miners
1.0.0
 : โมเดลภาษาหลายภาษาเป็นตัวดึงความหมาย
: โมเดลภาษาหลายภาษาเป็นตัวดึงความหมาย⚡แนะนำ เกณฑ์มาตรฐานของคนงาน ที่ออกแบบมาเพื่อประเมินความกล้าหาญของ LMS หลายภาษาในงานการดึงความหมายรวมถึงการขุด Bitext และการจำแนกผ่านบริบทการสืบค้น โดยไม่ต้องปรับแต่ง กรอบการทำงานที่ครอบคลุมได้รับการพัฒนาขึ้นเพื่อประเมินประสิทธิภาพของแบบจำลองภาษาในการดึงตัวอย่างผ่าน ภาษาที่หลากหลายกว่า 200 ภาษา รวมถึงภาษาที่มีทรัพยากรต่ำในการตั้ง ค่าข้ามภาษา (XS) และการตั้งค่า การสลับรหัส (CS) ผลการวิจัยพบว่าการบรรลุประสิทธิภาพการแข่งขันด้วยวิธีการที่ทันสมัยเป็นไปได้โดยการดึงการฝังตัวที่คล้ายกันแบบความหมายเพียงอย่างเดียวโดยไม่ต้องมีการปรับแต่งใด