miners
1.0.0
 : 의미 론적 리트리버로서 다국어 언어 모델
: 의미 론적 리트리버로서 다국어 언어 모델miners 벤치 마크를 소개합니다. Miners 벤치 마크 소개는 미세 조정없이 검색 된 컨텍스트를 통한 Bitext 마이닝 및 분류를 포함하여 의미 론적 검색 작업에서 다국어 LMS의 능력을 평가하도록 설계되었습니다. 도전적인 교차 언어 (XS) 및 CS (Code-Switching) 설정에서 저주적 언어를 포함하여 200 개가 넘는 다양한 언어 에서 샘플을 검색 할 때 언어 모델의 효과를 평가하기 위해 포괄적 인 프레임 워크가 개발되었습니다. 결과는 미세 조정없이 의미 적으로 유사한 임베딩 만 검색하여 최첨단 방법으로 경쟁력있는 성능을 달성 할 수 있음을 보여줍니다.
이 논문은 EMNLP 2024 결과에서 받아 들여졌습니다.
이것은 논문의 소스 코드 [arxiv]입니다.
이 코드는 Pytorch를 사용하여 작성되었습니다. 연구 에서이 툴킷의 코드 나 데이터 세트를 사용하는 경우 관련 논문을 인용하십시오.
@article {winata2024miners,
Title = {광부 : 의미 론적 리트리버로서 다국어 언어 모델},
저자 = {Winata, Genta Indra 및 Zhang, Ruochen 및 Adelani, David Ifeoluwa},
저널 = {arxiv preprint arxiv : 2406.07424},
연도 = {2024}
}
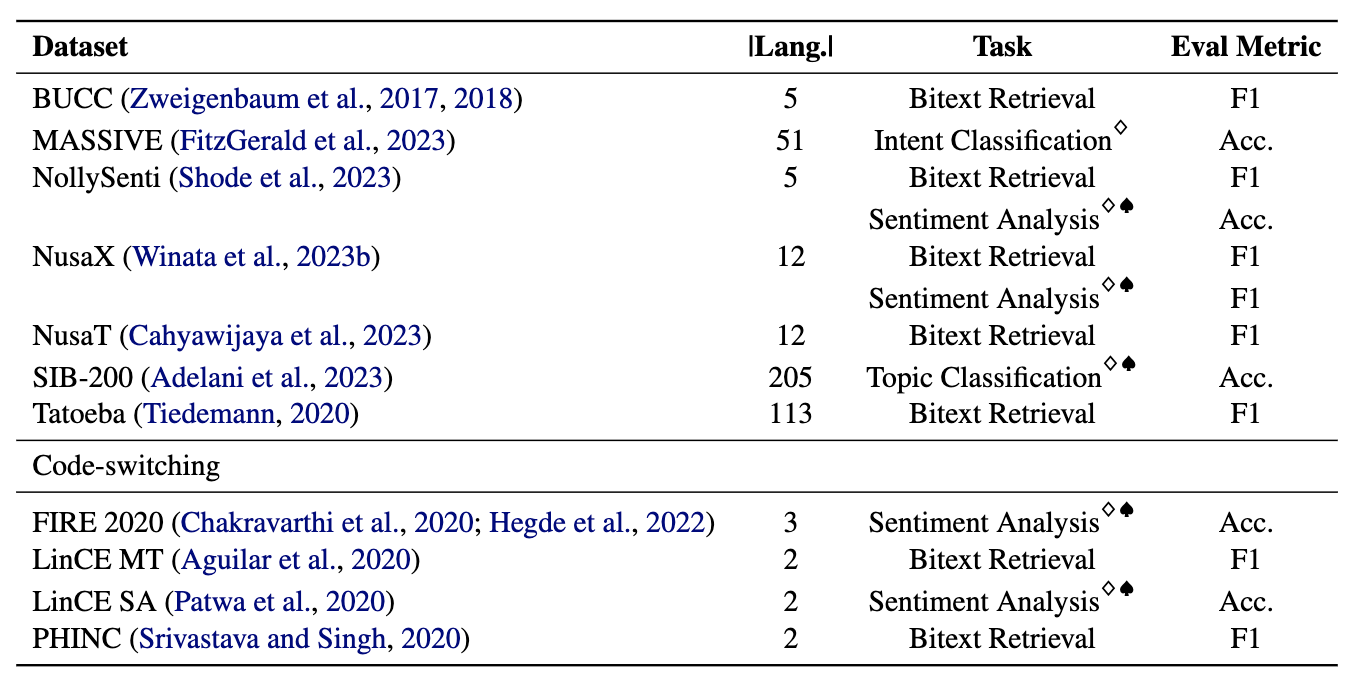
광부는 11 개의 다국어 및 4 개의 코드 전환 데이터 세트, 200 개 이상의 언어를 다루고 병렬 및 분류 형식을 모두 포함하는 11 개의 데이터 세트로 구성됩니다. 병렬 데이터 세트는 정렬 된 다국어 컨텐츠를 포함하여 Bitext 채굴 및 기계 번역 작업을 용이하게하기 때문에 Bitext 검색에 적합합니다. 또한 분류 데이터 세트는 검색 기반 및 ICL 분류 할당을 평가하는 의도 분류, 감정 분석 및 주제 분류를 다룹니다.
