Toucan LLM
1.0.0

Toucan是一個開源的、主要支持中文的對話語言模型,基於[Meta 的Large Language Model Meta AI (LLaMA)] 架構,具有70 億參數。結合模型量化技術和稀疏技術,未來可以部署在端側進行推理。 logo的設計源自免費logo設計網站https://app.logo.com/
本項目提供的內容包括微調訓練代碼,基於Gradio的推理代碼,4bit量化代碼及模型合併代碼等。模型的權重(delta weights)可在提供的鏈接中下載,然後合併使用。我們提供的Toucan-7B的效果略好於ChatGLM-6B. 4 bit 量化後的模型與ChatGLM-6B 效果相當。
本模型的開發,使用的是開源代碼,開源數據集。 本項目不承擔開源模型和代碼導致的數據安全、輿情風險或發生任何模型被誤導、濫用、傳播、不當利用而產生的風險和責任。
客觀評價分數主要依照這個開源代碼https://github.com/LianjiaTech/BELLE/tree/main/eval
樣例如下:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}上面示例中, 數據裡提供的標註答案, 示例如下。
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
上面示例中,以Toucan為例生成的回答:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )上面示例中, 以ChatGPT打分的結果
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
依照上述的測試邏輯, 我們測試了接近1000的測試案例,類別總結如下。 我們對比了不同模型在不同類別下測試效果。 Toucan-7B的效果略好於ChatGLM-6B, 但是還是弱於ChatGPT.
