miners
1.0.0
 : Modelos de linguagem multilíngues como retrievers semânticos
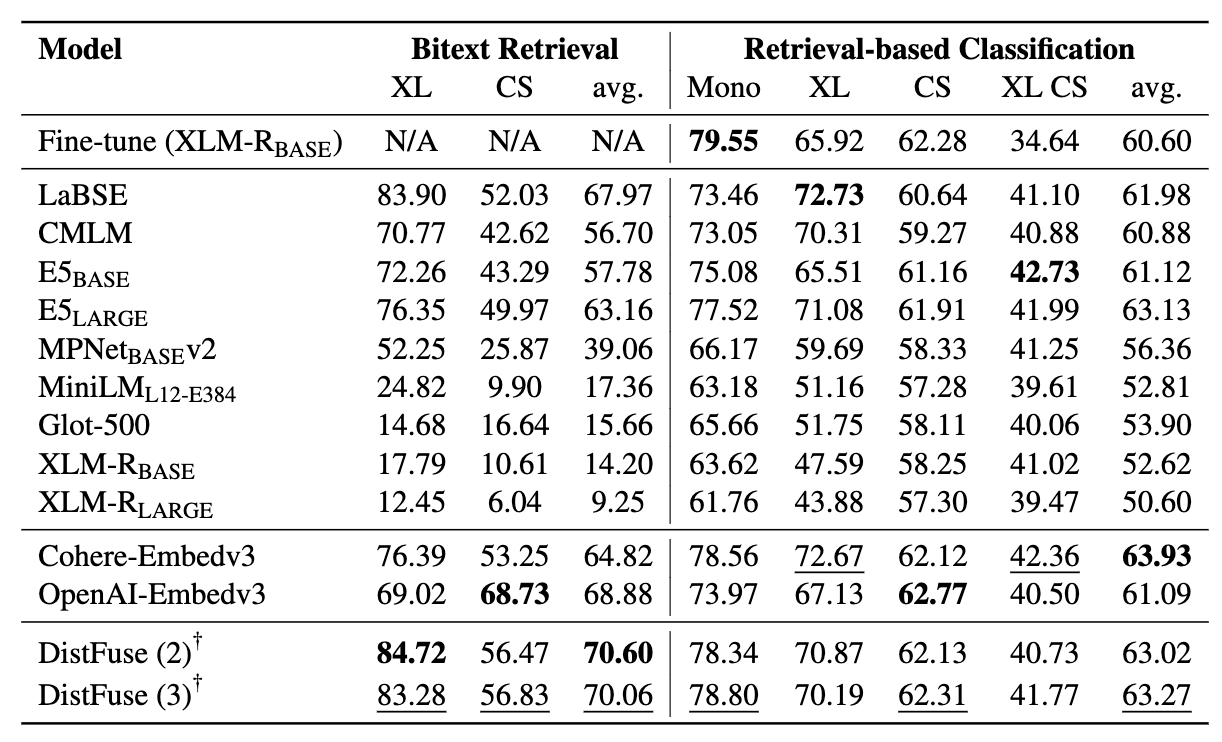
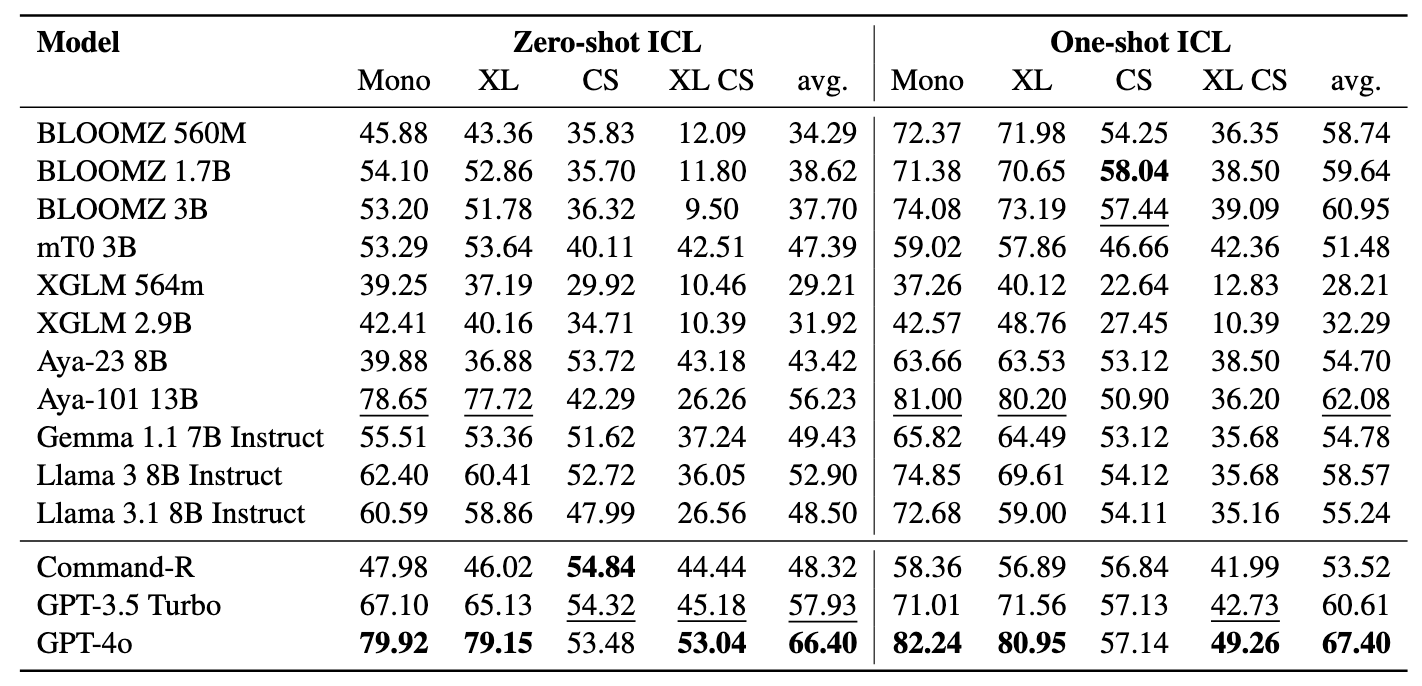
: Modelos de linguagem multilíngues como retrievers semânticos⚡ Apresentando o benchmark Miners , projetado para avaliar as proezas multilíngues do LMS em tarefas de recuperação semântica, incluindo mineração e classificação Bitext por meio de contextos de recuperação com agente de recuperação sem ajuste fino . Uma estrutura abrangente foi desenvolvida para avaliar a eficácia dos modelos de idiomas na recuperação de amostras em mais de 200 idiomas diversos , incluindo idiomas de baixo recurso nas configurações desafiadoras de cruzamento (XS) e troca de código (CS) . Os resultados mostram que alcançar o desempenho