miners
1.0.0
 : Многоязычные языковые модели как семантические ретриверы
: Многоязычные языковые модели как семантические ретриверы⚡ Представление эталона шахтеров , предназначенное для оценки многоязычного мастерства LMS в семантических задачах поиска, включая добычу и классификацию Bitext с помощью контекстов, связанных с поиском, без точной настройки . Была разработана комплексная структура для оценки эффективности языковых моделей при извлечении образцов на более чем 200 различных языках , включая языки с низким ресурсом в сложных настройках кросс-лингальных (XS) и переключения кода (CS) . Результаты показывают, что достижение конкурентоспособности с помощью современных методов возможна исключительно из получения семантически схожих встраиваний, не требуя точной настройки.
Документ был принят на выводах EMNLP 2024.
Это исходный код статьи [arxiv]:
Этот код был написан с использованием Pytorch. Если вы используете какой -либо код или наборы данных из этого инструментария в своем исследовании, пожалуйста, укажите связанную статью.
@Article {winata2024miners,
title = {Miners: многоязычные языковые модели как семантические ретриверы},
Автор = {Winata, Genta Indra и Zhang, Ruochen и Adelani, David Ifeoluwa},
Journal = {arxiv Preprint arxiv: 2406.07424},
Год = {2024}
}
Шахтеры состоит из 11 наборов данных: 7 многоязычных и 4 наборов данных по переключению кодов, охватывающих более 200 языков и охватывают как параллельные, так и форматы классификации. Параллельные наборы данных подходят для поиска Bitext, так как они содержат выровненный многоязычный контент, способствуя задачам добычи Bitext и машинного перевода. Кроме того, наборы данных классификации охватывают классификацию намерений, анализ настроений и классификацию тем, которые мы оцениваем для получения заданий на основе поиска и ICL.
