miners
1.0.0
 : Mehrsprachige Sprachmodelle als semantische Retriever
: Mehrsprachige Sprachmodelle als semantische Retriever⚡ Einführung des Benchmarks von Miners , die zur Beurteilung der mehrsprachigen LMS-Fähigkeiten bei semantischen Abrufaufgaben, einschließlich Bitext-Mining und Klassifizierung, durch retrieval-ausgelöste Kontexte ohne Feinabstimmung bewertet werden. Es wurde ein umfassender Rahmen entwickelt, um die Wirksamkeit von Sprachmodellen beim Abrufen von Stichproben in über 200 verschiedenen Sprachen zu bewerten, einschließlich Sprachen mit niedrigem Ressourcen in herausfordernden intersprachigen (XS) und Code-Switching-Einstellungen (CS-Switching) . Die Ergebnisse zeigen, dass das Erreichen der Wettbewerbsleistung mit modernsten Methoden möglich ist, indem nur semantisch ähnliche Einbettungen abgerufen werden, ohne dass eine Feinabstimmung erforderlich ist.
Das Papier wurde bei den Ergebnissen der EMNLP 2024 akzeptiert.
Dies ist der Quellcode des Papiers [Arxiv]:
Dieser Code wurde mit Pytorch geschrieben. Wenn Sie Code oder Datensätze aus diesem Toolkit in Ihrer Forschung verwenden, geben Sie bitte das zugehörige Papier an.
@Article {Winata2024Miners,
Titel = {Bergarbeiter: Mehrsprachige Sprachmodelle als semantische Retriever},
Autor = {Winata, Genta Indra und Zhang, Ruoche und Adelani, David Ifeoluwa},
Journal = {Arxiv Preprint Arxiv: 2406.07424},
Jahr = {2024}
}
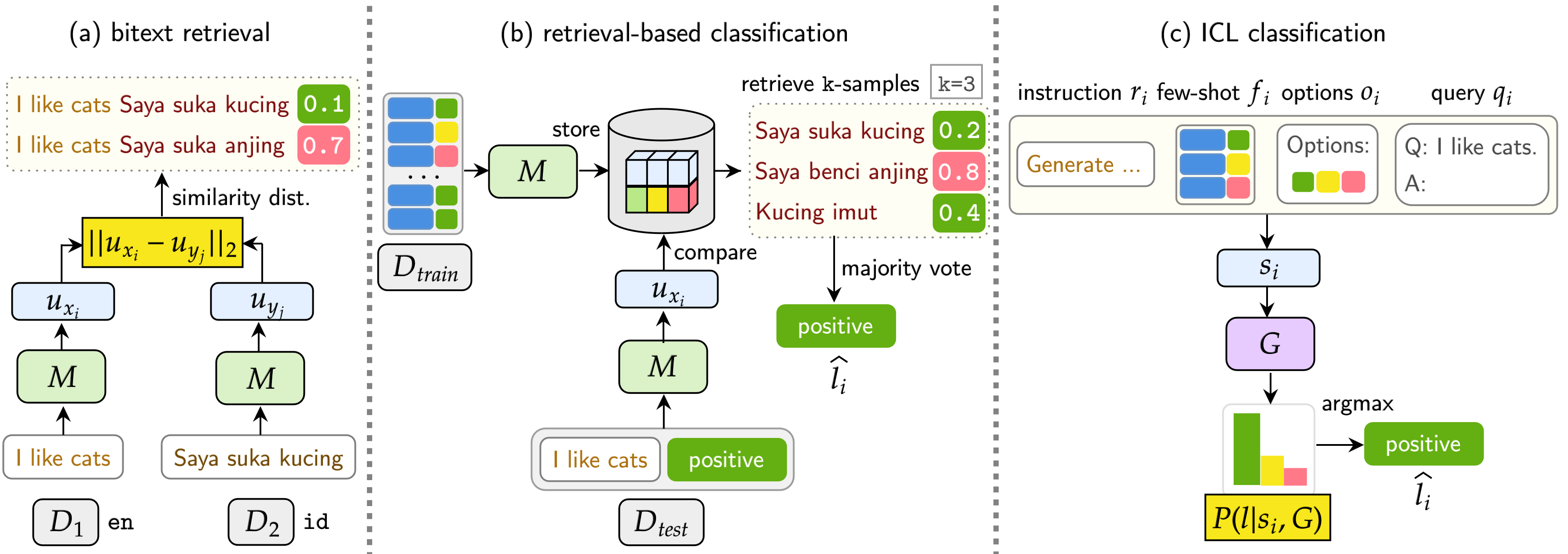
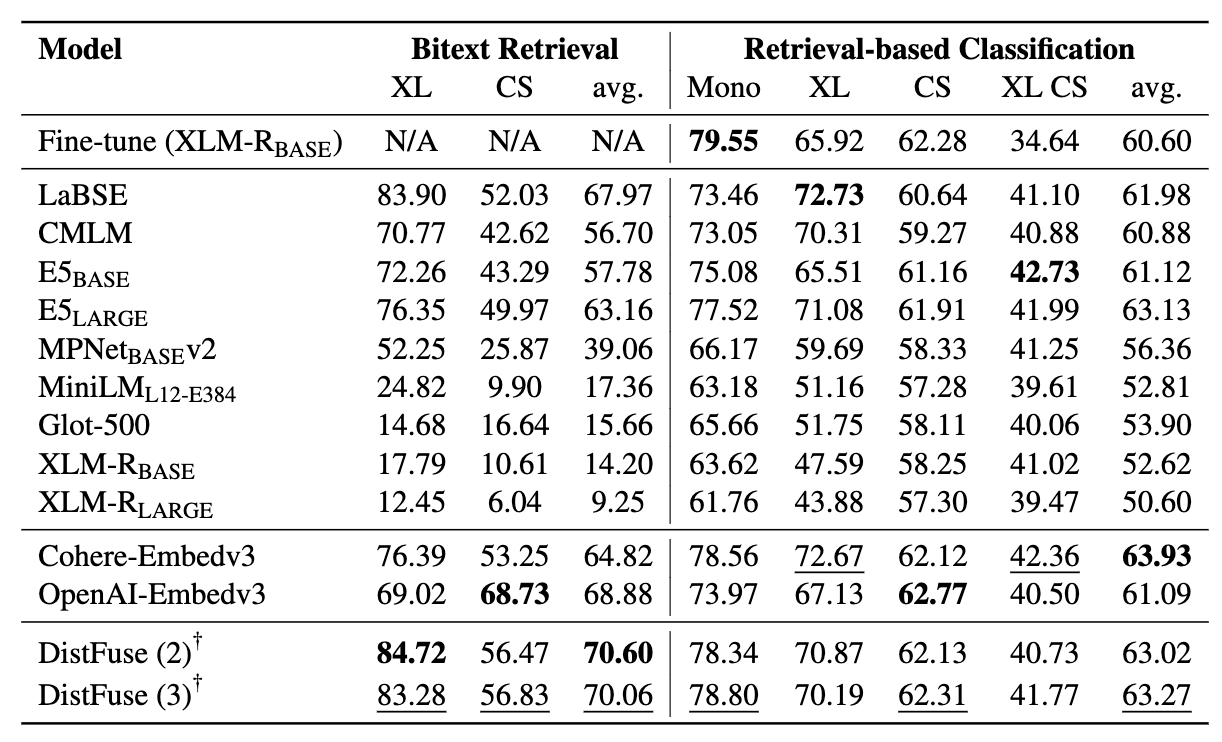
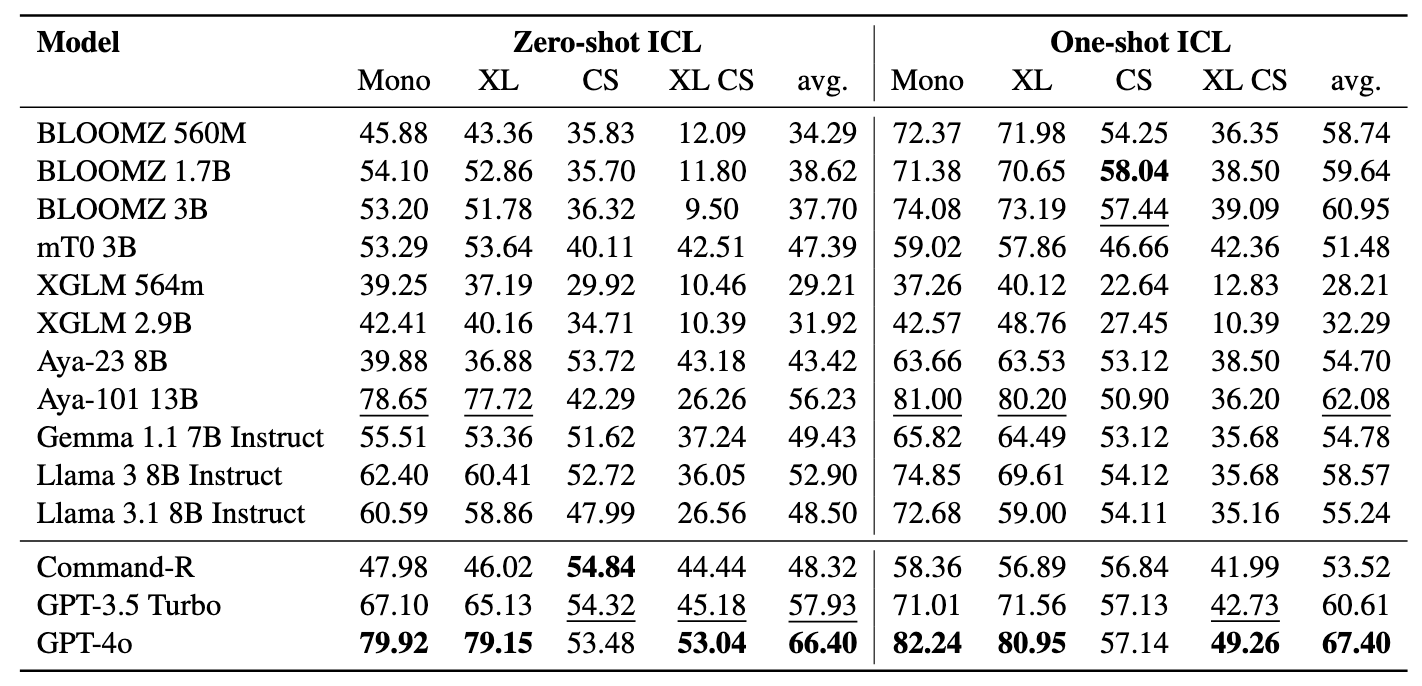
Die Bergleute umfassen 11 Datensätze: 7 mehrsprachige und 4 Code-Switching-Datensätze, die mehr als 200 Sprachen abdecken und sowohl parallele als auch klassifizierende Formate umfassen. Parallele Datensätze eignen sich für das Abruf von Bitext, da sie ausgerichtete mehrsprachige Inhalte enthalten und Bitext -Mining und maschinelle Übersetzungsaufgaben erleichtern. Darüber hinaus decken die Klassifizierungsdatensätze die Absichtserklärung, die Stimmungsanalyse und die Themenklassifizierung ab, die wir für das Abrufen- und ICL-Klassifizierungszuweisungen bewerten.
Unser Benchmark bewertet LMS an drei Aufgaben: Bitext-Abruf, Abrufbasis-Klassifizierung und ICL-Klassifizierung. Die Einstellungen umfassen einsprachige (mono) , intersprachige (XS) , Code-Switching (CS) und Kreuzungs-Lingual-Code-Witching (XS CS) .
pip install -r requirements.txt
Wenn Sie die APIs oder Modelle von OpenAI, Cohere oder Umarmung verwenden möchten, ändern Sie die OPENAI_TOKEN , COHERE_TOKEN und HF_TOKEN . Beachten Sie, dass die meisten Modelle auf dem Umarmungsgesicht nicht das HF_TOKEN erfordern, was speziell für die Lama- und Gemma -Modelle bestimmt ist.