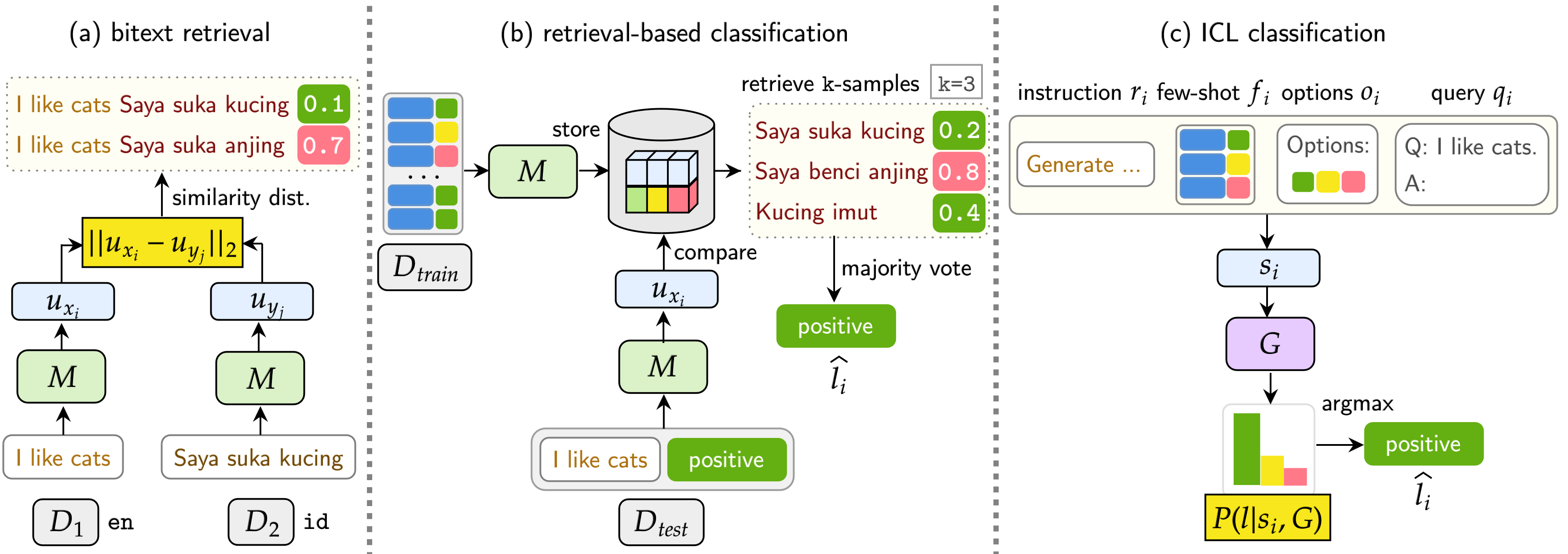
우리의 벤치 마크는 BITEXT 검색, 검색 기반 분류 및 ICL 분류의 세 가지 작업에서 LMS를 평가합니다. 설정에는 단일 언어 (모노) , 교차 언어 (XS) , 코드 스위치 (CS) 및 교차 코드 스위치 (XS CS)가 포함됩니다.
