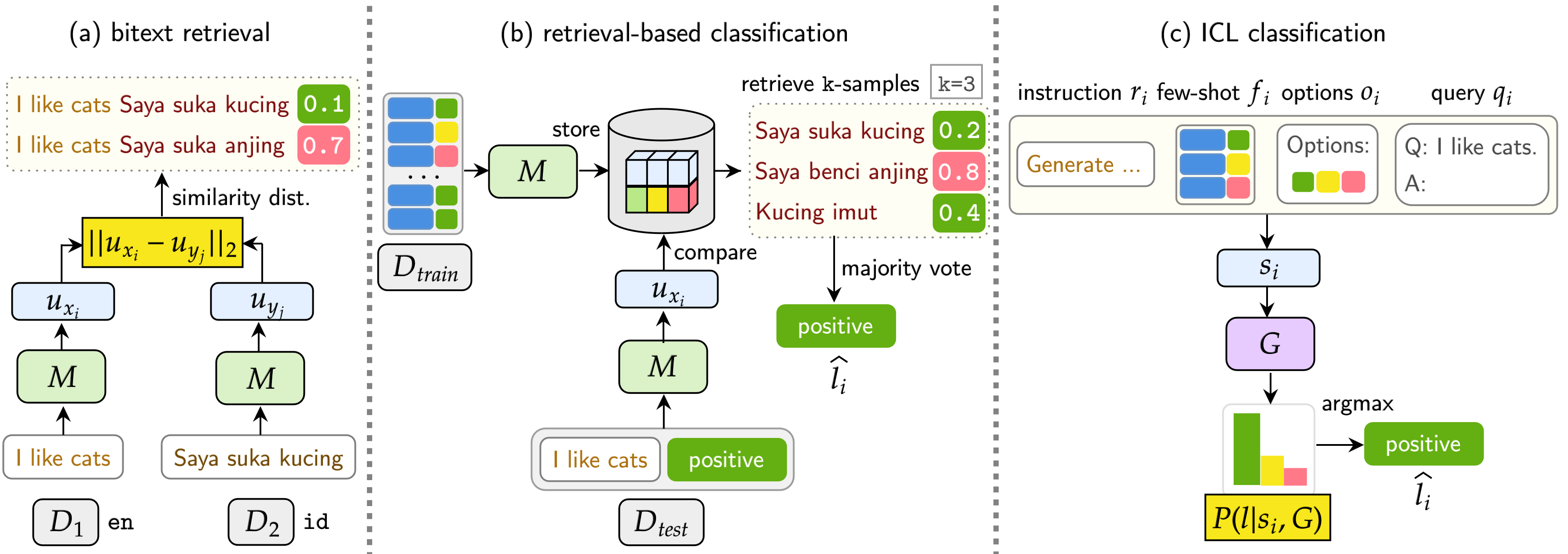
Nuestro punto de referencia evalúa LMS en tres tareas: recuperación de BITEXT, clasificación basada en la recuperación y clasificación de ICL. La configuración incluye monolingüe (mono) , interlingüe (XS) , conmutación de código (CS) y cambio de código interlingüístico (XS CS) .
pip install -r requirements.txt
Si desea utilizar las API o modelos de OpenAI, cohere o abrazar la cara, modifique el OPENAI_TOKEN , COHERE_TOKEN y HF_TOKEN . Tenga en cuenta que la mayoría de los modelos en la cara abrazada no requieren el HF_TOKEN , que está específicamente destinado a los modelos LLAMA y GEMMA.
Si desea usar Llama3.1, debe actualizar la versión Transformers
pip install transformers==4.44.2
Si desea obtener todos los resultados y ejemplos de inmediato de nuestros experimentos, no dude en descargarlos aquí (~ 360Mb).
Todos los resultados del experimento se almacenarán en los logs/ directorio. Puede ejecutar cada experimento usando los siguientes comandos:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Los argumentos son similares como anteriores, excepto que usamos --model_checkpoints y --weights
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Agregue --src_lang y --cross al comando.
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Los argumentos son similares como anteriores, excepto que usamos --model_checkpoints y --weights
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Agregue --src_lang y --cross al comando.
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Agregar --k para modificar el número de muestras recuperadas.