competitivo com métodos de última geração é possível recuperando apenas incorporações semanticamente semelhantes, sem exigir nenhum ajuste fino.
O artigo foi aceito nas descobertas do EMNLP 2024.
Este é o código -fonte do artigo [arxiv]:
Este código foi escrito usando Pytorch. Se você usar qualquer código ou conjunto de dados deste kit de ferramentas em sua pesquisa, cite o artigo associado.
@article {winata2024miners,
Title = {Miners: Modelos de linguagem multilíngue como Retrievers semânticos},
autor = {Winata, Genta Indra e Zhang, Ruochen e Adelani, David Ifeoluwa},
Journal = {arxiv pré -impressão arxiv: 2406.07424},
ano = {2024}
}
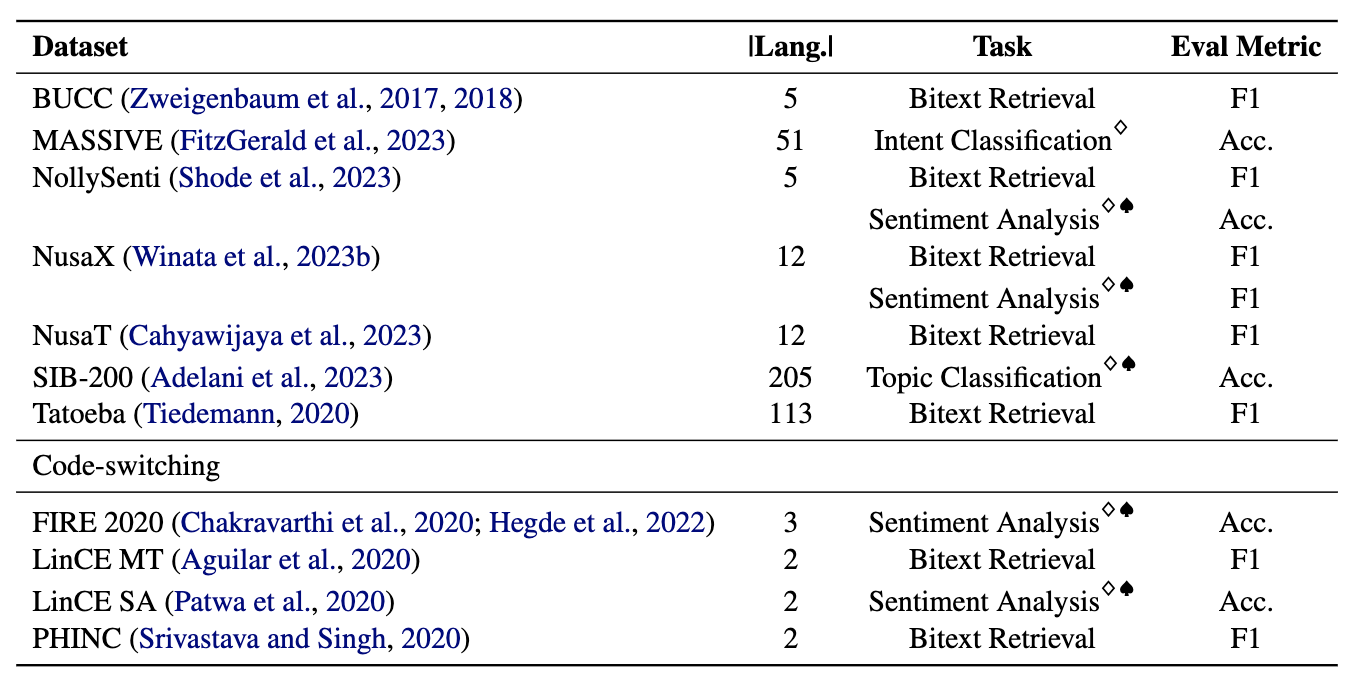
