Toucan LLM
1.0.0

Toucan은 [Meta의 대형 언어 모델 Meta AI (LLAMA)] 아키텍처를 기반으로 한 오픈 소스, 주로 중국의지지 대화 언어 모델이며 70 억 매개 변수를 보유하고 있습니다. 모델 양자화 기술과 희소 기술을 결합하여 향후 추론을 위해 최종 측에 배치 할 수 있습니다. 로고의 디자인은 무료 로고 디자인 웹 사이트 https://app.logo.com/에서 제공됩니다.
이 프로젝트에서 제공하는 컨텐츠에는 미세 조정 교육 코드, Gradio 기반 추론 코드, 4 비트 양자화 코드 및 모델 병합 코드 등이 포함됩니다. 모델의 가중치는 제공된 링크에서 다운로드 한 다음 사용하도록 결합 할 수 있습니다. 우리가 제공하는 Toucan-7B는 ChatGLM-6B보다 약간 낫습니다. 4 비트 정량화 된 모델은 ChatGLM-6B와 비슷합니다.
이 모델의 개발은 오픈 소스 코드와 오픈 소스 데이터 세트를 사용합니다. 이 프로젝트는 데이터 보안, 오픈 소스 모델 및 코드로 인한 여론 위험 또는 오해의 소지가있는 위험 및 책임으로 인한 위험과 책임을 가정하지 않습니다.
목표 평가 점수는 주로이 오픈 소스 코드 https://github.com/lianjiatech/belle/tree/main/eval을 기반으로합니다.
예는 다음과 같습니다.
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}위의 예에서는 데이터에 제공된 주석이 달린 답변은 다음과 같습니다.
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
위의 예에서는 Toucan이 생성 한 답변이 예를 들어 있습니다.
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )위의 예에서는 Chatgpt와의 점수의 결과
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
위의 테스트 로직에 따르면, 우리는 거의 1,000 개의 테스트 사례를 테스트했으며 카테고리는 다음과 같이 요약됩니다. 다른 범주에서 다른 모델의 테스트 효과를 비교했습니다. Toucan-7b의 효과는 ChatGLM-6B의 효과보다 약간 낫지 만 여전히 chatgpt보다 약합니다.
| 모델 이름 | 평균 점수 | 수학 | 암호 | 분류 | 발췌 | 열린 QA | 폐쇄 QA | 세대 | 브레인 스토밍 | 고쳐 쓰기 | 요약 | 수학 및 코드의 평균 점수를 제거하십시오 | 의견 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 피닉스 인치 샤트 -7b | 0.5017 | 0.275 | 0.675 | 0.329 | 0.19 | 0.54 | 0.35 | 0.825 | 0.81 | 0.8 | 0.27 | 0.514 | num_beams = 4, do_sample = false, min_new_tokens = 1, max_new_tokens = 512, |
| 알파카 -7b | 0.4155 | 0.0455 | 0.535 | 0.52 | 0.2915 | 0.1962 | 0.5146 | 0.475 | 0.3584 | 0.8163 | 0.4026 | 0.4468 | |
| 알파카 -7b- 플러스 | 0.4894 | 0.1583 | 0.4 | 0.493 | 0.1278 | 0.3524 | 0.4214 | 0.9125 | 0.8571 | 0.8561 | 0.3158 | 0.542 | |
| chatglm | 0.62 | 0.27 | 0.536 | 0.57 | 0.48 | 0.37 | 0.6 | 0.93 | 0.9 | 0.87 | 0.64 | 0.67 | |
| Toucan-7b | 0.6408 | 0.17 | 0.73 | 0.7 | 0.426 | 0.48 | 0.63 | 0.92 | 0.89 | 0.93 | 0.52 | 0.6886 | |
| Toucan-7B-4 비트 | 0.6225 | 0.1492 | 0.6826 | 0.6862 | 0.4139 | 0.4716 | 0.5711 | 0.9129 | 0.88 | 0.9088 | 0.5487 | 0.6741 | |
| chatgpt | 0.824 | 0.875 | 0.875 | 0.813 | 0.767 | 0.69 | 0.751 | 0.971 | 0.944 | 0.861 | 0.795 | 0.824 |
Phoenix-inst-chat-7b : https://github.com/freedomintelligence/llmzoo
Alpaca-7b/alpaca-7b-plus : https://github.com/ymcui/chinese-llama-alpaca
chatglm : https://github.com/thudm/chatglm-6b
위 그림과 같이, Toucan-7b는 ChatGLM-6B보다 약간 더 나은 결과를 제공합니다. 4 비트 정량화 된 모델은 ChatGLM-6B와 비슷합니다.