ๆ
กระดาษได้รับการยอมรับจากการค้นพบ EMNLP 2024
นี่คือซอร์สโค้ดของกระดาษ [arxiv]:
รหัสนี้เขียนขึ้นโดยใช้ Pytorch หากคุณใช้รหัสหรือชุดข้อมูลใด ๆ จากชุดเครื่องมือนี้ในการวิจัยของคุณโปรดอ้างอิงกระดาษที่เกี่ยวข้อง
@article {winata2024miners,
title = {คนงานเหมือง: โมเดลภาษาหลายภาษาเป็นตัวดึงความหมาย}
ผู้แต่ง = {Winata, Genta Indra และ Zhang, Ruochen และ Adelani, David Ifeoluwa}
journal = {arxiv preprint arxiv: 2406.07424},
ปี = {2024}
-
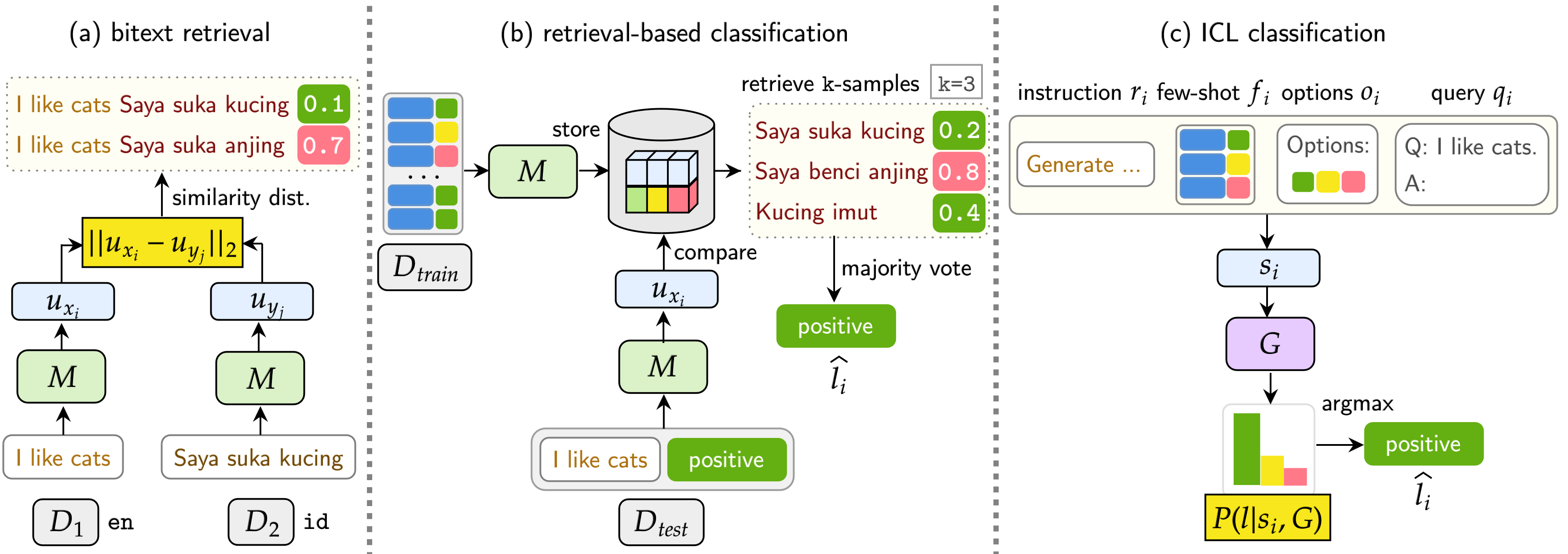
