miners
1.0.0
 :セマンティックレトリバーとしての多言語モデル
:セマンティックレトリバーとしての多言語モデルnemant微調整なしで検索された高級コンテキストを介したBitextマイニングと分類を含む、セマンティック検索タスクでの多言語LMSの腕前を評価するように設計されたマイナーベンチマークの導入。包括的なフレームワークが開発されました。言語モデルの有効性を評価し、 200を超える多様な言語でサンプルを取得します。これには、挑戦的な横断的(XS)およびコードスイッチング(CS)設定における低リソース言語を含む。結果は、微調整を必要とせずに、意味的に類似した埋め込みのみを取得することで、最先端の方法で競争力のあるパフォーマンスを達成することが可能であることを示しています。
この論文は、EMNLP 2024の調査結果で受け入れられています。
これは、論文のソースコード[arxiv]です。
このコードは、Pytorchを使用して記述されています。調査でこのツールキットのコードまたはデータセットを使用する場合は、関連する論文を引用してください。
@article {winata2024miners、
title = {Miners:Multingual Language Models as Semantic Retrievers}、
著者= {ウィナタ、ゲンタインドラとチャン、ルーチェンとアデラニ、デビッドイフェルワ}、
journal = {arxiv preprint arxiv:2406.07424}、
年= {2024}
}
マイナーは11のデータセットで構成されています。7つの多言語と4つのコードスイッチングデータセットで、 200以上の言語をカバーし、並列および分類形式の両方を網羅しています。並列データセットは、揃った多言語コンテンツが含まれているため、BITEXTの検索に適しており、BITEXTマイニングと機械翻訳タスクを促進します。さらに、分類データセットは、意図の分類、感情分析、トピック分類をカバーし、検索ベースとICL分類の割り当てを評価します。
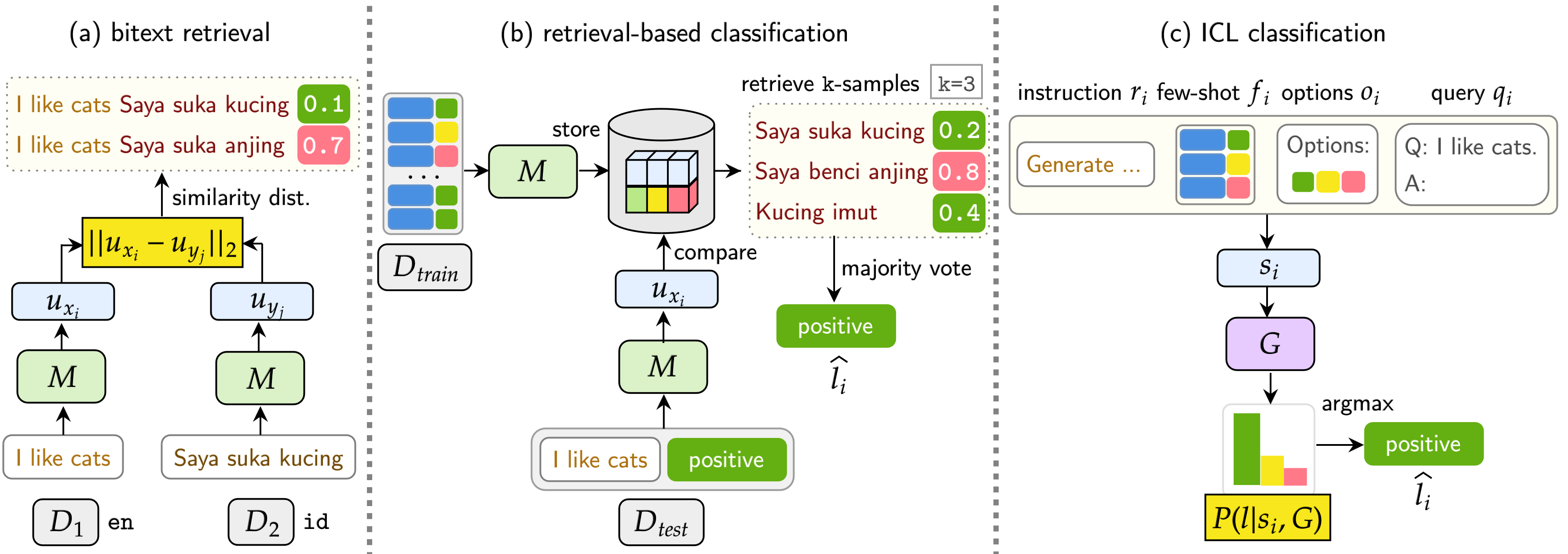
当社のベンチマークは、Bitext検索、検索ベースの分類、ICL分類の3つのタスクでLMSを評価します。設定には、 Monolingual(Mono) 、 Cross-Lingual(XS) 、 Code-Switching(CS) 、およびCross-Lingual Code-Switching(XS CS)が含まれます。
pip install -r requirements.txt
Openai、Cohere、またはHugging FaceのAPIまたはモデルを使用したい場合は、 OPENAI_TOKEN 、 COHERE_TOKEN 、およびHF_TOKENを変更します。抱きしめる顔のほとんどのモデルは、ラマモデルとジェマモデル向けに特に意図されたHF_TOKEN必要としないことに注意してください。