Conda를 통해 환경을 만들고 PIP로 필요한 패키지를 설치할 수 있습니다. 필요한 설치 패키지, Python 버전 3.10을 볼 수있는 요구 사항이 있습니다.
콘다 생성 -n toucan python = 3.10
그런 다음 설치하려면 다음 명령을 실행하면 먼저 Torch를 설치하는 것이 좋습니다.
PIP 설치 -R 기차/요구 사항 .txt
교육은 주로 오픈 소스 데이터를 사용합니다.
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
벨 데이터 : Belle_CN
그중에서도 Belle 데이터의 절반 미만을 적절하게 선택할 수 있습니다.
원래 라마 모델의 어휘 크기는 32K이며 주로 영어로 훈련되며 중국어를 이해하고 생성하는 능력은 제한적입니다. 중국-알라마 알파카는 원래 라마를 기반으로 중국 어휘를 더욱 확장하고 중국 코퍼스에서 사전 훈련을 수행했습니다. 자원과 같은 자원 조건으로 인한 사전 훈련의 한계로 인해 중국어-알라마-알파카 사전 훈련 된 모델을 기반으로 해당 개발 작업을 계속했습니다.
모델 + DeepSpeed의 전체 매개 변수 미세 조정, 훈련에서 시작한 스크립트는 Train/Run.sh이며, 상황에 따라 매개 변수를 수정할 수 있습니다.
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
—— model_name_or_path는 미리 훈련 된 모델을 나타내고, llama 모델은 얼굴 형식을 포옹합니다-data_path는 훈련 데이터를 나타냅니다. Output_dir
1. 단일 카드 교육 인 경우 nproc_per_node를 1로 설정하십시오.
2. 실행중인 환경이 DeepSpeed를 지원하지 않으면 -deepspeed를 제거하십시오.
이 실험은 NVIDIA GeForce RTX 3090에 있으며 딥 스피드 구성 매개 변수를 사용하면 OOM 문제를 효과적으로 피할 수 있습니다.
python scripts/demo.py우리는 오픈 소스 훈련 델타 웨이트를 열고 라마 모델을 준수하는 라이센스를 고려합니다. 다음 명령을 사용하여 원래 모델 가중치에 응답 할 수 있습니다.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ Diff-CKPT는 OneDrive에서 여기에서 다운로드 할 수 있습니다
여기에서 Baidu NetDisk를 다운로드하십시오
아래 그림은 여러 라운드의 대화 후 측정 된 비디오 메모리 사용량을 보여줍니다. 모두 NVIDIA GeForce RTX 3090 기계에서 추론되었습니다. 4 비트 모델은 메모리 사용량을 효과적으로 줄일 수 있습니다.