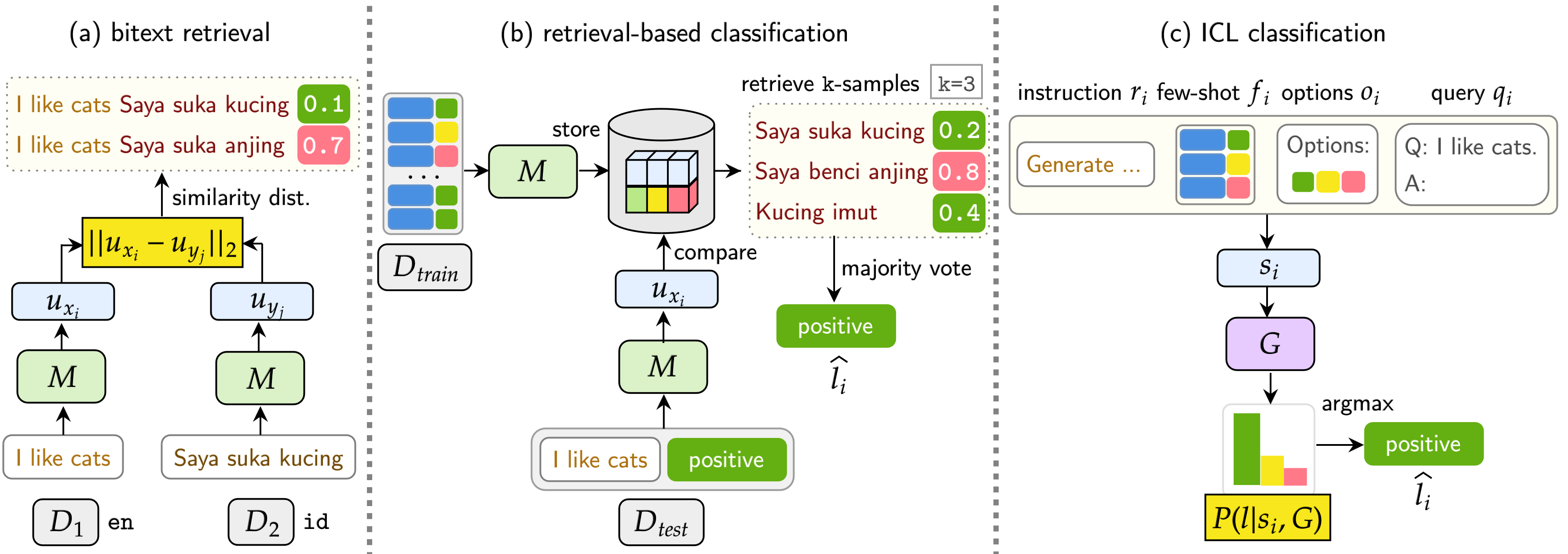
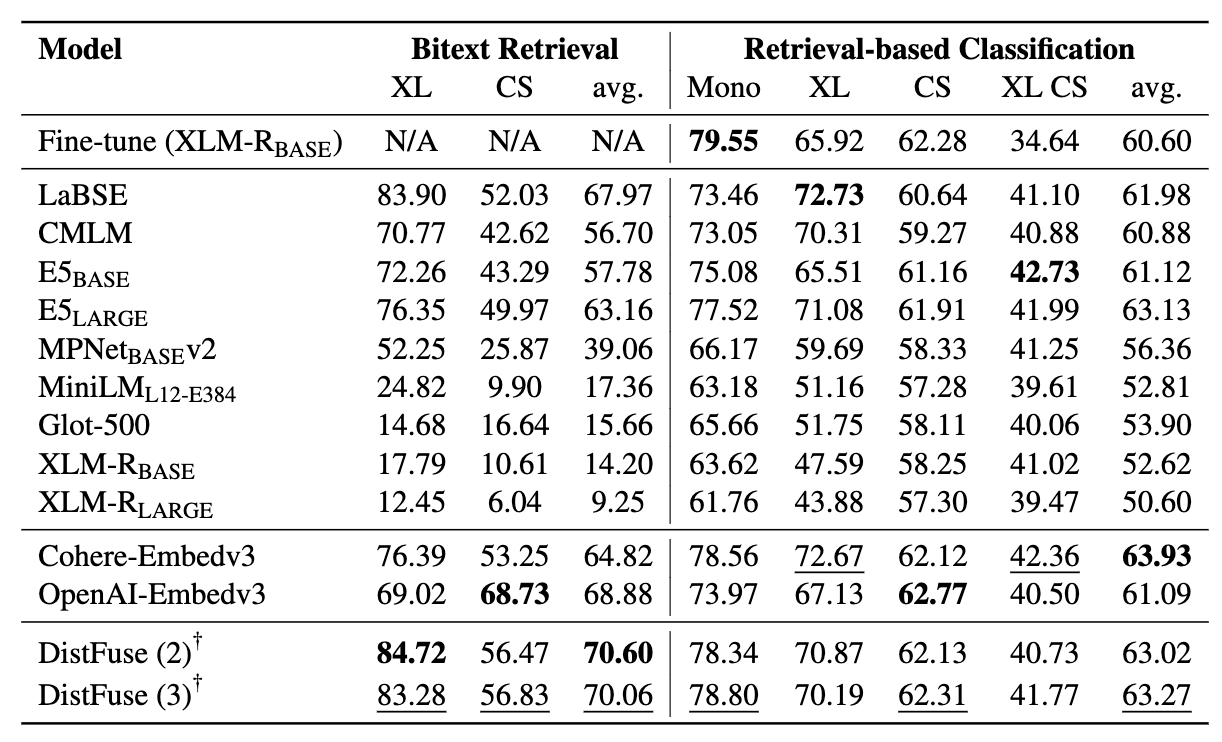
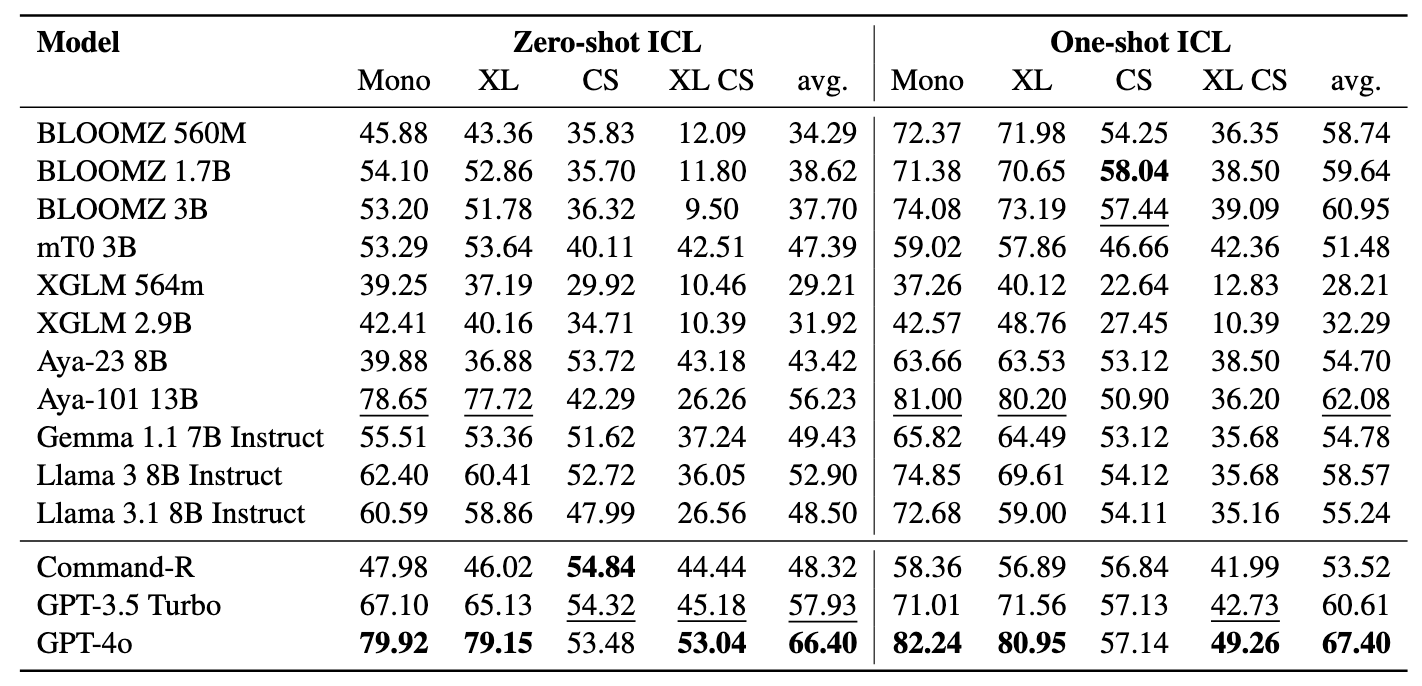
Наш эталон оценивает LMS по трем задачам: поиск Bitext, классификация на основе поиска и классификация ICL. Настройки включают монолингвальный (моно) , кросс-лингальные (xs) , переключение кода (CS) и переключение кода по межсочевым переключениям (XS CS) .
pip install -r requirements.txt
Если вы хотите использовать API или модели от OpenAI, Cohere или обнимающегося лица, измените OPENAI_TOKEN , COHERE_TOKEN и HF_TOKEN . Обратите внимание, что большинство моделей об обнимающееся лицо не требуют HF_TOKEN , который специально предназначен для моделей ламы и геммы.
Если вы хотите использовать Llama3.1, вам нужно обновить версию Transformers
pip install transformers==4.44.2
Если вы хотите получить все результаты и приведенные примеры из наших экспериментов, не стесняйтесь загружать их здесь (~ 360 МБ).