llama3.1を使用する場合は、トランスフォーマーバージョンをアップグレードする必要があります
pip install transformers==4.44.2
実験からすべての結果と迅速な例を取得したい場合は、ここから自由にダウンロードしてください(〜360MB)。
すべての実験結果はlogs/ディレクトリに保存されます。次のコマンドを使用して各実験を実行できます。
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
引数は上記のように似ていますが、 --model_checkpointsと--weightsを使用します
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
--src_langと--crossコマンドにcrossを追加します。
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
引数は上記のように似ていますが、 --model_checkpointsと--weightsを使用します
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
--src_langと--crossコマンドにcrossを追加します。
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
--kを追加して、取得したサンプルの数を変更します。
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
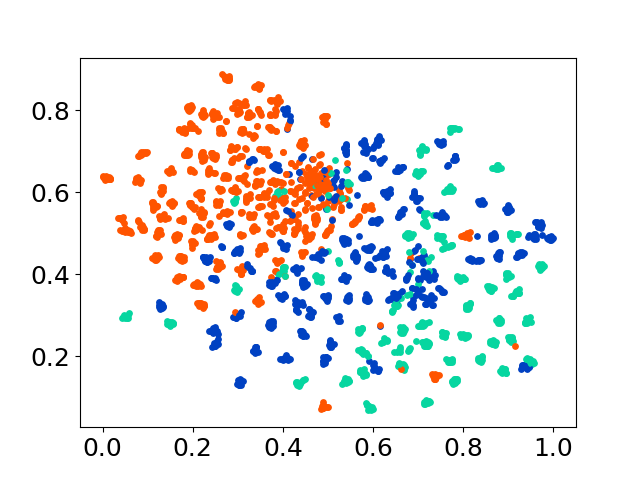
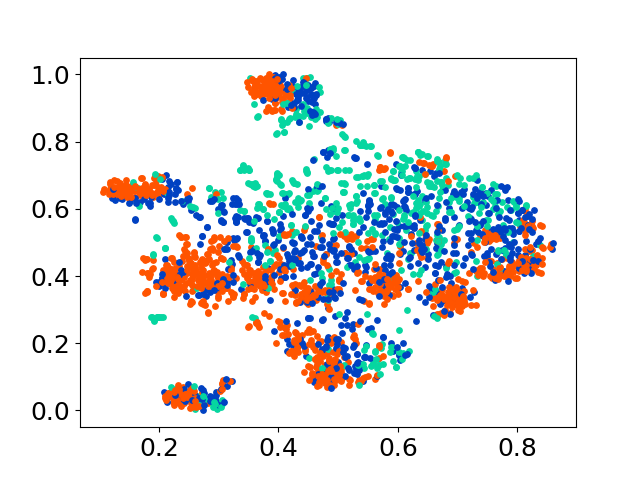
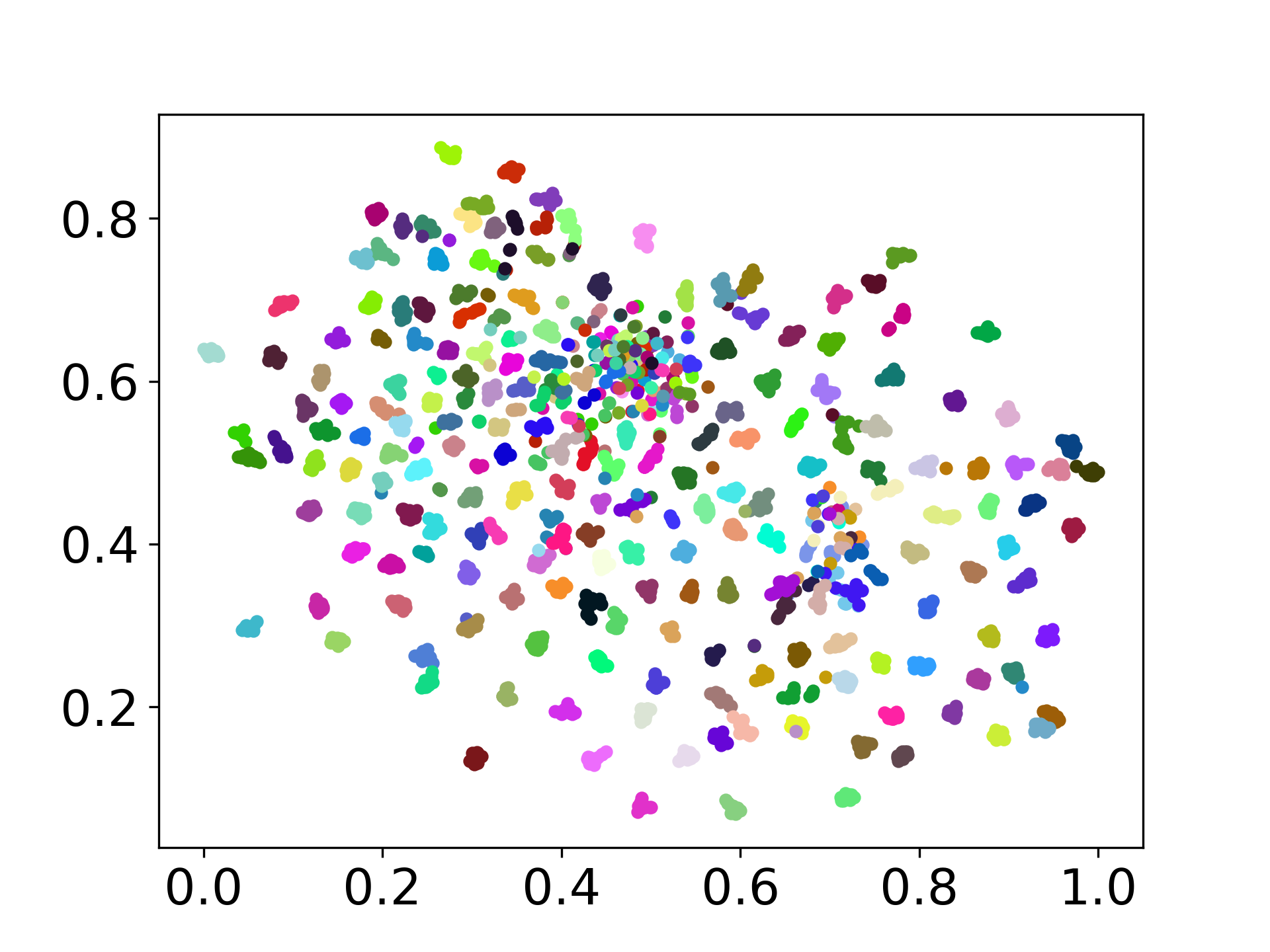
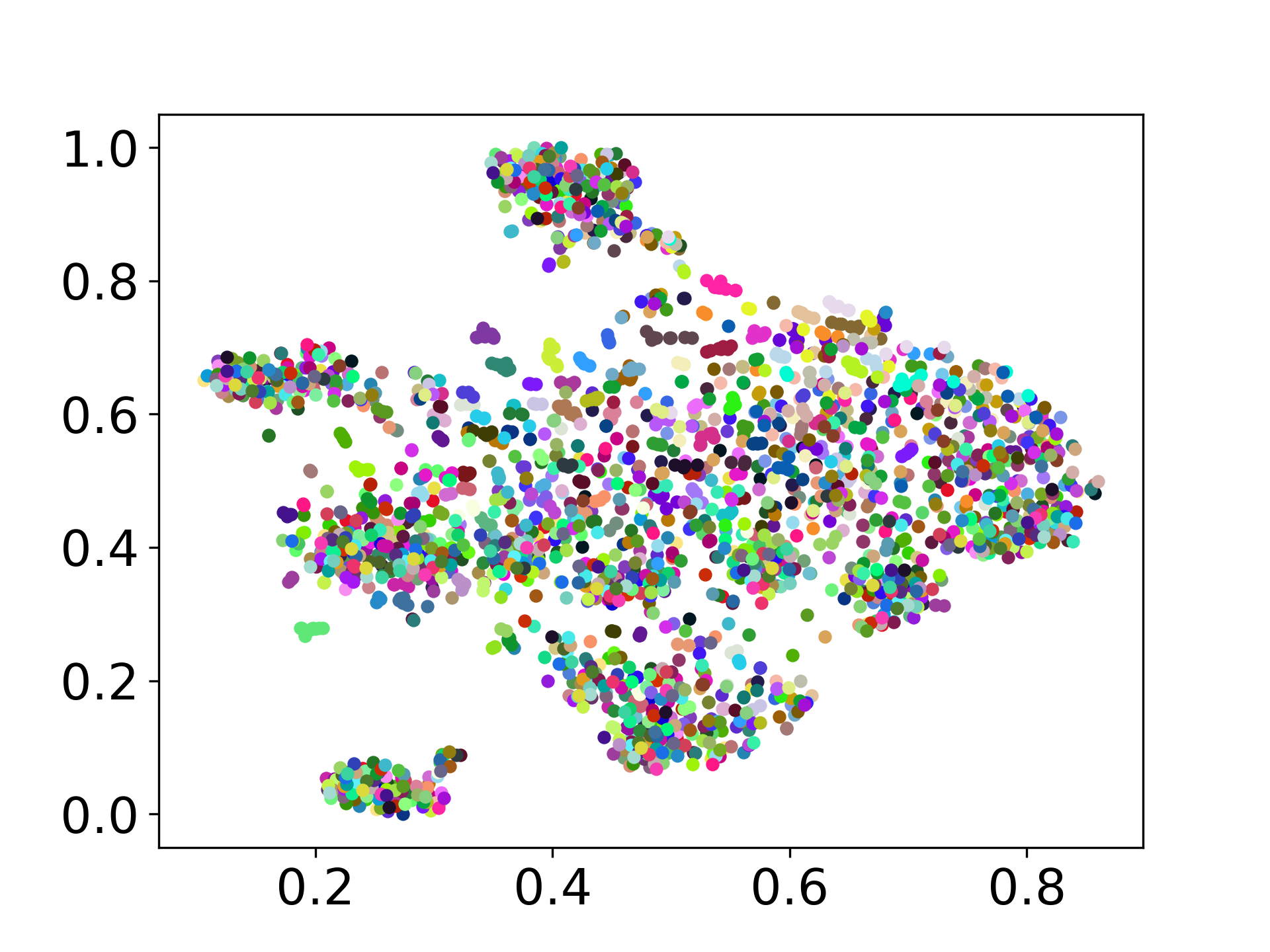
コードベースは、実験のための複数のモデルの使用をサポートしており、以下に示すリストを超えてカスタマイズの柔軟性を提供します。
ご質問がある場合は、お気軽に問題を作成してください。また、バグを修正したり、改善を追加したりするためのPRを作成します(つまり、新しいデータセットまたはモデルの追加)。
この作品の延長を作成することに興味がある場合は、お気軽にご連絡ください!
オープンソースの取り組みをサポートします
コードを改善して、よりユーザーフレンドリーでカスタマイズ可能にしています。 https://github.com/entaiscool/distfuse/で入手できるDistfuseを実装するための新しいリポジトリを作成しました。 pip install distfuseを実行してインストールできます。後で、このリポジトリに統合されます。