| 模型名稱 | 平均分 | math | code | classi fication | extract | open qa | closed qa | generation | brainstorming | rewrite | summarization | 去除math 和code 的平均分 | 註釋 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-inst-chat-7b | 0.5017 | 0.275 | 0.675 | 0.329 | 0.19 | 0.54 | 0.35 | 0.825 | 0.81 | 0.8 | 0.27 | 0.514 | num_beams = 4, do_sample = False,min_new_tokens=1,max_new_tokens=512, |
| alpaca-7b | 0.4155 | 0.0455 | 0.535 | 0.52 | 0.2915 | 0.1962 | 0.5146 | 0.475 | 0.3584 | 0.8163 | 0.4026 | 0.4468 | |
| alpaca-7b-plus | 0.4894 | 0.1583 | 0.4 | 0.493 | 0.1278 | 0.3524 | 0.4214 | 0.9125 | 0.8571 | 0.8561 | 0.3158 | 0.542 | |
| ChatGLM | 0.62 | 0.27 | 0.536 | 0.57 | 0.48 | 0.37 | 0.6 | 0.93 | 0.9 | 0.87 | 0.64 | 0.67 | |
| Toucan-7B | 0.6408 | 0.17 | 0.73 | 0.7 | 0.426 | 0.48 | 0.63 | 0.92 | 0.89 | 0.93 | 0.52 | 0.6886 | |
| Toucan-7B-4bit | 0.6225 | 0.1492 | 0.6826 | 0.6862 | 0.4139 | 0.4716 | 0.5711 | 0.9129 | 0.88 | 0.9088 | 0.5487 | 0.6741 | |