pip install -r requirements.txt
Openai, Cohere 또는 Hugging Face의 API 또는 모델을 사용하려면 OPENAI_TOKEN , COHERE_TOKEN 및 HF_TOKEN 수정하십시오. 포옹 페이스의 대부분의 모델에는 LLAMA 및 GEMMA 모델을위한 HF_TOKEN 필요하지 않습니다.
llama3.1을 사용하려면 Transformers 버전을 업그레이드해야합니다.
pip install transformers==4.44.2
실험에서 모든 결과와 신속한 예를 얻으려면 여기에서 자유롭게 다운로드하십시오 (~ 360MB).
모든 실험 결과는 logs/ 디렉토리에 저장됩니다. 다음 명령을 사용하여 각 실험을 실행할 수 있습니다.
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
인수는 우리가 사용하는 --model_checkpoints 제외하고는 위와 유사합니다 --weights
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
--src_lang 추가하고 --cross 명령에 추가하십시오.
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
인수는 우리가 사용하는 --model_checkpoints 제외하고는 위와 유사합니다 --weights
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
--src_lang 추가하고 --cross 명령에 추가하십시오.
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
검색 된 샘플의 수를 수정하려면 --k 추가하십시오.
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
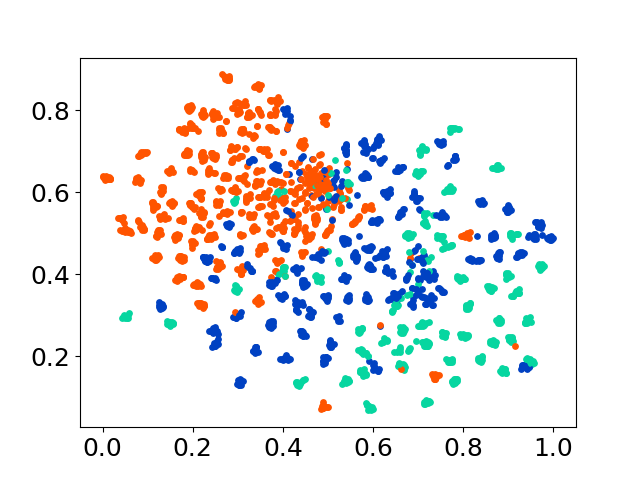
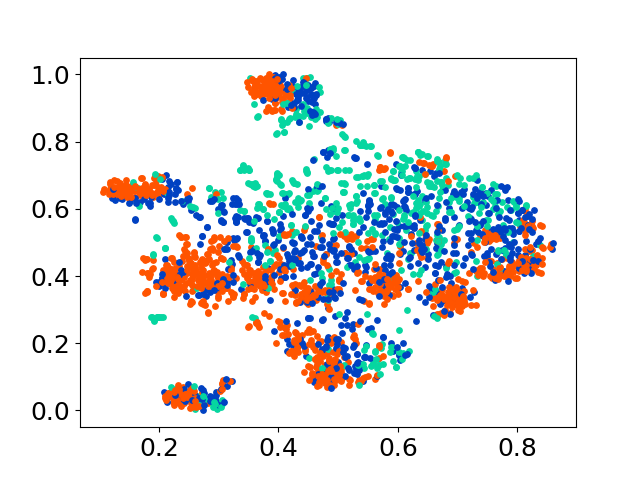