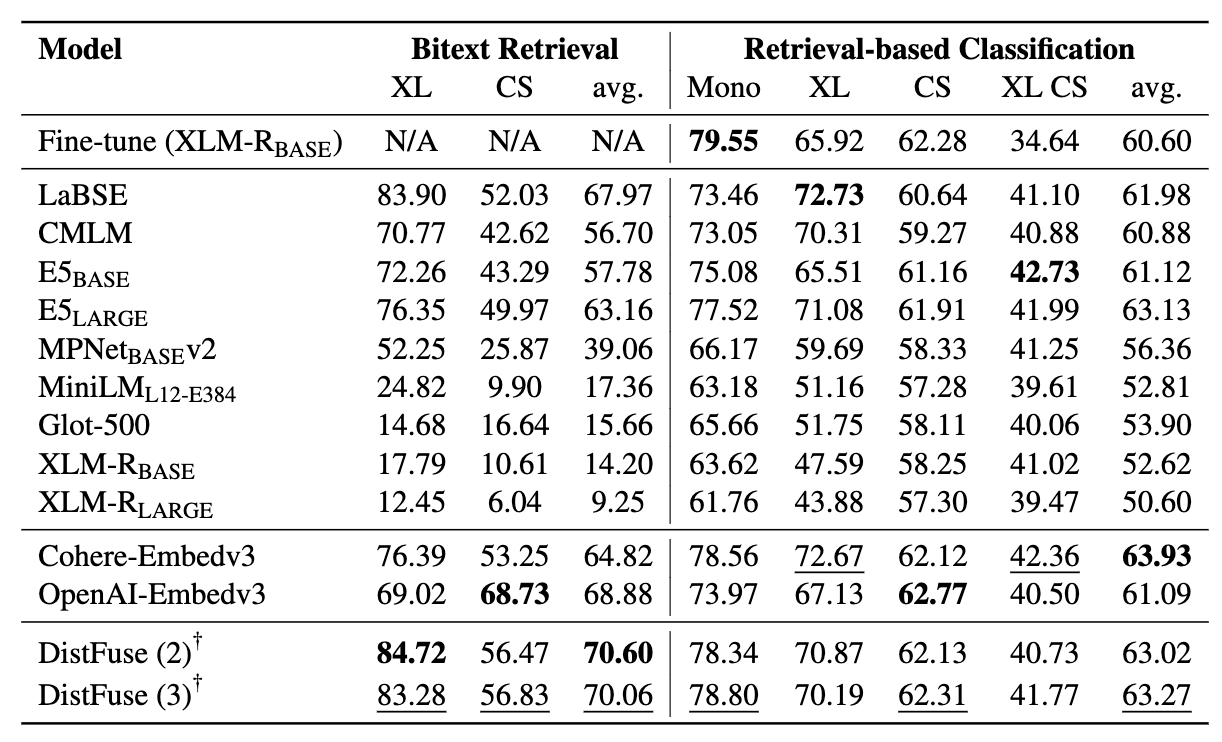
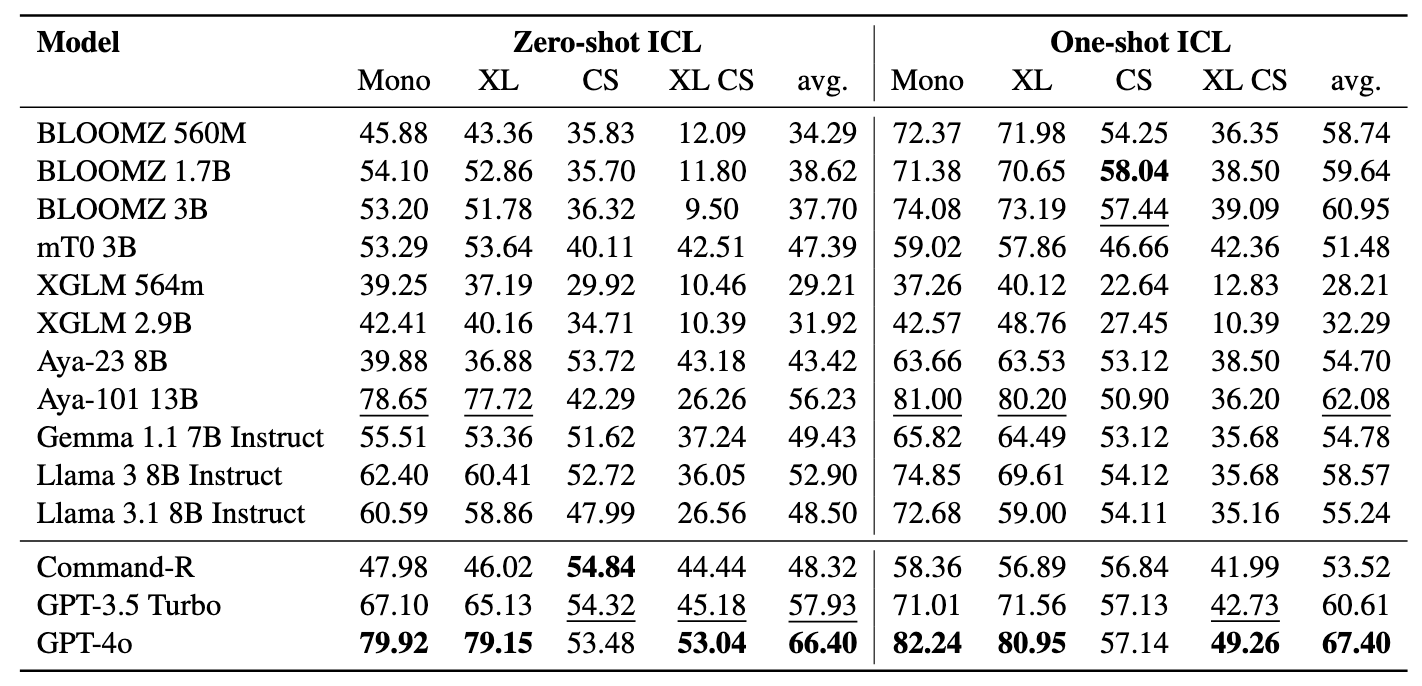
คนงานเหมืองประกอบด้วยชุดข้อมูล 11 ชุด : 7 ชุดข้อมูลหลายภาษาและ 4 ชุดข้อมูลสลับรหัสครอบคลุมมากกว่า 200 ภาษา และครอบคลุมทั้งรูปแบบขนานและการจำแนกประเภท ชุดข้อมูลแบบขนานเหมาะสำหรับการดึง Bitext เนื่องจากมีเนื้อหาหลายภาษาที่จัดเรียงกันซึ่งอำนวยความสะดวกในการทำเหมือง Bitext และงานแปลของเครื่อง นอกจากนี้ชุดข้อมูลการจำแนกประเภทยังครอบคลุมการจำแนกความตั้งใจการวิเคราะห์ความเชื่อมั่นและการจำแนกหัวข้อซึ่งเราประเมินการกำหนดการจำแนกประเภทการดึงและ ICL