Toucan-16 비트
초기 직업 
토큰 길이 1024 Num Beams = 4; 토큰 길이 2048은 Oom; 
토큰 길이 2048 Num Beams = 1; 
Toucan-4 비트
초기 직업 
토큰 길이 2048 Num Beams = 4; 
토큰 길이 2048 Num Beams = 1; 
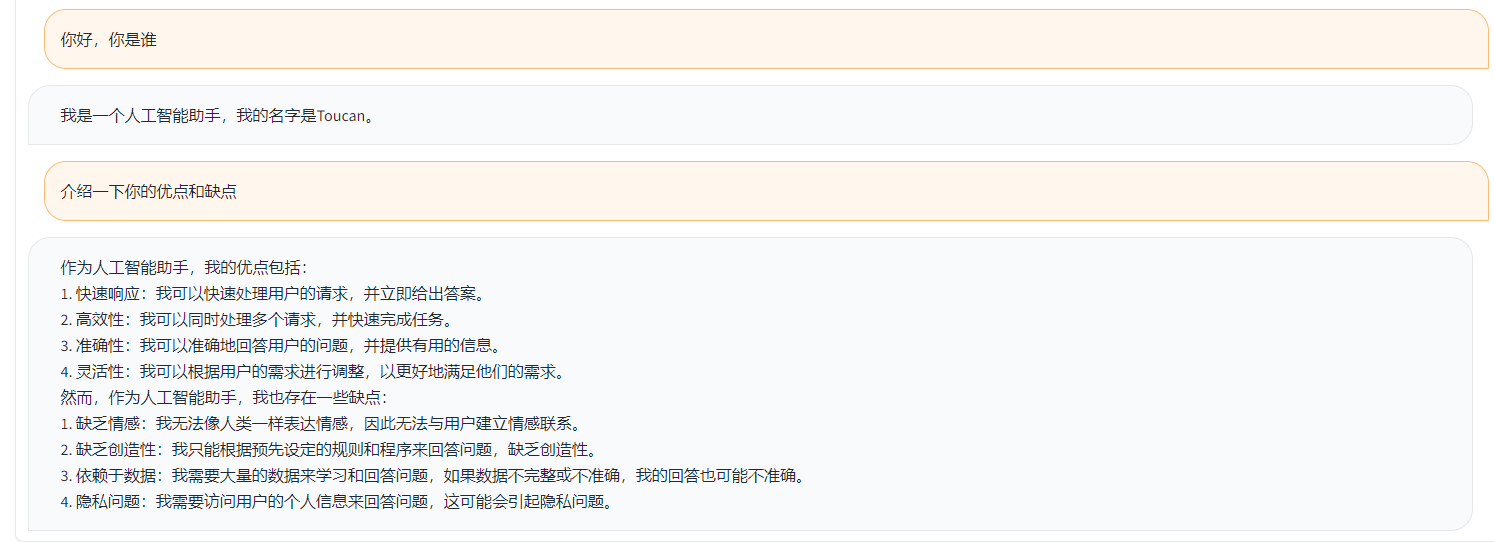
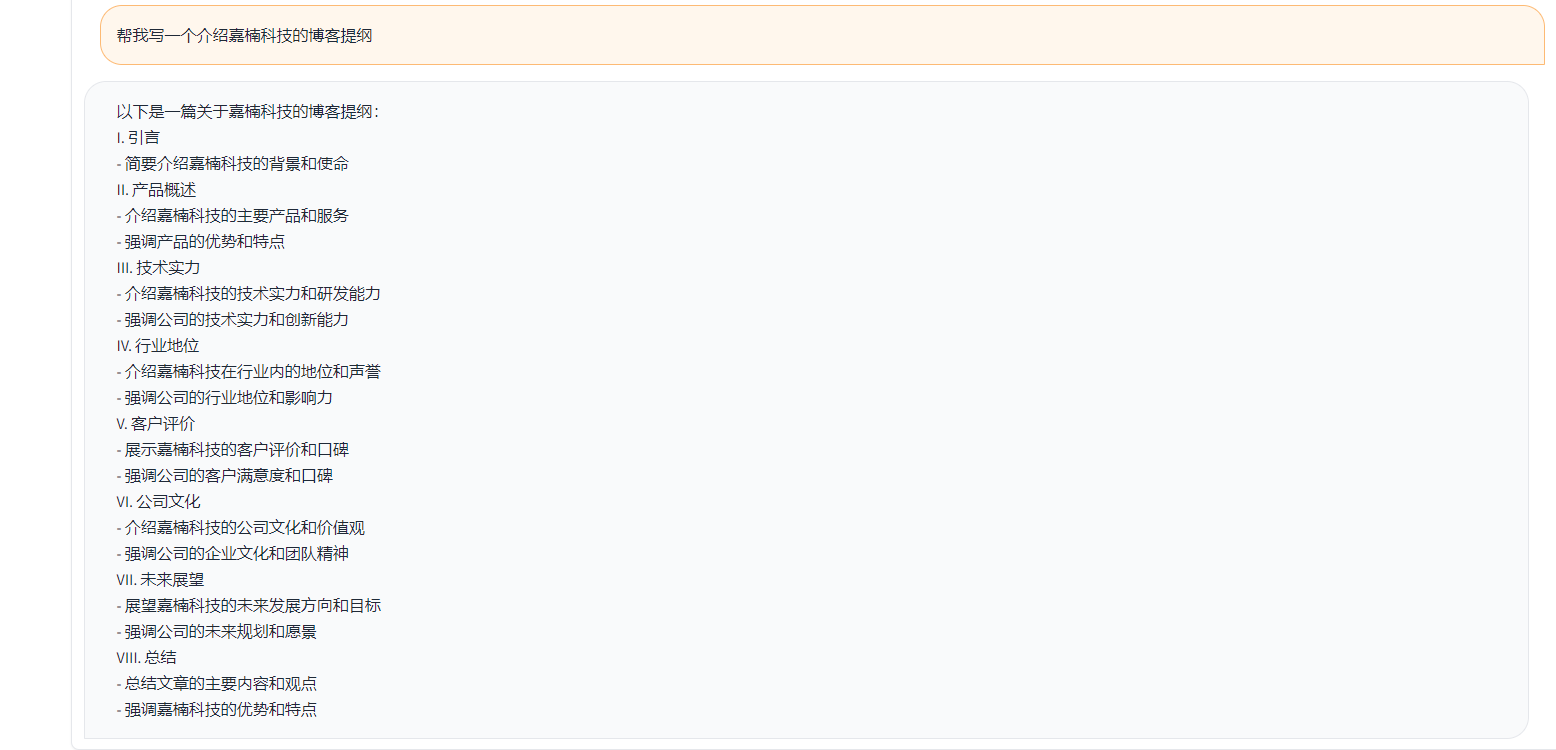
