miners
1.0.0
 : Modèles de langage multilingue comme Retrievers sémantique
: Modèles de langage multilingue comme Retrievers sémantique⚡ Présentation de la référence des mineurs , conçue pour évaluer les prouesses des LMS multilingues dans les tâches de récupération sémantique, y compris l'exploitation et la classification des morsures à travers des contextes auprès de la récupération sans réglage fin . Un cadre complet a été développé pour évaluer l'efficacité des modèles de langage dans la récupération d'échantillons dans plus de 200 langues diverses , y compris les langues à faible ressource dans les paramètres inter-linguaux (XS) et le changement de code (CS) . Les résultats montrent que la réalisation de performances concurrentielles avec des méthodes de pointe est possible en récupérant uniquement des intérêts sémantiquement similaires, sans nécessiter de réglage fin.
Le document a été accepté lors des résultats de l'EMNLP 2024.
Ceci est le code source du papier [arXiv]:
Ce code a été écrit à l'aide de Pytorch. Si vous utilisez un code ou des ensembles de données à partir de cette boîte à outils dans votre recherche, veuillez citer l'article associé.
@article {winata2024miners,
Title = {Miners: Modèles de langage multilingue en tant que Retrievers sémantique},
Auteur = {Winata, Genta Indra et Zhang, Ruochen et Adelani, David Ifeoluwa},
journal = {arXiv Preprint Arxiv: 2406.07424},
année = {2024}
}
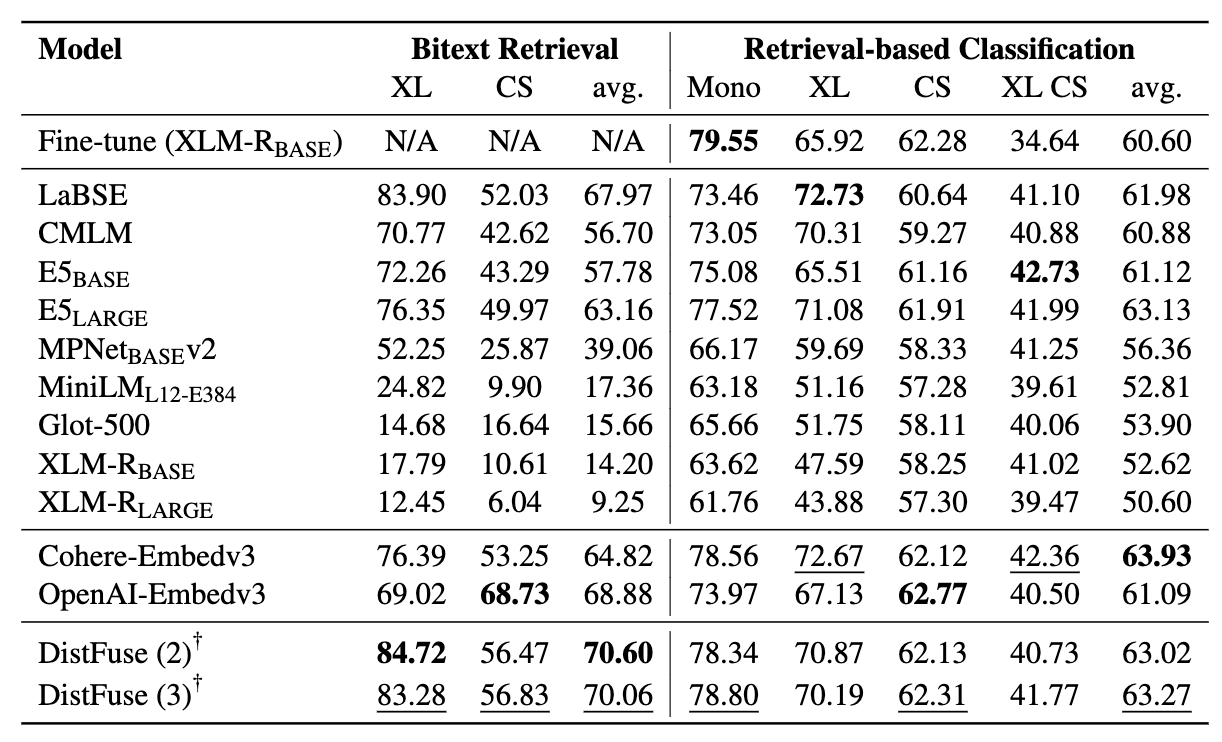
Les mineurs comprennent 11 ensembles de données: 7 ensembles de données multilingues et 4 commutation de code, couvrant plus de 200 langues et englobant à la fois des formats parallèles et de classification. Les ensembles de données parallèles sont adaptés à la récupération de BOWXT car ils contiennent un contenu multilingue aligné, facilitant les tâches d'exploration de morsex et de traduction machine. De plus, les ensembles de données de classification couvrent la classification de l'intention, l'analyse des sentiments et la classification des sujets, que nous évaluons pour les affectations basées sur la récupération et la classification ICL.