Все результаты эксперимента будут храниться в logs/ каталоге. Вы можете выполнить каждый эксперимент, используя следующие команды:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Аргументы похожи, как указано выше, за исключением того, что мы используем --model_checkpoints и --weights
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Добавить --src_lang и --cross в команду.
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Аргументы похожи, как указано выше, за исключением того, что мы используем --model_checkpoints и --weights
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Добавить --src_lang и --cross в команду.
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Добавить --k , чтобы изменить количество полученных образцов.
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
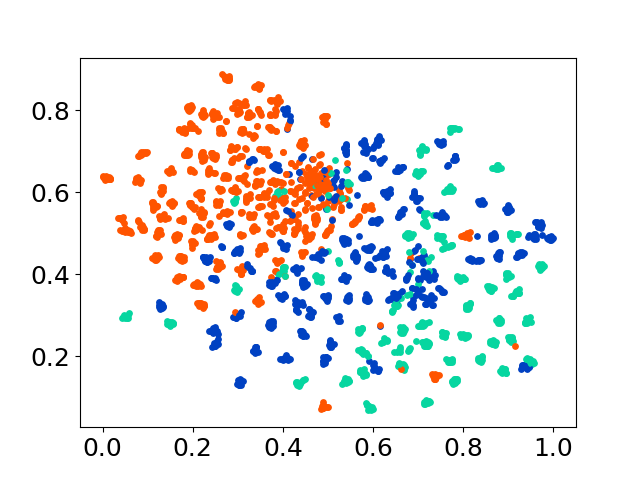