| ChatGPT | 0.824 | 0.875 | 0.875 | 0.813 | 0.767 | 0.69 | 0.751 | 0.971 | 0.944 | 0.861 | 0.795 | 0.824 |
Phoenix-inst-chat-7b: https://github.com/FreedomIntelligence/LLMZoo
Alpaca-7b/Alpaca-7b-plus: https://github.com/ymcui/Chinese-LLaMA-Alpaca
ChatGLM: https://github.com/THUDM/ChatGLM-6B
由上圖所示, 我們提供的Toucan-7B的效果略好於ChatGLM-6B. 4 bit 量化後的模型與ChatGLM-6B 效果相當。
可以通過conda創建環境,然後pip安裝需要的包, train文件下有requirements.txt可查看需要的安裝包, python版本3.10
conda create -n Toucan python=3.10
然後執行下面的命令安裝,建議先安裝torch
pip install -r train/requirements.txt
訓練主要使用開源數據:
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
belle數據:belle_cn
其中belle數據使用不到一半,可適當選取。
原版LLaMA模型的詞表大小是32K,主要針對英語進行訓練,llama理解和生成中文的能力受到限制。 Chinese-LLaMA-Alpaca在原版LLaMA的基礎上進一步擴充了中文詞表,並在中文語料庫上進行預訓練。因預訓練受到資源等條件限制,我們在Chinese-LLaMA-Alpaca預訓練模型的基礎上繼續做了相應開發工作。
模型全參數微調+deepspeed, 訓練啟動的腳本在train/run.sh,可根據情況修改參數