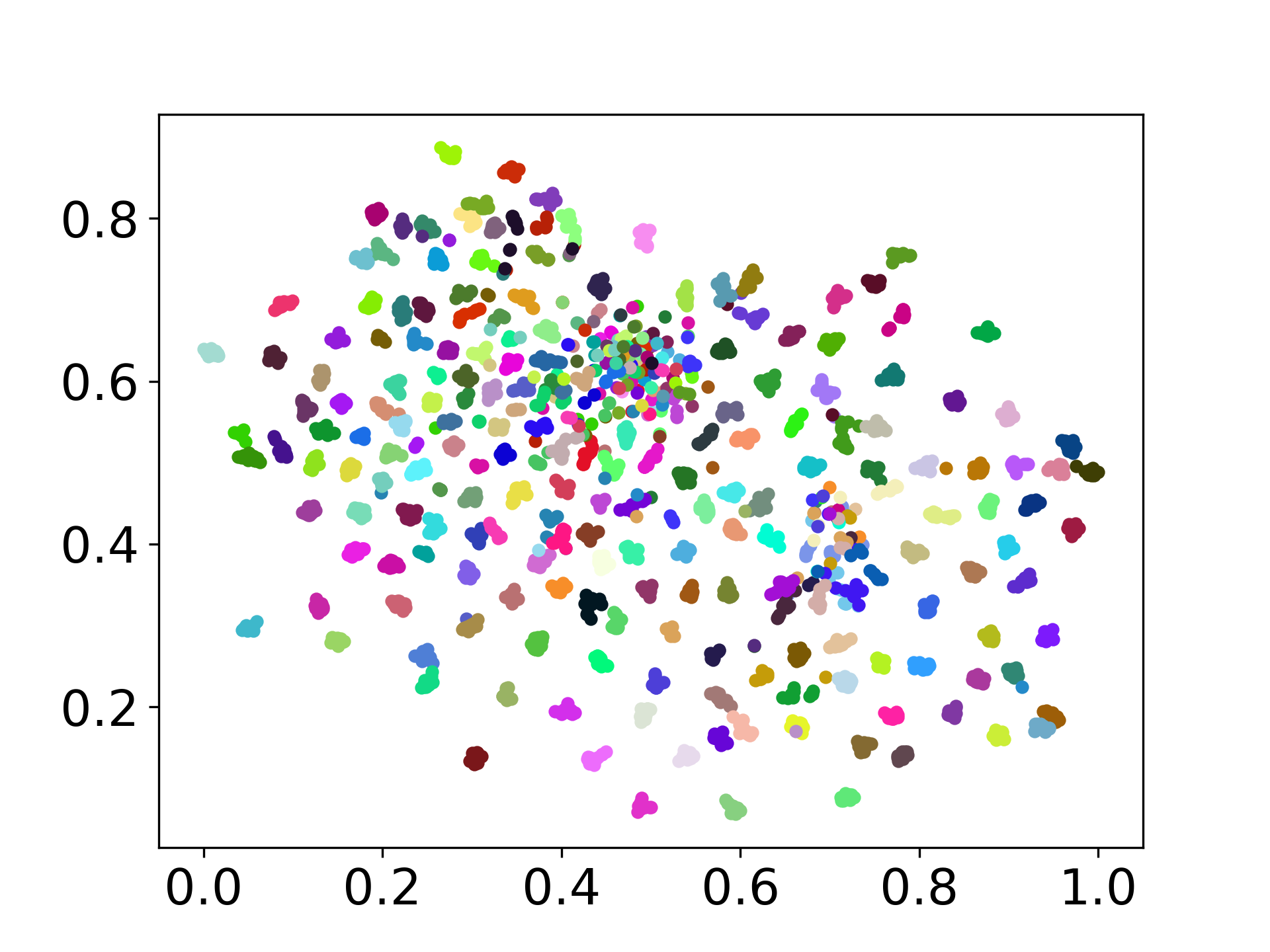
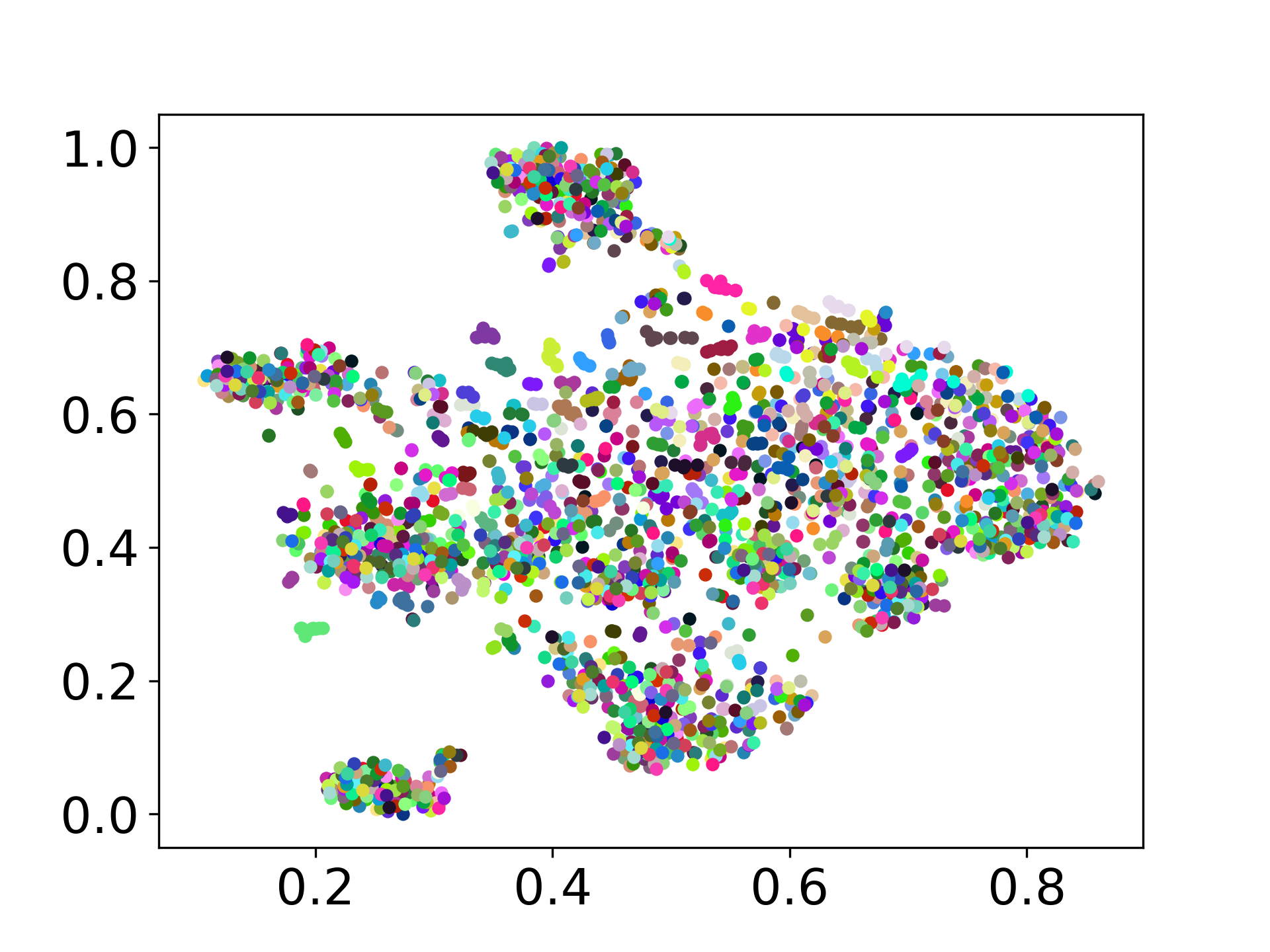
당사의 코드베이스는 실험에 대한 여러 모델의 사용을 지원하여 아래 표시된 목록 이상으로 사용자 정의를위한 유연성을 제공합니다.
궁금한 점이 있으시면 문제를 해결하십시오. 버그 수정 또는 개선 사항 추가 (예 : 새로운 데이터 세트 또는 모델 추가)를위한 PR을 만듭니다.
이 작품의 확장을 만들고 싶다면 언제든지 우리에게 연락하십시오!
우리의 오픈 소스 노력을 지원하십시오
보다 사용자 친화적이고 사용자 정의 할 수 있도록 코드를 개선하고 있습니다. https://github.com/gentaiscool/distfuse/에서 사용할 수있는 Distfuse 구현을위한 새로운 저장소를 만들었습니다. pip install distfuse 실행하여 설치할 수 있습니다. 나중에이 저장소에 통합됩니다.