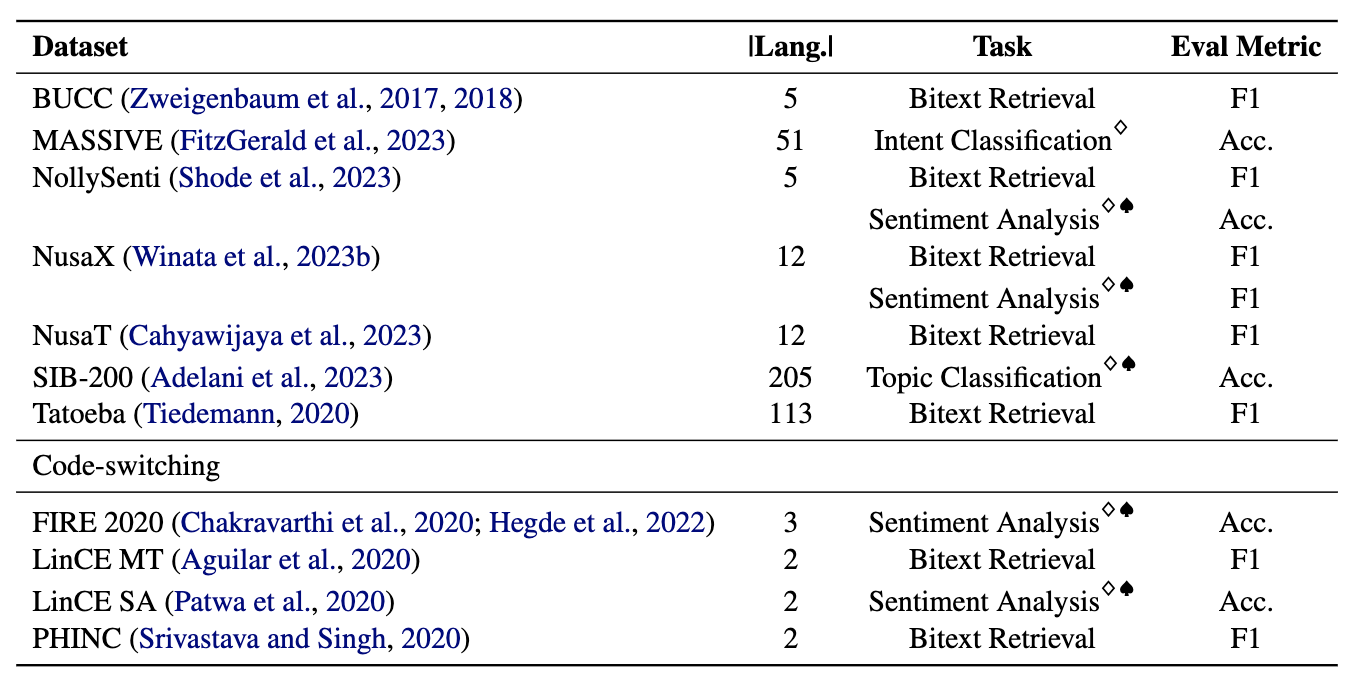
เกณฑ์มาตรฐานของเราประเมิน LMS ในสามงาน: Bitext Retrieval, การจำแนกตามการดึงข้อมูลและการจำแนกประเภท ICL การตั้งค่ารวมถึง monolingual (mono) , cross-lingual (XS) , การสลับรหัส (CS) และ การสลับรหัสข้ามภาษา (XS CS)
pip install -r requirements.txt
หากคุณต้องการใช้ API หรือรุ่นจาก Openai, Cohere หรือ Hugging Face แก้ไข OPENAI_TOKEN , COHERE_TOKEN และ HF_TOKEN โปรดทราบว่าแบบจำลองส่วนใหญ่เกี่ยวกับการกอดใบหน้าไม่จำเป็นต้องใช้ HF_TOKEN ซึ่งมีไว้สำหรับรุ่น Llama และ Gemma โดยเฉพาะ
หากคุณต้องการใช้ LLAMA3.1 คุณต้องอัพเกรดเวอร์ชัน Transformers