Wenn Sie Lama3.1 verwenden möchten, müssen Sie die Transformers -Version aktualisieren
pip install transformers==4.44.2
Wenn Sie alle Ergebnisse und schnellen Beispiele aus unseren Experimenten erhalten möchten, können Sie sie hier (~ 360 MB) herunterladen.
Alle Experimentergebnisse werden in den logs/ Verzeichnissen gespeichert. Sie können jedes Experiment mit den folgenden Befehlen ausführen:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Die Argumente sind ähnlich wie oben, außer dass wir --model_checkpoints und --weights verwenden
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Fügen Sie --src_lang und --cross zum Befehl hinzu.
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Die Argumente sind ähnlich wie oben, außer dass wir --model_checkpoints und --weights verwenden
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Fügen Sie --src_lang und --cross zum Befehl hinzu.
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Hinzufügen --k , um die Anzahl der abgerufenen Proben zu ändern.
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
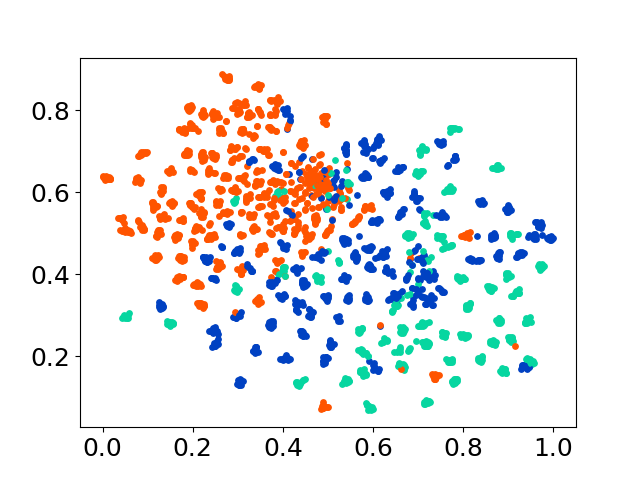
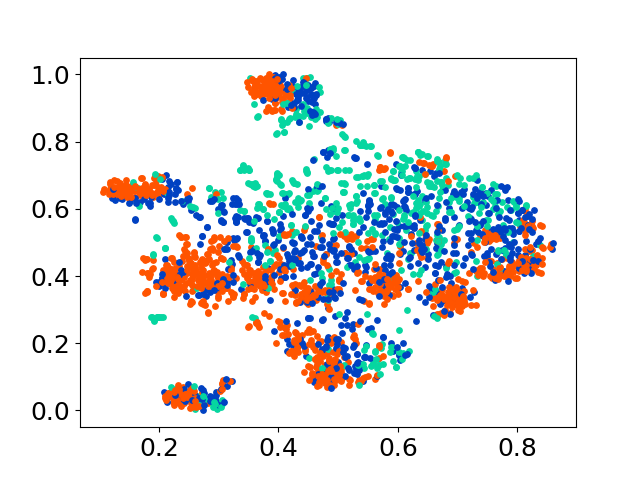
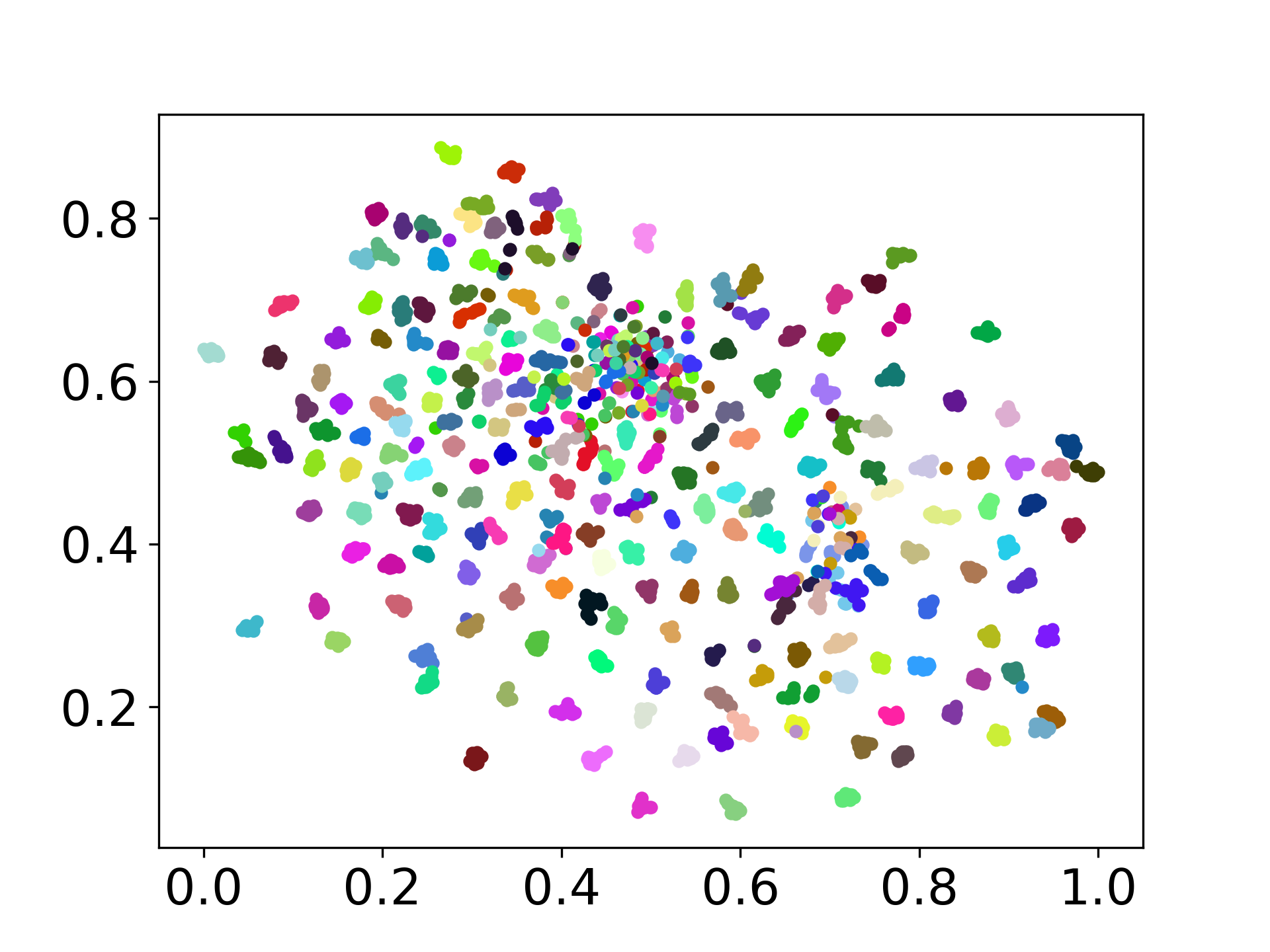
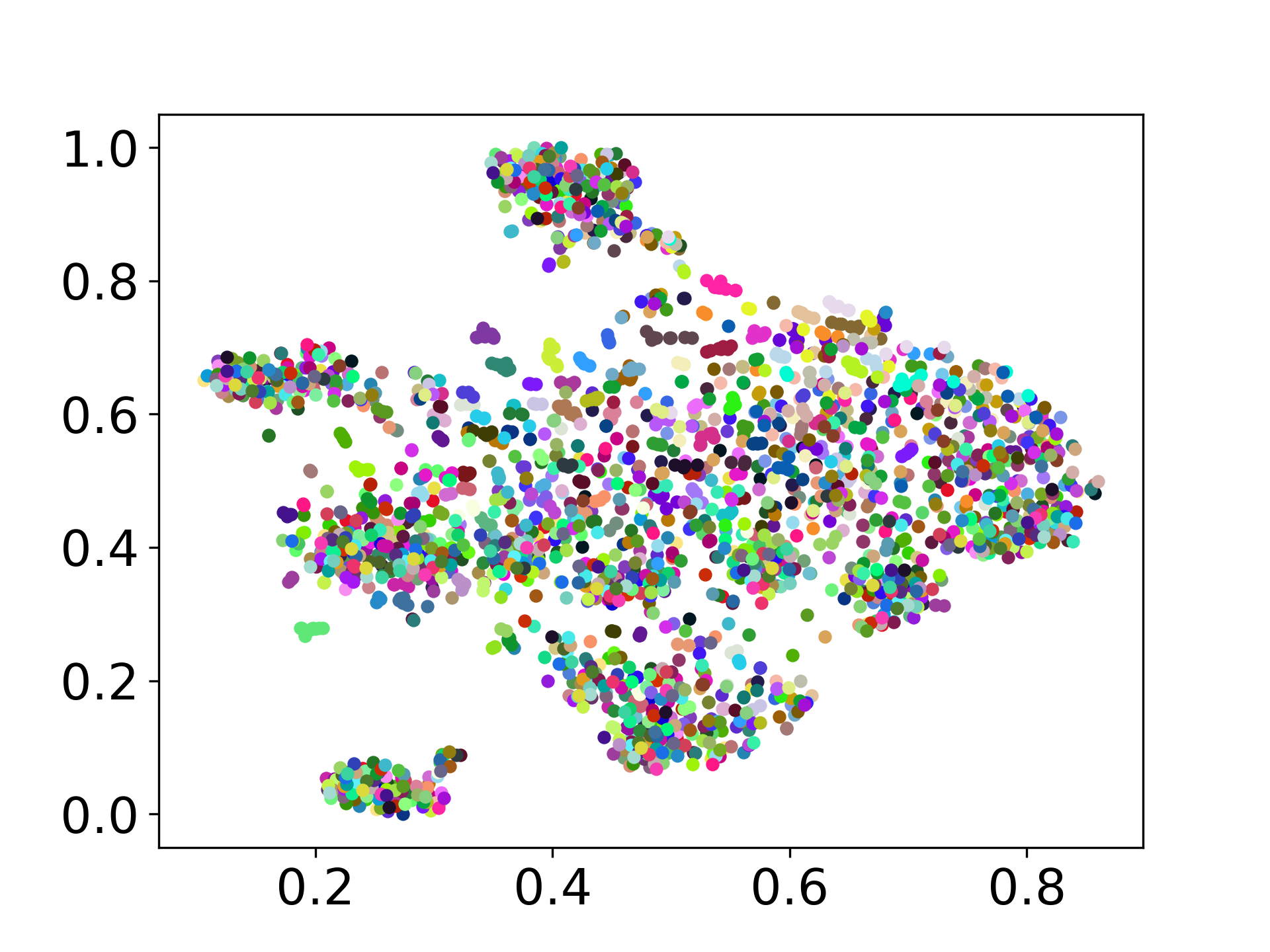
Unsere Codebasis unterstützt die Verwendung mehrerer Modelle für die Experimente und bietet Flexibilität für die Anpassung über die unten gezeigte Liste hinaus:
Fühlen Sie sich frei, ein Problem zu erstellen, wenn Sie Fragen haben. Erstellen Sie eine PR, um Fehler zu beheben oder Verbesserungen hinzuzufügen (dh Hinzufügen neuer Datensätze oder Modelle).
Wenn Sie daran interessiert sind, eine Erweiterung dieser Arbeit zu erstellen, können Sie sich gerne an uns wenden!
Unterstützen Sie unsere Open Source -Anstrengung
Wir verbessern den Code, um benutzerfreundlicher und anpassbarer zu gestalten. Wir haben ein neues Repository für die Implementierung von Distfuse erstellt, das unter https://github.com/gentaiscool/distfuse/ verfügbar ist. Sie können es installieren, indem Sie pip install distfuse ausführen. Später wird es in dieses Repository integriert.