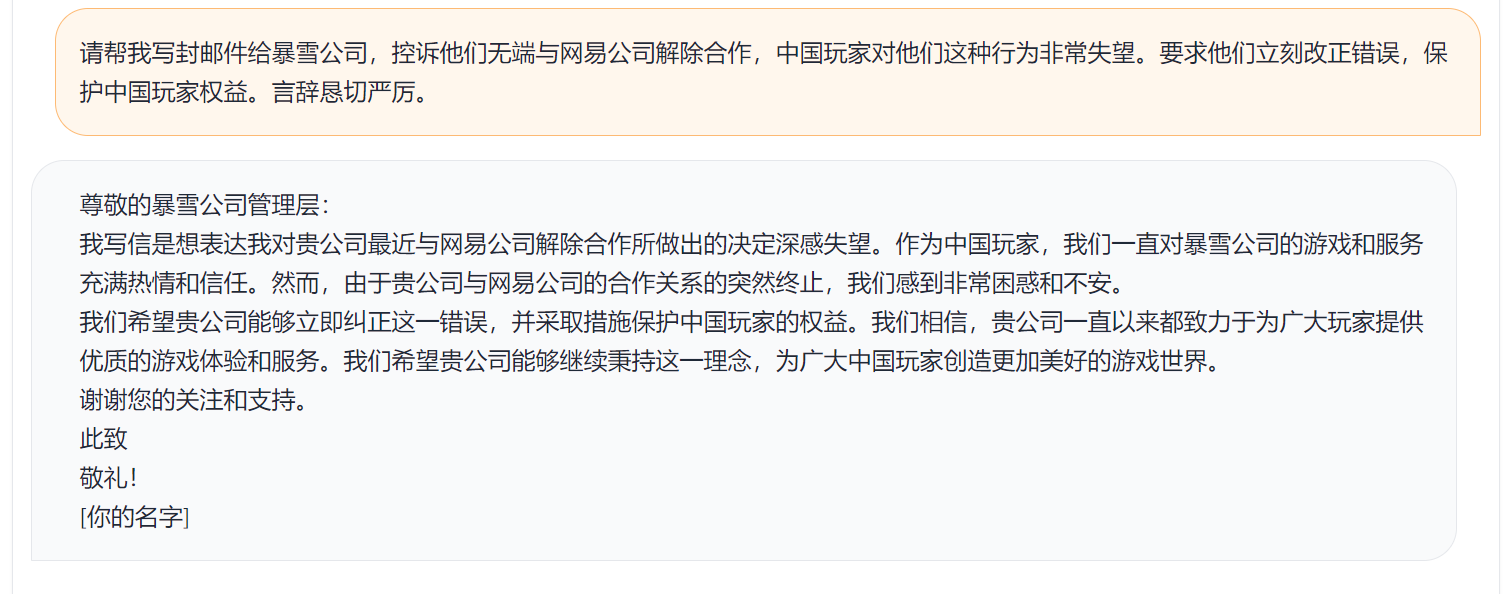
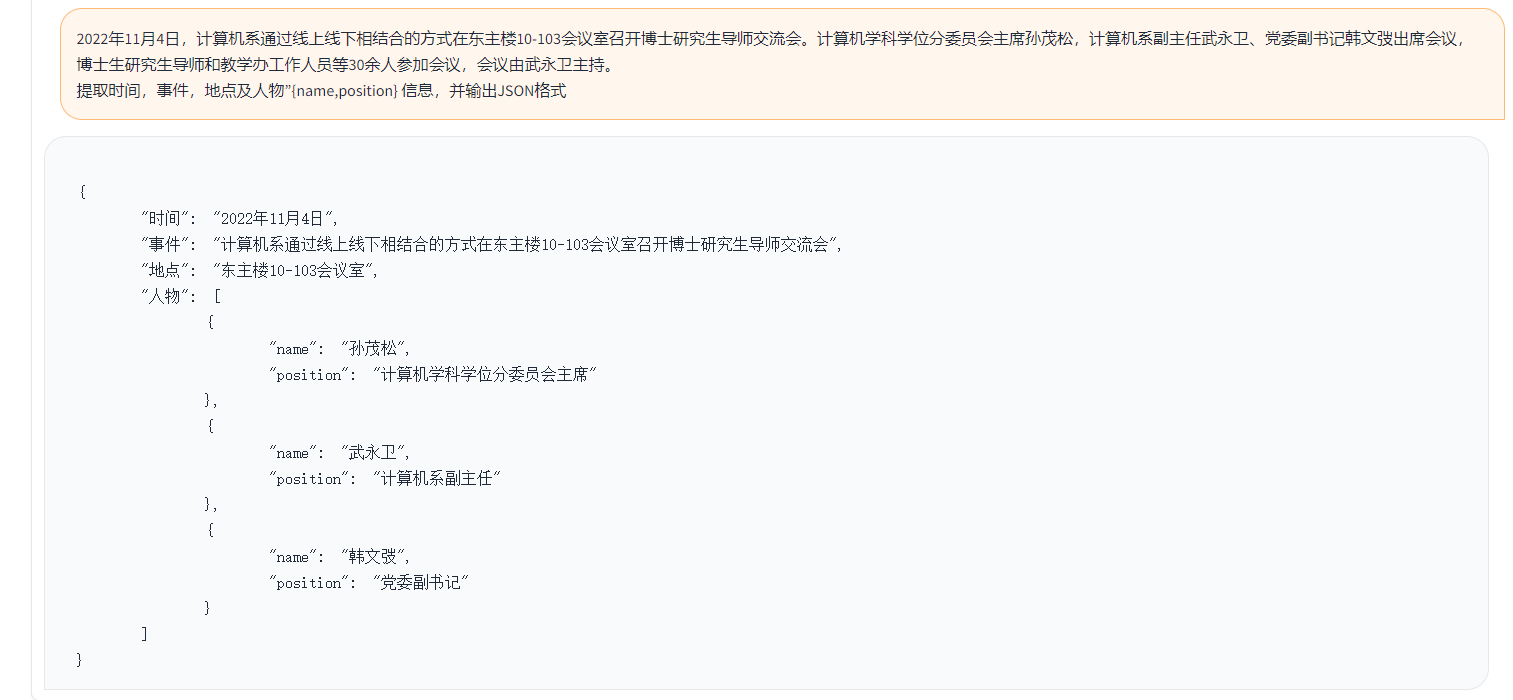
간단한 데모는 아래 그림에 나와 있습니다.

여기에서 Demo는 ChatGLM의 구현을 나타냅니다.