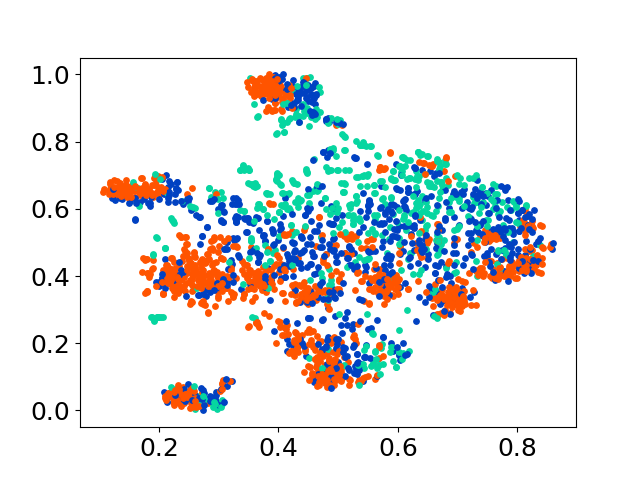
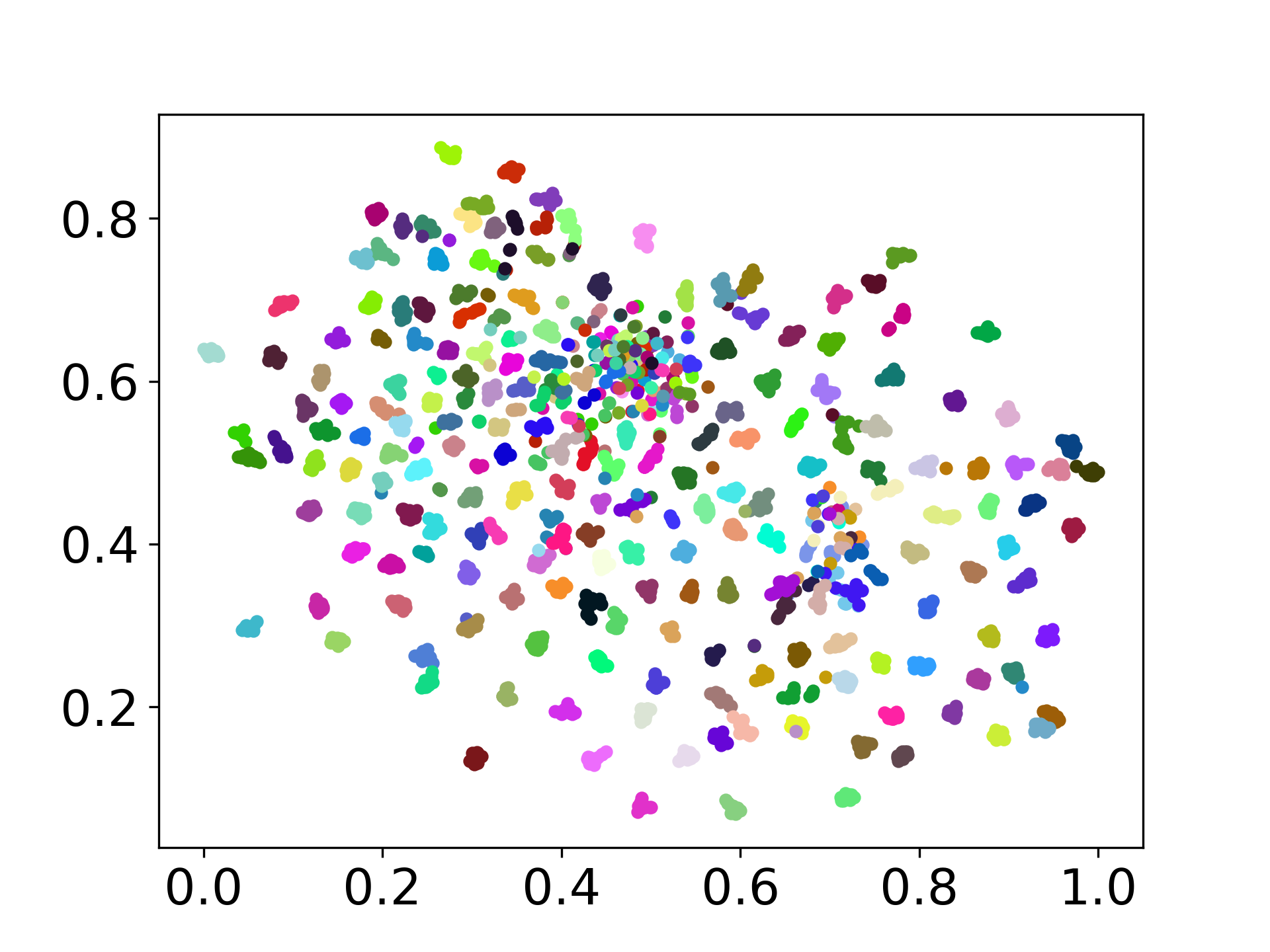
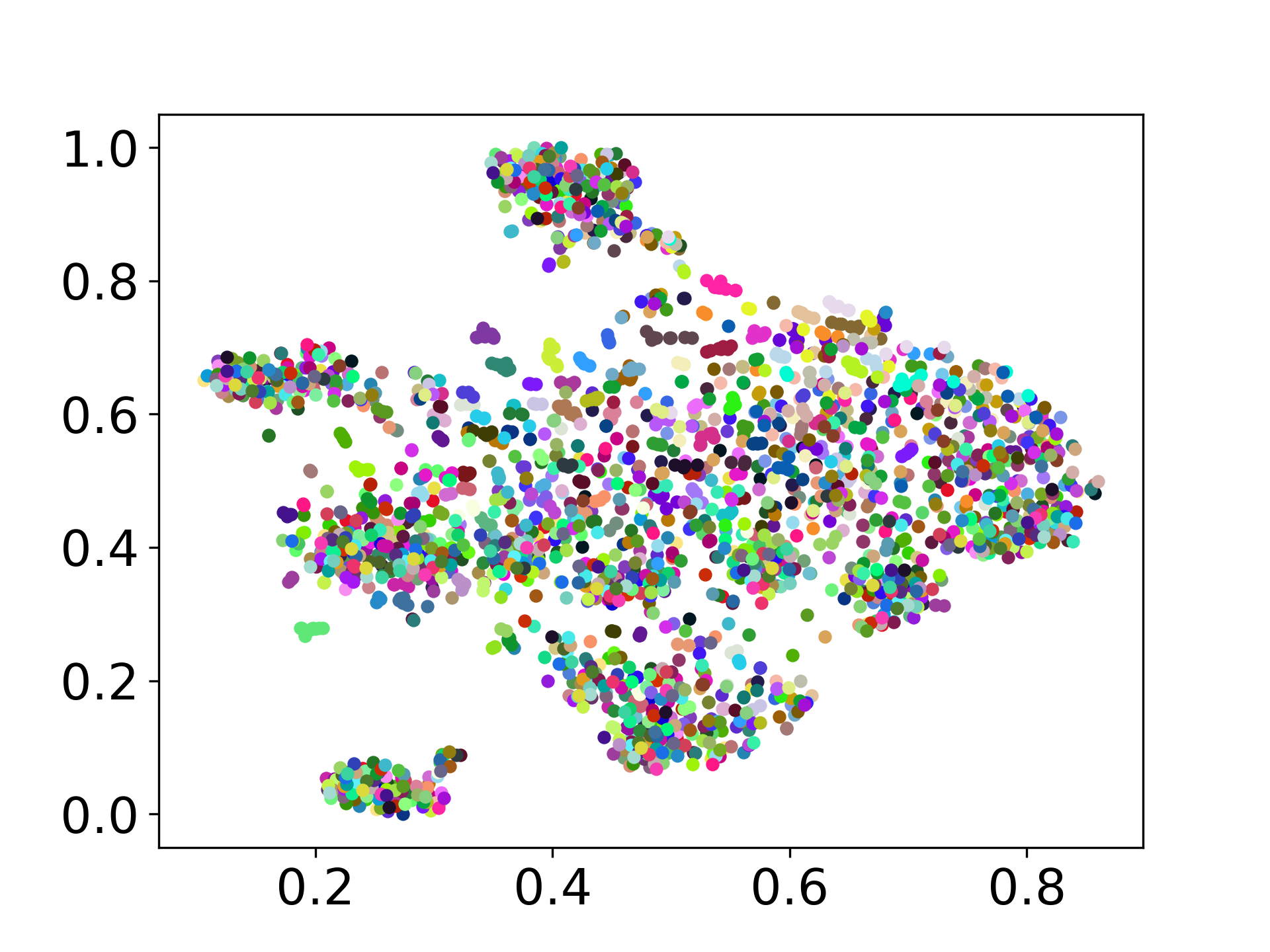
Наша кодовая база поддерживает использование нескольких моделей для экспериментов, обеспечивая гибкость для настройки за пределами списка, показанного ниже:
Не стесняйтесь создавать проблему, если у вас есть какие -либо вопросы. И создайте PR для исправления ошибок или добавления улучшений (то есть добавление новых наборов данных или моделей).
Если вы заинтересованы в создании расширения этой работы, не стесняйтесь обратиться к нам!
Поддержите наши усилия с открытым исходным кодом
Мы улучшаем код, чтобы сделать его более удобным и настраиваемым. Мы создали новый репозиторий для внедрения дистанции, который доступен по адресу https://github.com/gentaiscool/distfuse/. Вы можете установить его, запустив pip install distfuse . Позже он будет интегрирован в этот репозиторий.