Os mineradores compreendem 11 conjuntos de dados: 7 conjuntos de dados multilíngues e 4 de troca de código, cobrindo mais de 200 idiomas e abrangendo formatos paralelos e de classificação. Os conjuntos de dados paralelos são adequados para a recuperação do Bitext, pois contêm conteúdo multilíngue alinhado, facilitando tarefas de mineração e tradução de máquina. Além disso, os conjuntos de dados de classificação abrangem classificação de intenção, análise de sentimentos e classificação de tópicos, que avaliamos as atribuições de classificação baseadas em recuperação e ICL.
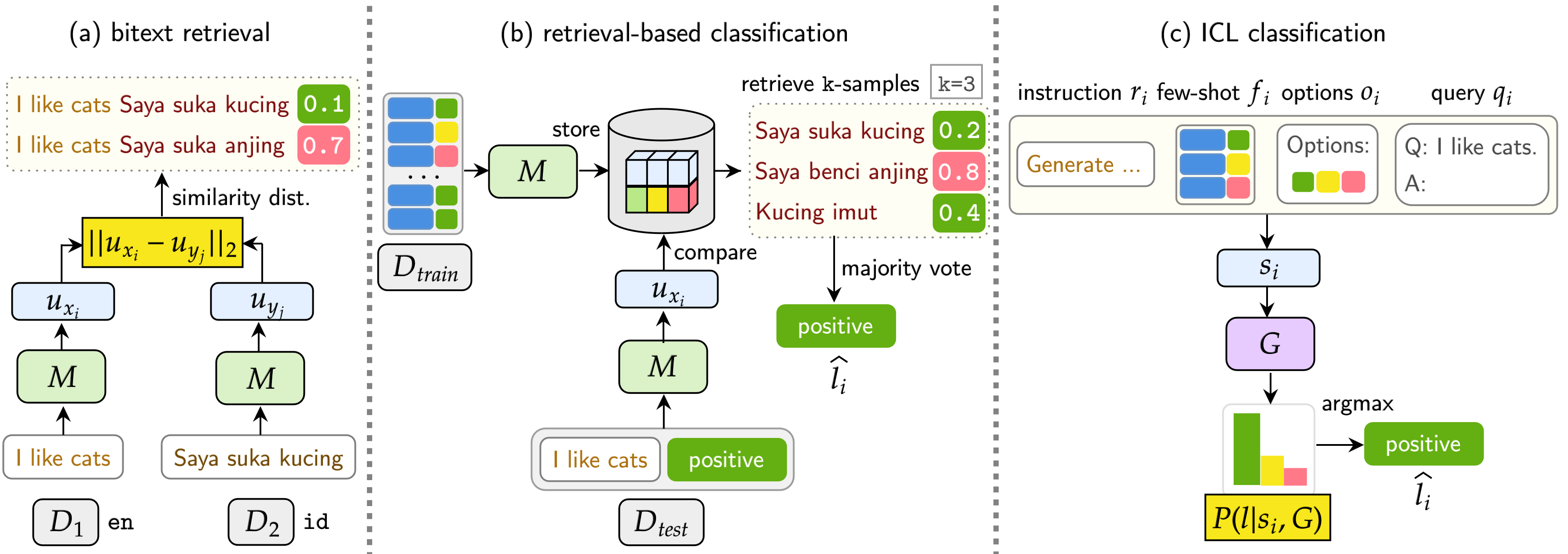
Nosso benchmark avalia o LMS em três tarefas: recuperação da Bitext, classificação baseada em recuperação e classificação da ICL. As configurações incluem monolíngue (mono) , lingual cruzado (XS) , comutação de código (CS) e troca de código cruzada (XS CS) .