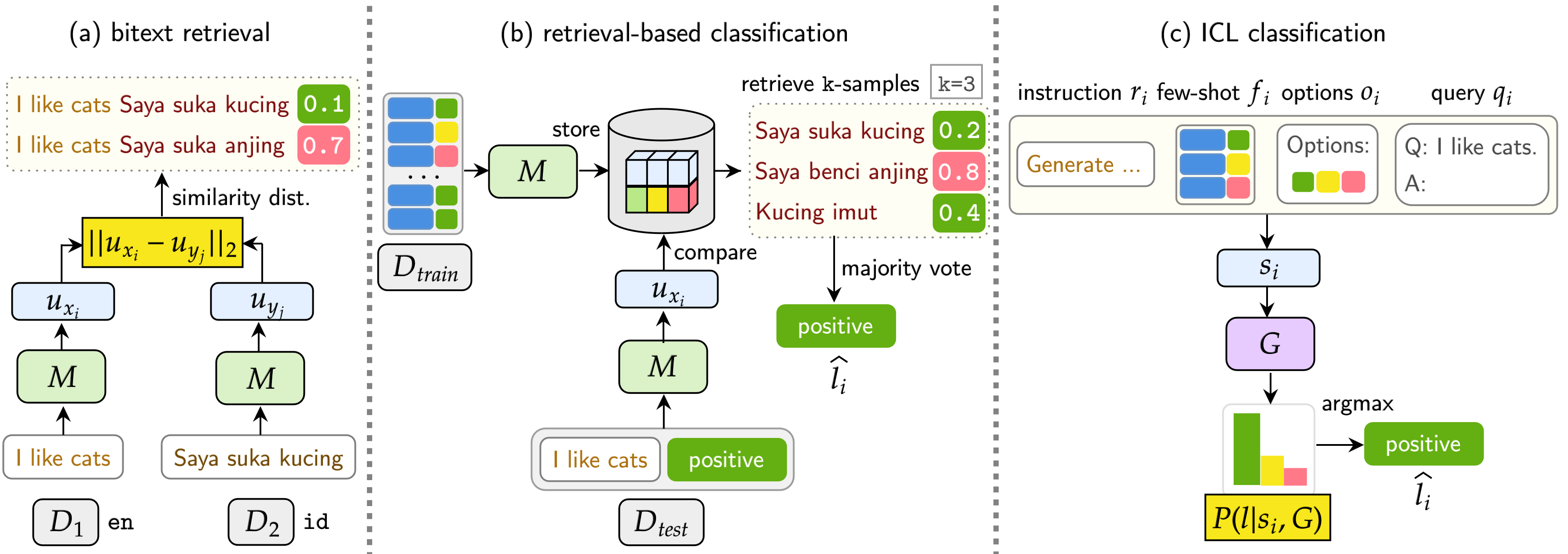
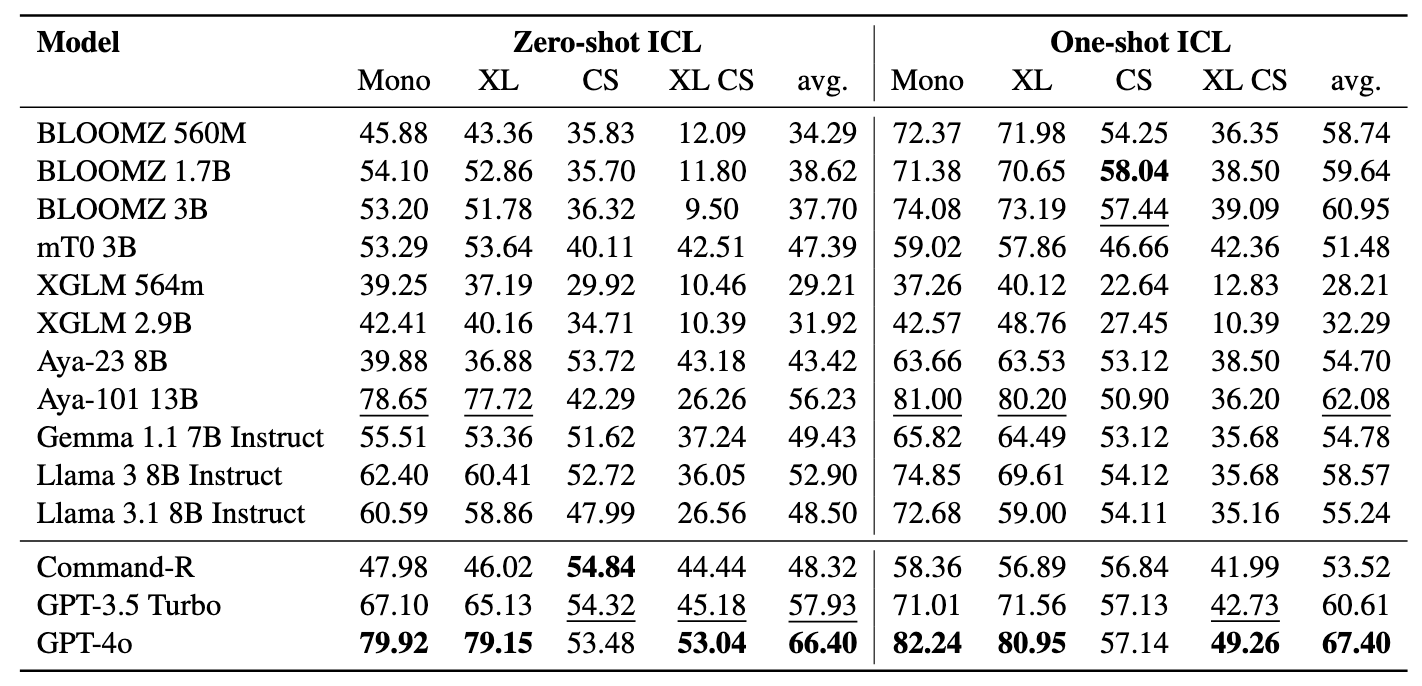
Notre référence évalue LMS sur trois tâches: la récupération de BOCKEXT, la classification basée sur la récupération et la classification ICL. Les paramètres incluent monolingue (mono) , le cross-lingual (XS) , le commutation de code (CS) et le commutation de code trans-galent (XS CS) .
pip install -r requirements.txt
Si vous souhaitez utiliser les API ou les modèles d'Openai, de Cohere ou d'étreindre la face, modifiez l' OPENAI_TOKEN , COHERE_TOKEN et HF_TOKEN . Notez que la plupart des modèles sur le visage étreint ne nécessitent pas le HF_TOKEN , qui est spécifiquement destiné aux modèles LLAMA et GEMMA.
Si vous souhaitez utiliser LLAMA3.1, vous devez mettre à niveau la version Transformers
pip install transformers==4.44.2
Si vous souhaitez obtenir tous les résultats et des exemples rapides de nos expériences, n'hésitez pas à les télécharger ici (~ 360 Mo).
Tous les résultats de l'expérience seront stockés dans les logs/ répertoires. Vous pouvez exécuter chaque expérience en utilisant les commandes suivantes:
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Les arguments sont similaires à ceux ci-dessus, sauf que nous utilisons --model_checkpoints et --weights
❱❱❱ python bitext.py --src_lang {src_lang} --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python bitext.py --src_lang de --dataset bucc --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Ajouter --src_lang et --cross à la commande.