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
——model_name_or_path 代表預訓練模型,llama模型為hugging face格式——data_path 代表訓練數據——output_dir 代表訓練日誌和模型保存的路徑
1,如果是單卡訓練,將nproc_per_node設置為1
2,如果運行環境不支持deepspeed,去掉--deepspeed
本實驗是在NVIDIA GeForce RTX 3090,使用deepspeed配置參數,可有效避免OOM問題。
python scripts/demo.py我們開源了訓練好的delta weights, 同時考慮了遵守LLaMA模型的License. 你可以使用下面的命令來回復原本的模型weights.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ diff-ckpt 可以在Onedrive 下載here
百度網盤下載這裡
下圖是在多輪對話之後測得的顯存佔用情況,均在NVIDIA GeForce RTX 3090機器上推理測試。 4bit模型可有效降低顯存佔用。
toucan-16bit
初始佔用
token長度1024 num beams=4;token長度2048會OOM; 
token長度2048 num beams=1; 
toucan-4bit
初始佔用
token長度2048 num beams=4; 
token長度2048 num beams=1; 
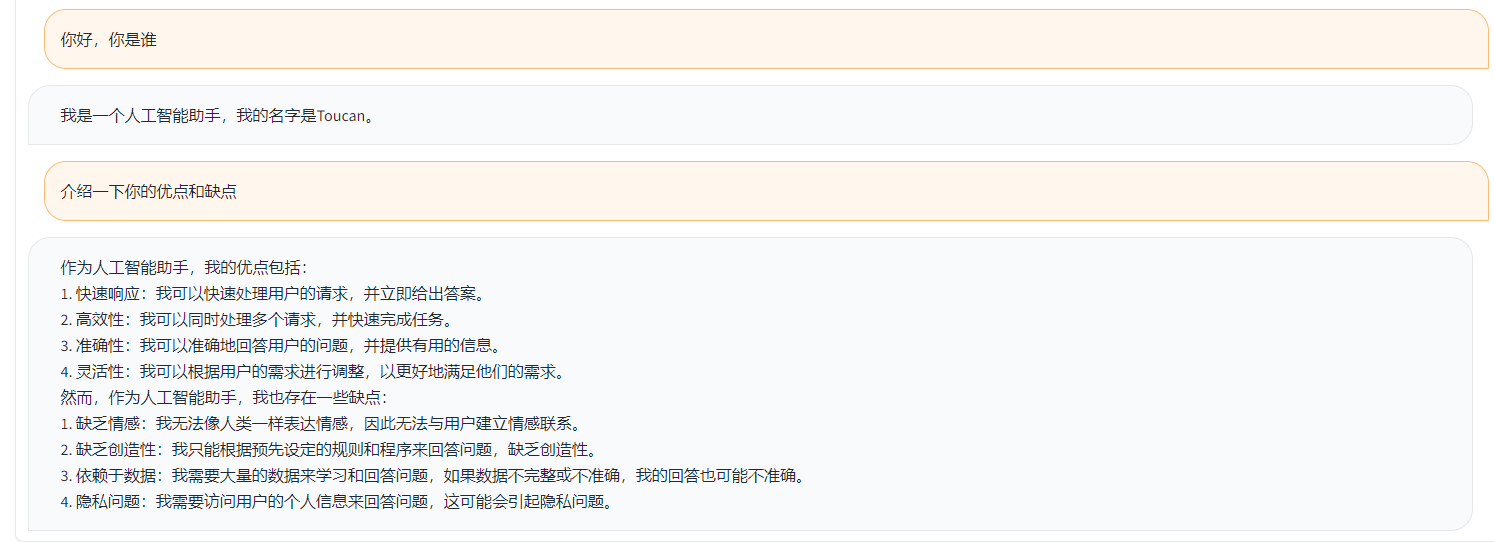
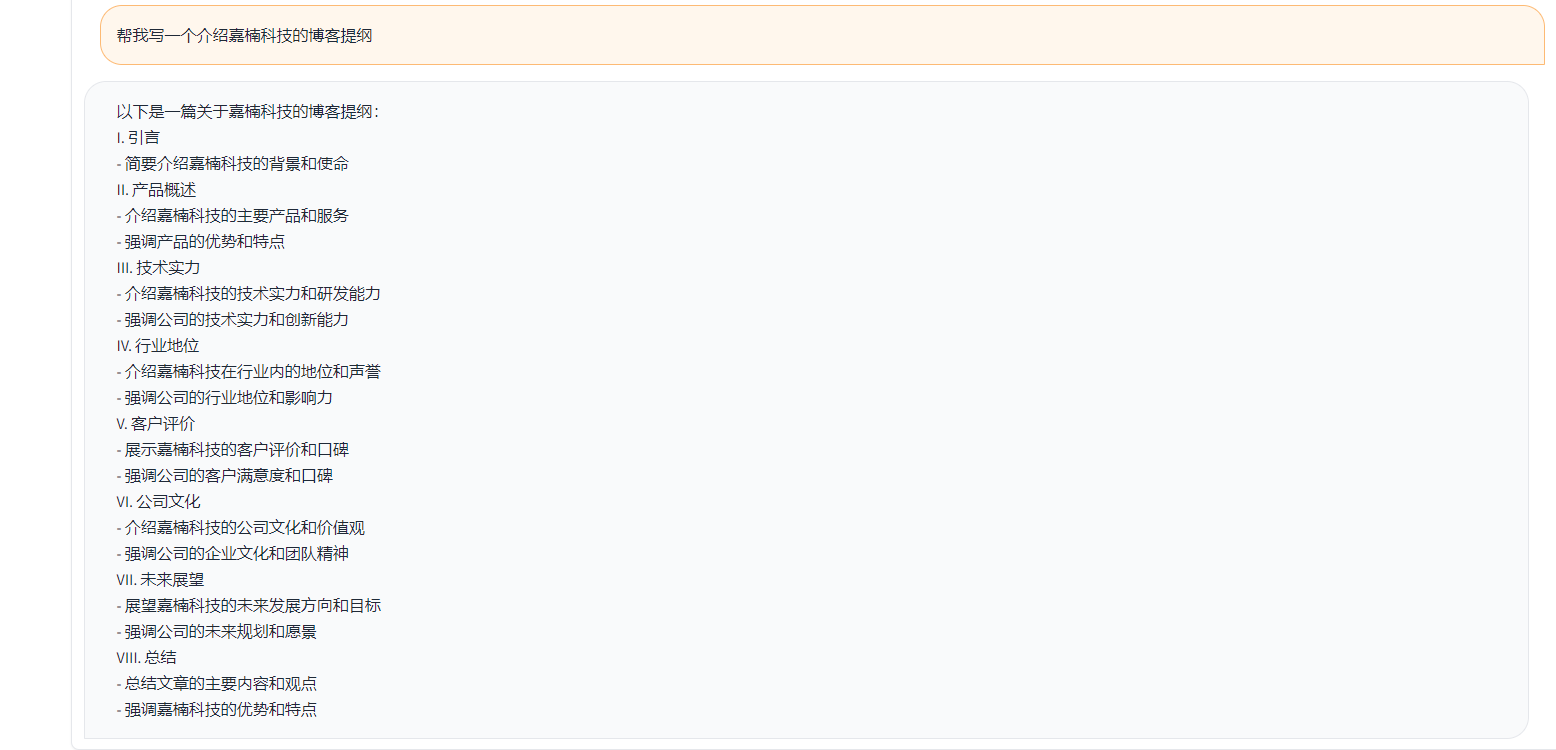
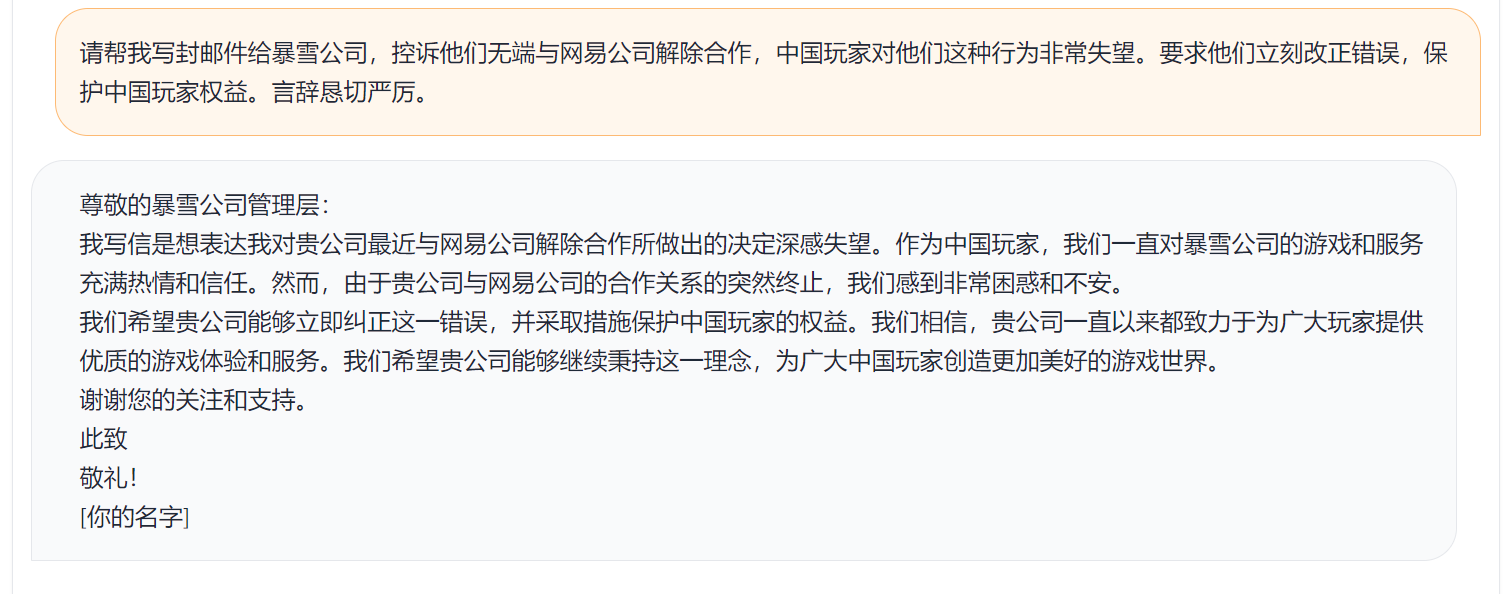
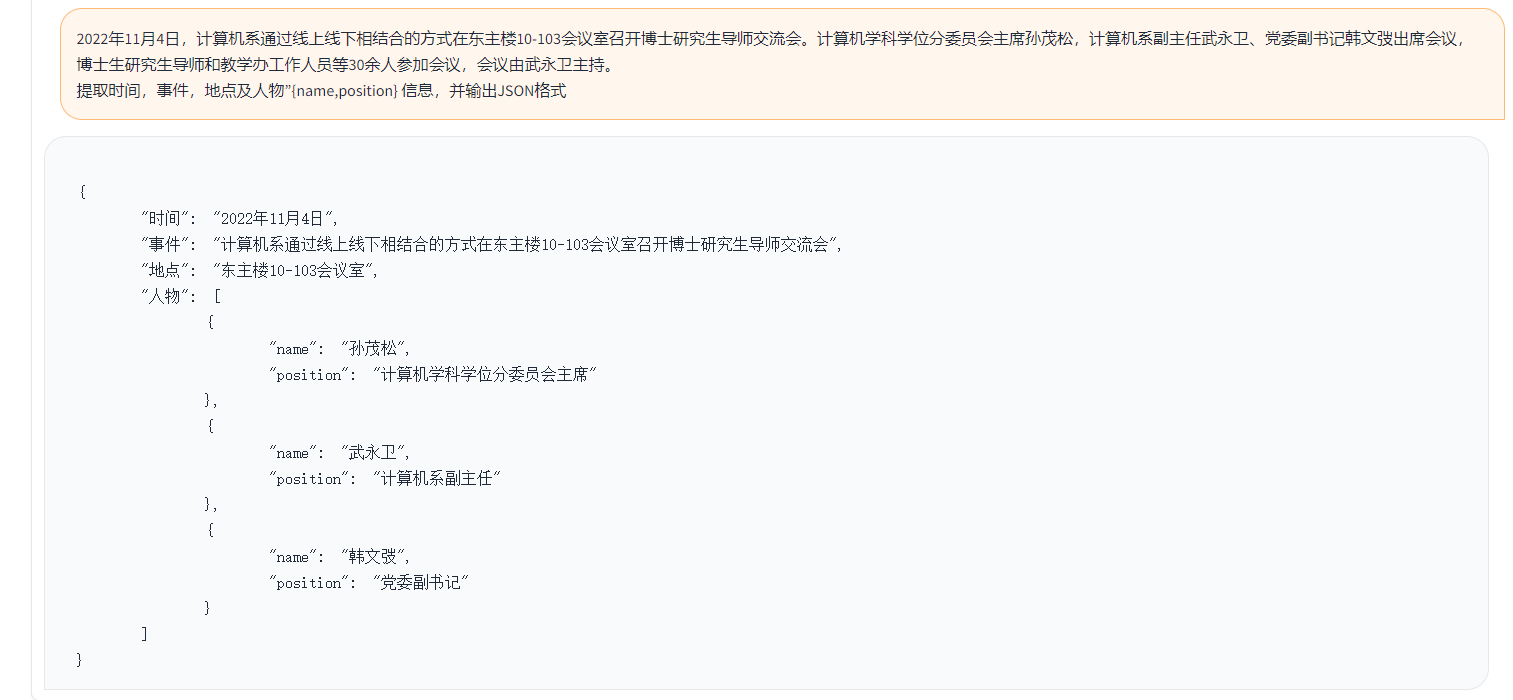
簡單的demo 如下圖所示。

這裡的DEMO參考了ChatGLM裡的實現。