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
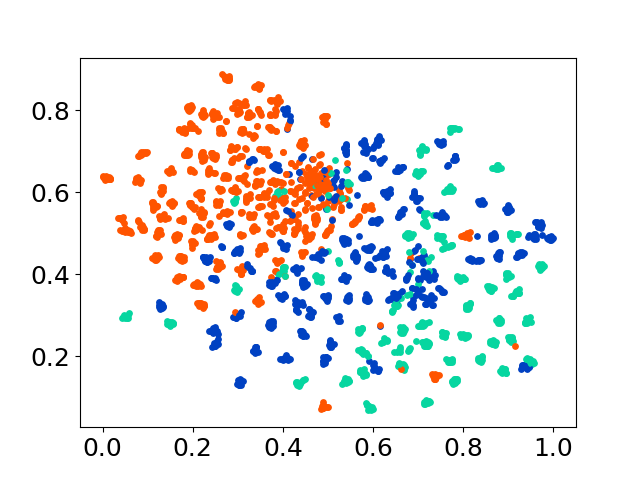
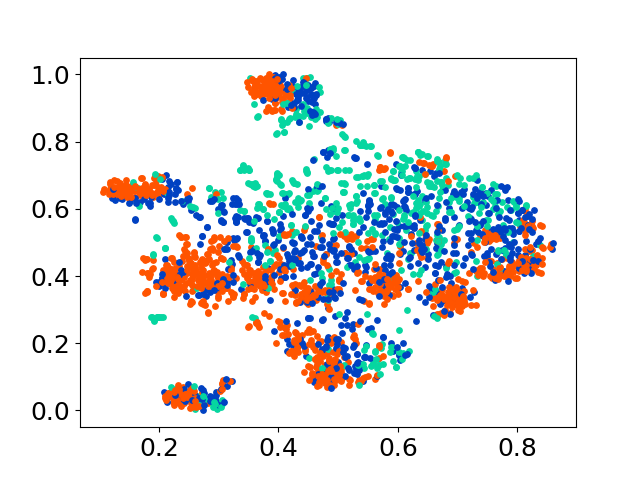
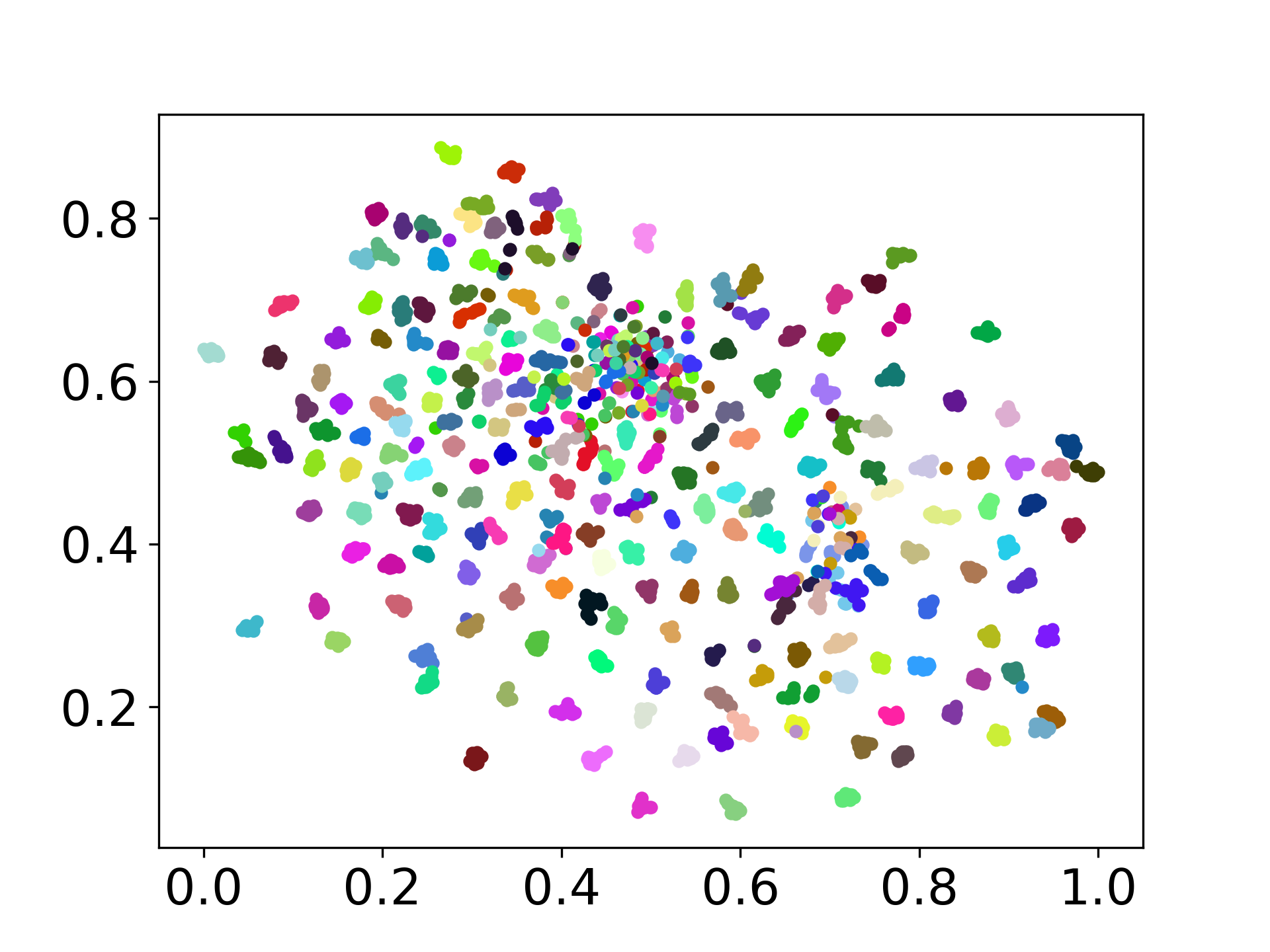
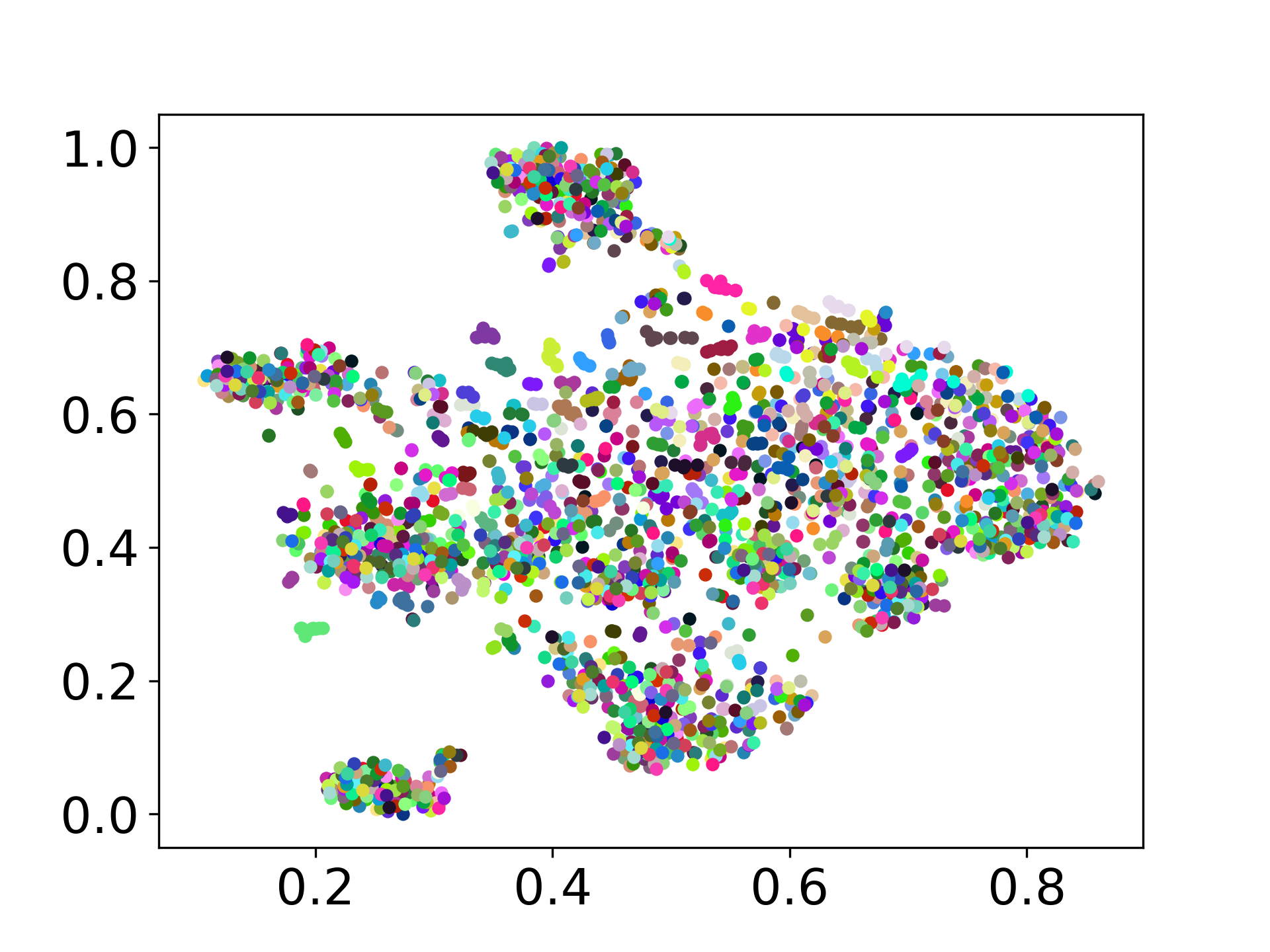
Nuestra base de código admite el uso de múltiples modelos para los experimentos, proporcionando flexibilidad para la personalización más allá de la lista que se muestra a continuación:
No dude en crear un problema si tiene alguna pregunta. Y, cree un PR para corregir errores o agregar mejoras (es decir, agregar nuevos conjuntos de datos o modelos).
Si está interesado en crear una extensión de este trabajo, ¡no dude en comunicarse con nosotros!
Apoyar nuestro esfuerzo de código abierto
Estamos mejorando el código para que sea más fácil de usar y personalizable. Hemos creado un nuevo repositorio para implementar Distfuse, que está disponible en https://github.com/gentaiscaol/distfuse/. Puede instalarlo ejecutando pip install distfuse . Más tarde, se integrará a este repositorio.