❱❱❱ python classification.py --src_lang {src_lang} --cross --dataset {dataset} --seed {seed} --cuda --model_checkpoint {model_checkpoint}
❱❱❱ python classification.py --src_lang eng --cross --dataset nusax --seed 42 --cuda --model_checkpoint sentence-transformers/LaBSE
Les arguments sont similaires à ceux ci-dessus, sauf que nous utilisons --model_checkpoints et --weights
❱❱❱ python classification.py --dataset {dataset} --seed {seed} --cuda --model_checkpoints {model_checkpoint1} {model_checkpoint2} {...} --weights {weight1} {weight2} {...}
❱❱❱ python classification.py --dataset nusax --seed 42 --cuda --model_checkpoints sentence-transformers/LaBSE intfloat/multilingual-e5-large --weights 0.25 0.75
❱❱❱ python icl.py --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Ajouter --src_lang et --cross à la commande.
❱❱❱ python icl.py --src_lang {src_lang} --cross --dataset {dataset} --seed 42 --instruction {instruction} --model_checkpoint {model} --gen_model_checkpoint {gen_model_checkpoint} --cuda --load_in_8bit --k {k}
❱❱❱ python icl.py --src_lang eng --cross --dataset nusax --seed 42 --instruction "Generate a sentiment label for a given input.nPlease only output the label." --model_checkpoint sentence-transformers/LaBSE --gen_model_checkpoint meta-llama/Meta-Llama-3-8B-Instruct --cuda --load_in_8bit --k 1
Ajouter --k pour modifier le nombre d'échantillons récupérés.
❱❱❱ python script/aggregate/aggregate_bitext_mining.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification.py --k {k}
❱❱❱ python script/aggregate/aggregate_classification_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_cross.py --k {k}
❱❱❱ python script/aggregate/aggregate_icl_percentile.py --k {k}
❱❱❱ python visualize.py --model_checkpoint {model_checkpoint} --dataset {dataset} --seed {seed} --cuda
❱❱❱ python visualize.py --model_checkpoint sentence-transformers/LaBSE --dataset nusax --seed 42 --cuda