pip install -r requirements.txt
Se você deseja utilizar as APIs ou modelos do OpenAI, co -alvo ou abraçar o rosto, modifique o OPENAI_TOKEN , COHERE_TOKEN e HF_TOKEN . Observe que a maioria dos modelos em abraçar o rosto não requer o HF_TOKEN , que é especificamente destinado aos modelos de lhama e gemma.
Se você deseja usar o LLAMA3.1, precisa atualizar a versão Transformers
pip install transformers==4.44.2
Se você deseja obter todos os resultados e provar exemplos de nossos experimentos, fique à vontade para baixá -los aqui (~ 360 MB).
Todos os resultados dos experimentos serão armazenados nos logs/ diretórios. Você pode executar cada experimento usando os seguintes comandos:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Os argumentos são semelhantes aos acima, exceto que usamos --model_checkpoints e --weights
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Adicione --src_lang e --cross ao comando.
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Os argumentos são semelhantes aos acima, exceto que usamos --model_checkpoints e --weights
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Adicione --src_lang e --cross ao comando.
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Adicione --k para modificar o número de amostras recuperadas.
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
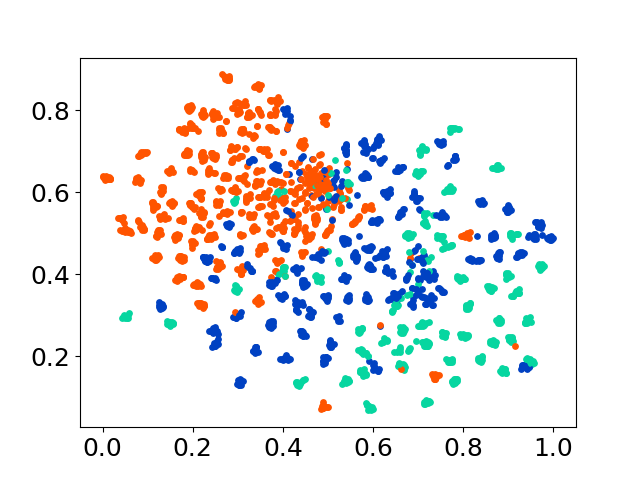
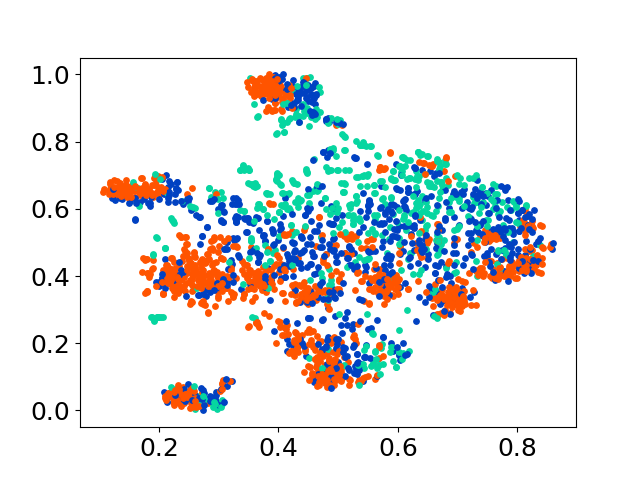
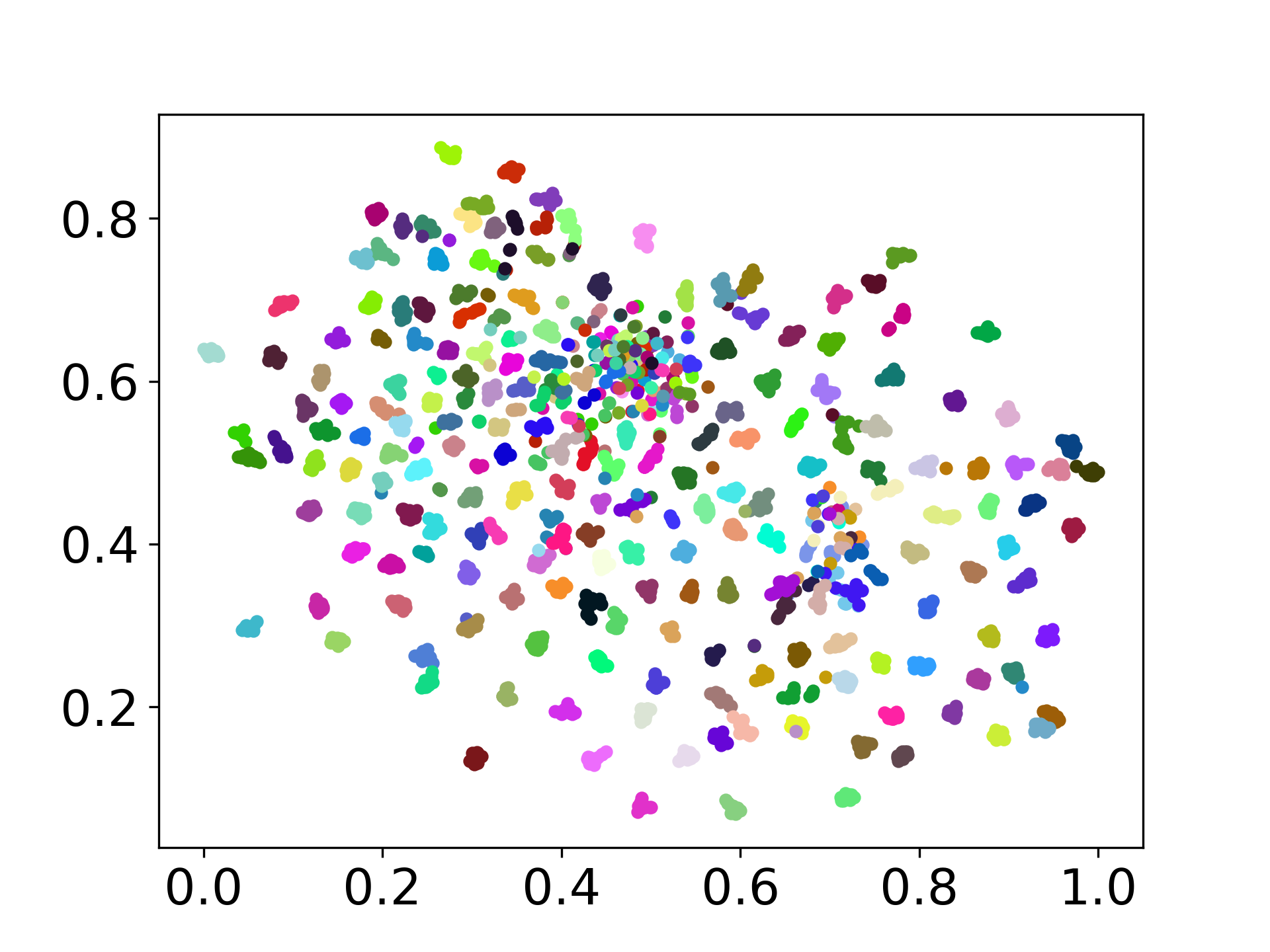
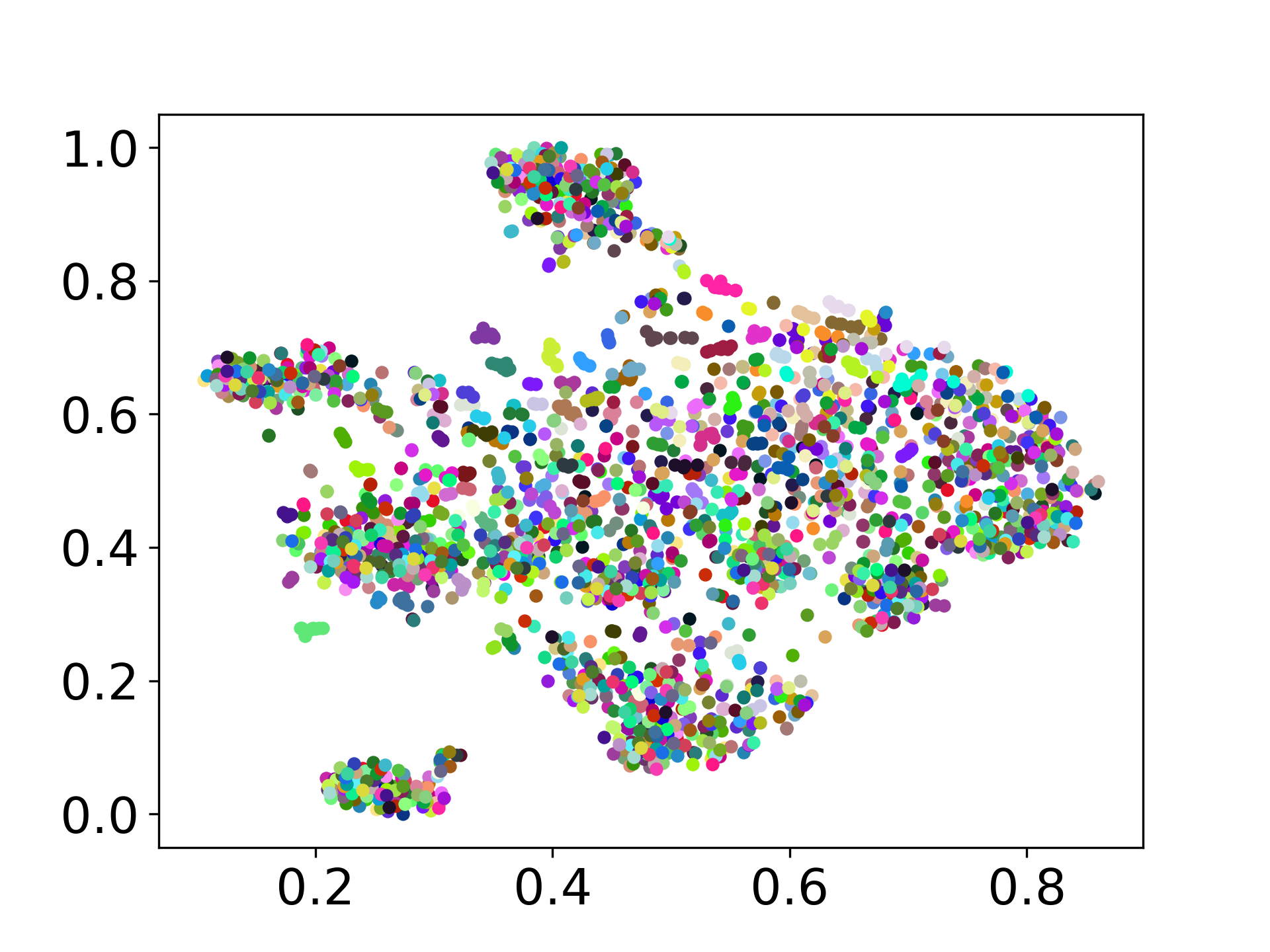
Nossa base de código suporta o uso de vários modelos para os experimentos, fornecendo flexibilidade para personalização além da lista mostrada abaixo:
Sinta -se à vontade para criar um problema se tiver alguma dúvida. E crie um PR para corrigir erros ou adicionar melhorias (ou seja, adicionar novos conjuntos de dados ou modelos).
Se você estiver interessado em criar uma extensão deste trabalho, sinta -se à vontade para nos alcançar!
Apoie nosso esforço de código aberto
Estamos melhorando o código para torná-lo mais amigável e personalizável. Criamos um novo repositório para implementar o Distfuse, disponível em https://github.com/gentaiscool/distfuse/. Você pode instalá -lo executando pip install distfuse . Mais tarde, será integrado a este repositório.