pip install transformers==4.44.2
หากคุณต้องการได้รับผลลัพธ์ทั้งหมดและตัวอย่างจากการทดลองของเราอย่าลังเลที่จะดาวน์โหลดที่นี่ (~ 360MB)
ผลการทดลองทั้งหมดจะถูกเก็บไว้ใน logs/ ไดเรกทอรี คุณสามารถดำเนินการทดสอบแต่ละครั้งโดยใช้คำสั่งต่อไปนี้:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
อาร์กิวเมนต์มีความคล้ายคลึงกันข้างต้นยกเว้นเราใช้ --model_checkpoints และ --weights
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
เพิ่ม --src_lang และ --cross ไปยังคำสั่ง
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
อาร์กิวเมนต์มีความคล้ายคลึงกันข้างต้นยกเว้นเราใช้ --model_checkpoints และ --weights
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
เพิ่ม --src_lang และ --cross ไปยังคำสั่ง
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
เพิ่ม --k เพื่อแก้ไขจำนวนตัวอย่างที่ดึงมา
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
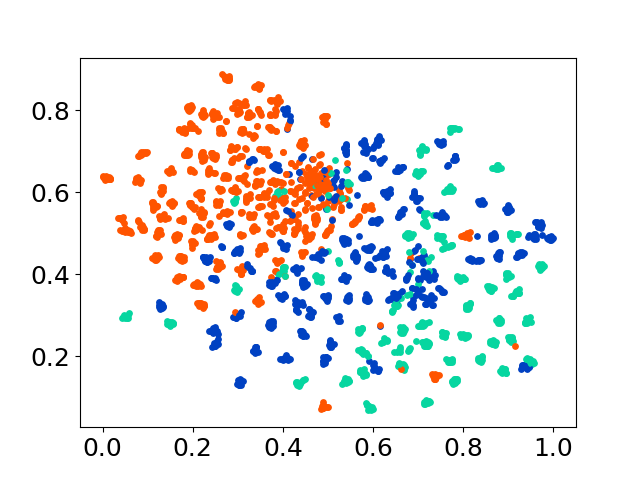
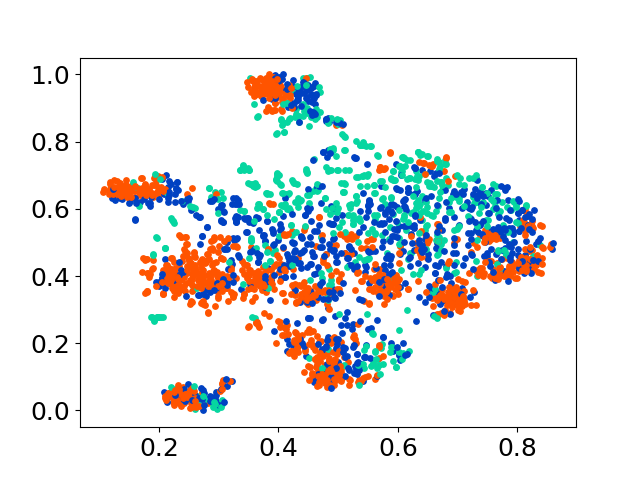
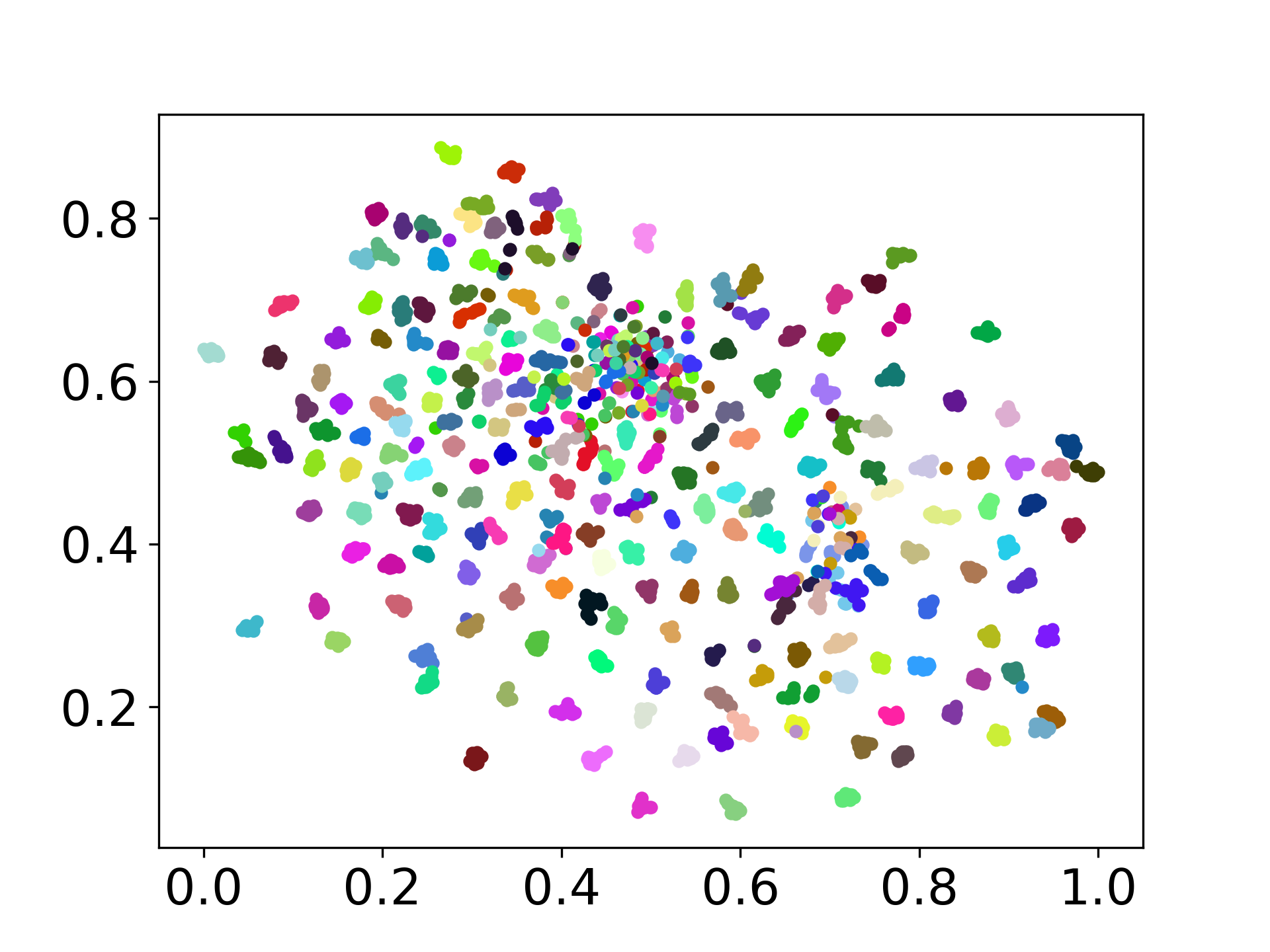
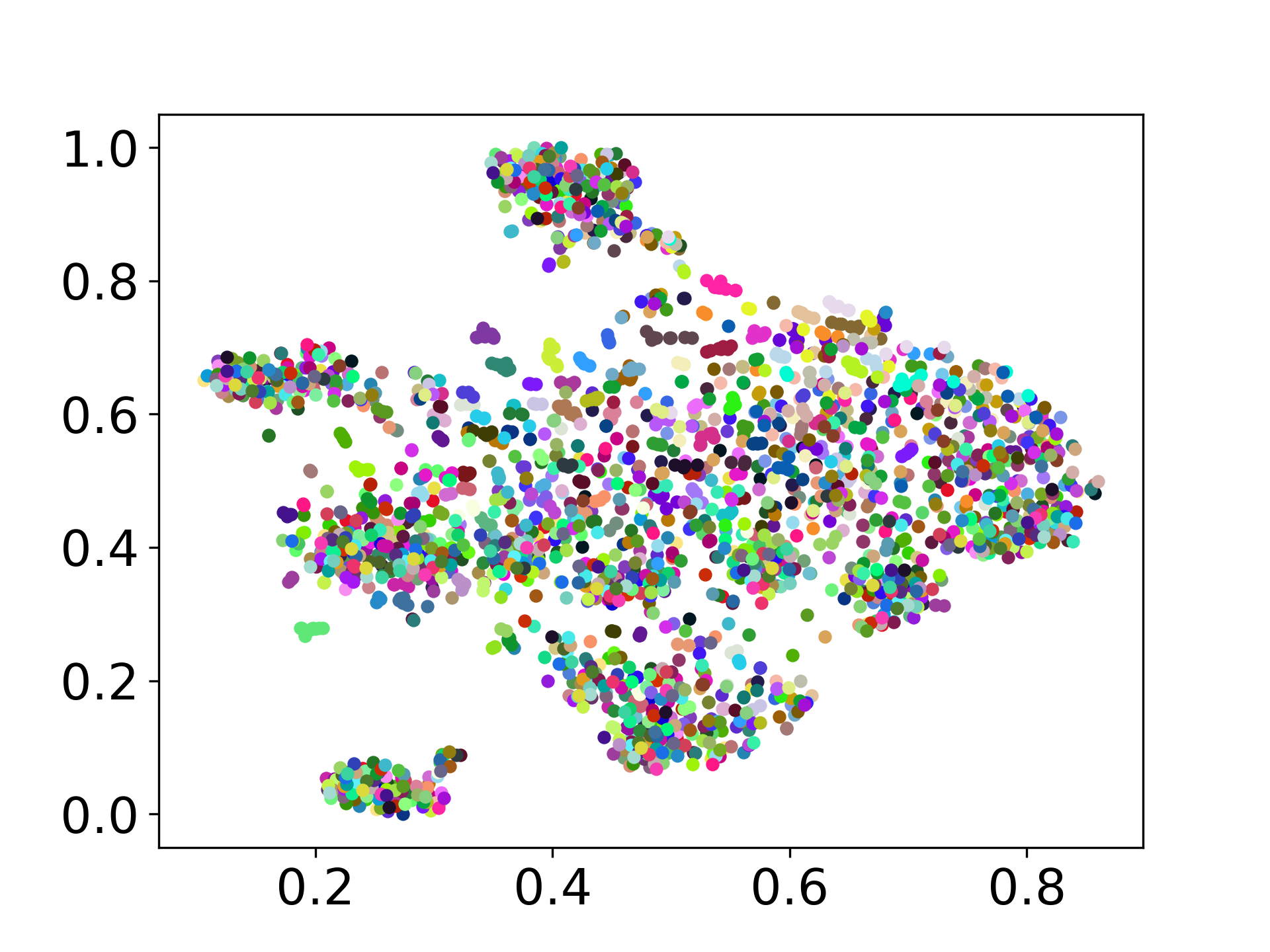
codebase ของเรารองรับการใช้งานหลายรุ่นสำหรับการทดลองให้ความยืดหยุ่นสำหรับการปรับแต่งนอกเหนือจากรายการที่แสดงด้านล่าง:
อย่าลังเลที่จะสร้างปัญหาหากคุณมีคำถามใด ๆ และสร้าง PR สำหรับการแก้ไขข้อบกพร่องหรือเพิ่มการปรับปรุง (เช่นเพิ่มชุดข้อมูลหรือรุ่นใหม่)
หากคุณสนใจที่จะสร้างส่วนขยายของงานนี้อย่าลังเลที่จะติดต่อเรา!
สนับสนุนความพยายามของเราโอเพนซอร์ส
เรากำลังปรับปรุงรหัสเพื่อให้ง่ายขึ้นและปรับแต่งได้ เราได้สร้างที่เก็บใหม่สำหรับการใช้ Distfuse ซึ่งมีอยู่ที่ https://github.com/gentaiscool/distfuse/ คุณสามารถติดตั้งได้โดยเรียกใช้ pip install distfuse ต่อมามันจะถูกรวมเข้ากับที่เก็บนี้