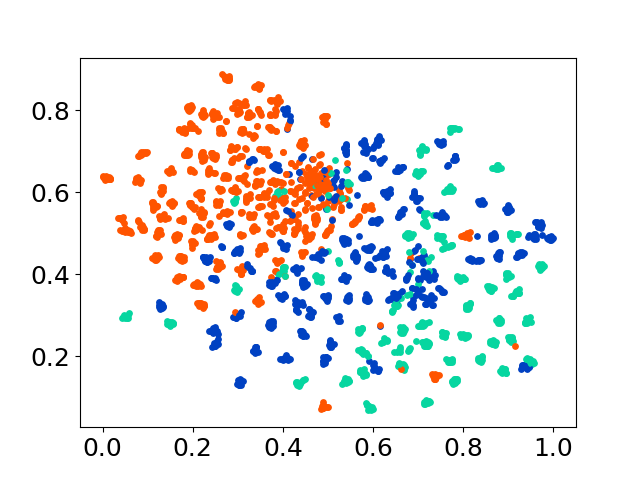
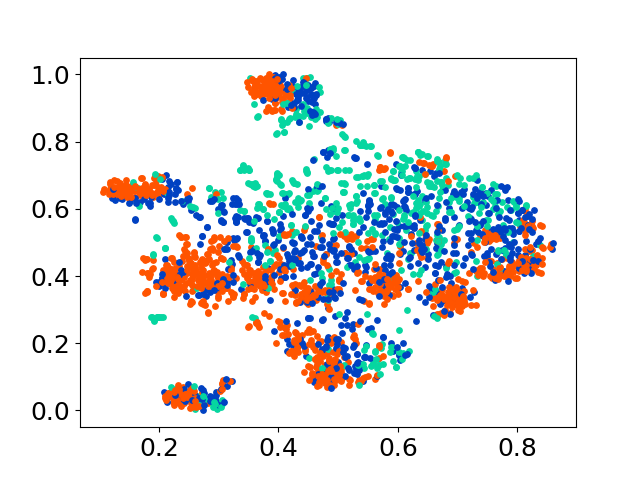
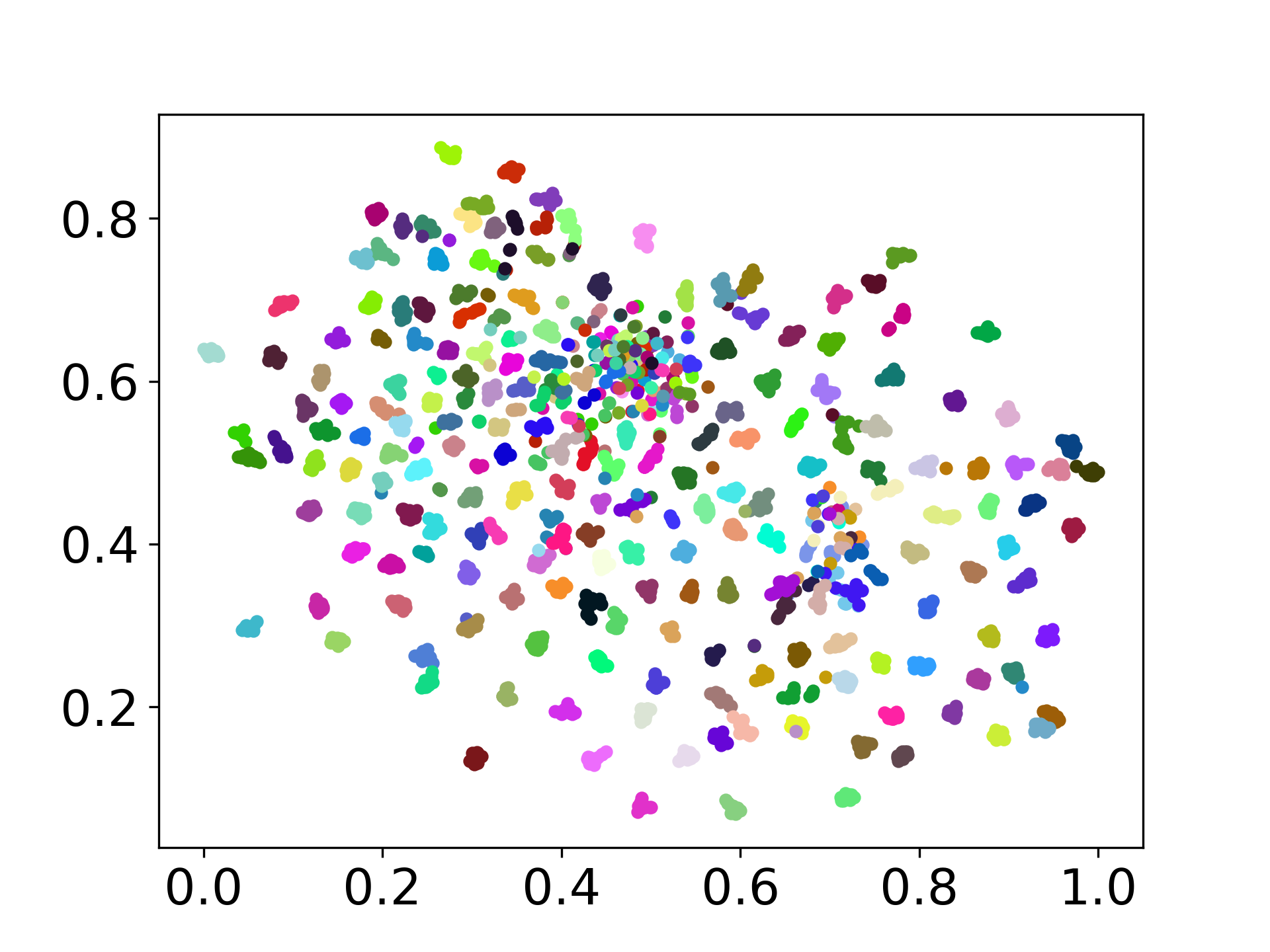
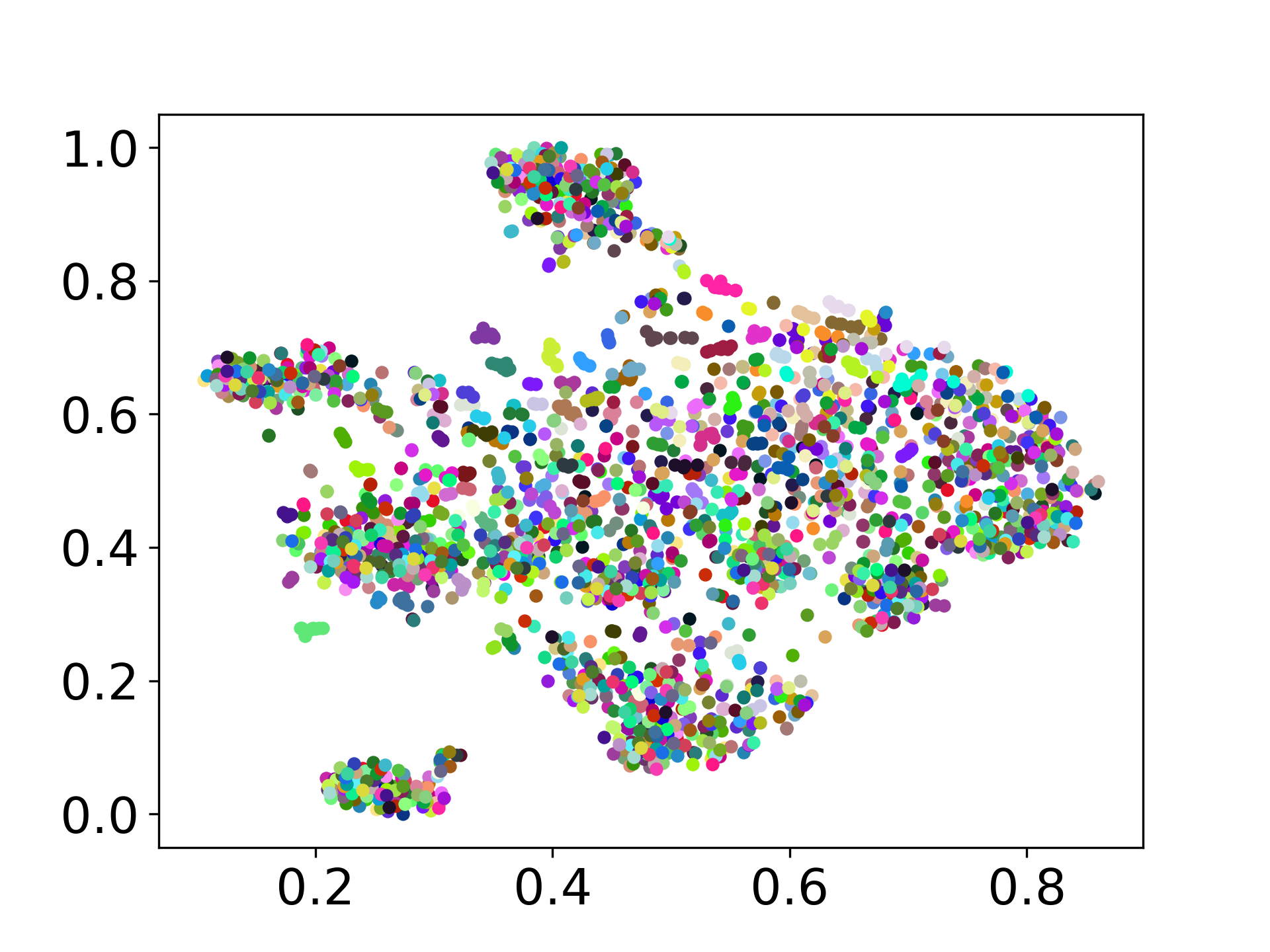
Notre base de code prend en charge l'utilisation de plusieurs modèles pour les expériences, offrant une flexibilité pour la personnalisation au-delà de la liste ci-dessous:
N'hésitez pas à créer un problème si vous avez des questions. Et, créez un RP pour corriger les bogues ou ajouter des améliorations (c'est-à-dire, l'ajout de nouveaux ensembles de données ou modèles).
Si vous êtes intéressé à créer une extension de ce travail, n'hésitez pas à nous contacter!
Soutenez notre effort open source
Nous améliorons le code pour le rendre plus convivial et personnalisable. Nous avons créé un nouveau référentiel pour implémenter Distfuse, qui est disponible sur https://github.com/gentauscool/distfuse/. Vous pouvez l'installer en exécutant pip install distfuse . Plus tard, il sera intégré à ce référentiel.


