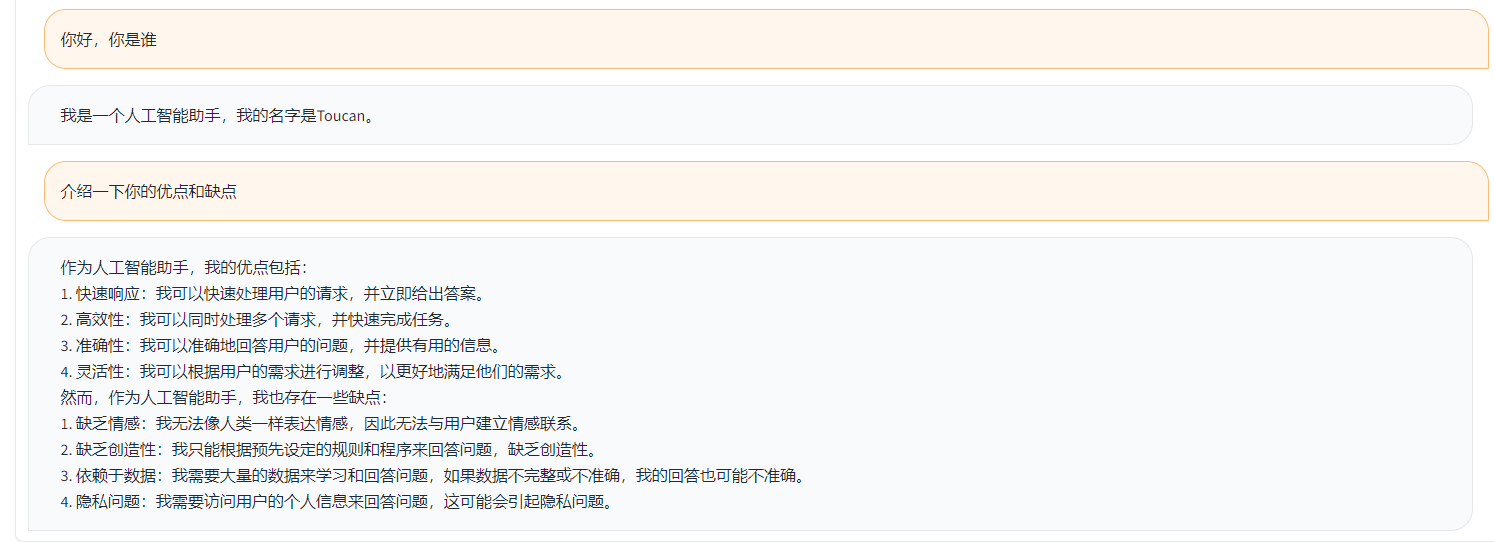
Toucan LLM
1.0.0

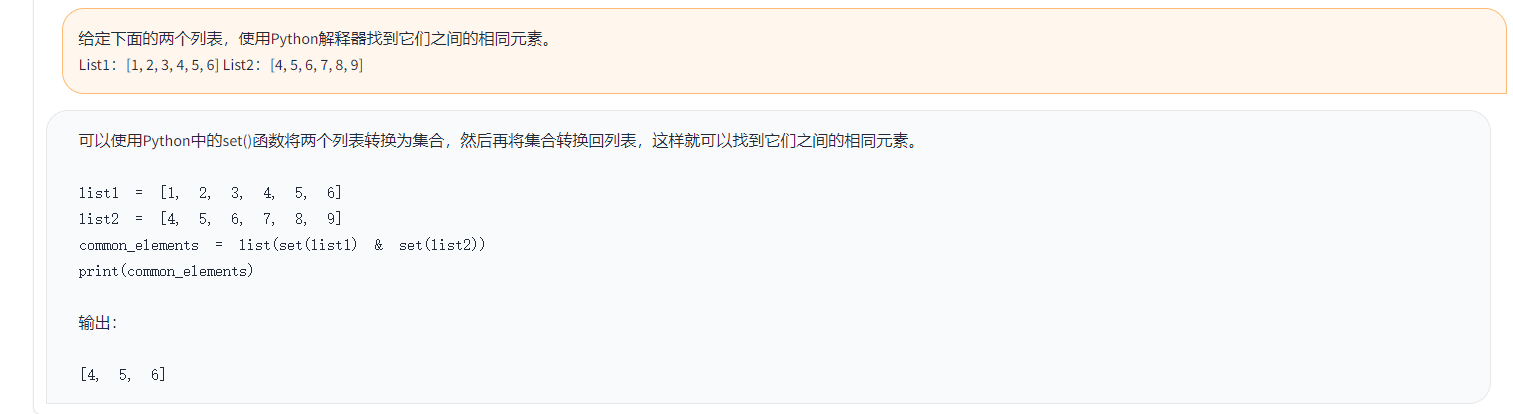
Toucanは、[Metaの大規模な言語モデルMeta AI(LLAMA)]アーキテクチャに基づいた、主に中国がサポートするダイアログ言語モデルであり、70億パラメーターを備えたオープンソースです。モデルの量子化技術とスパーステクノロジーを組み合わせて、将来的に推論のためにエンドサイドに展開できます。ロゴのデザインは、無料のロゴデザインWebサイトhttps://app.logo.com/からのものです
このプロジェクトで提供されるコンテンツには、微調整トレーニングコード、グラデーションベースの推論コード、4ビット量子化コード、モデルのマージコードなどが含まれます。モデルの重みを提供して、使用して使用することができます。私たちが提供するToucan-7Bは、chatglm-6bよりもわずかに優れています。 4ビット定量化モデルは、chatglm-6bに匹敵します。
このモデルの開発では、オープンソースコードとオープンソースのデータセットを使用します。このプロジェクトは、データのセキュリティ、オープンソースモデルとコードによって引き起こされる世論のリスク、またはあらゆるモデルの誤解を招く、虐待、普及、または不適切な使用から生じるリスクと責任から生じるリスクや責任を想定していません。
客観的評価スコアは、主にこのオープンソースコードhttps://github.com/lianjiatech/belle/tree/main/evalに基づいています
例は次のとおりです。
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}上記の例では、データに記載されている注釈付きの回答は次のとおりです。
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
上記の例では、例としてToucanによって生成された答え:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )上記の例では、chatgptで得点の結果
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
上記のテストロジックによると、1,000件近くのテストケースをテストし、カテゴリを次のように要約します。さまざまなカテゴリで異なるモデルのテスト効果を比較しました。 Toucan-7Bの効果は、Chatglm-6Bの効果よりもわずかに優れていますが、ChatGptよりも弱いです。
| モデル名 | 平均スコア | 数学 | コード | 分類 | 抽出する | QAを開きます | 閉じたQA | 世代 | ブレーンストーミング | リライト | 要約 | 数学とコードの平均スコアを削除します | コメント |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-inst-chat-7b | 0.5017 | 0.275 | 0.675 | 0.329 | 0.19 | 0.54 | 0.35 | 0.825 | 0.81 | 0.8 | 0.27 | 0.514 | num_beams = 4、do_sample = false、min_new_tokens = 1、max_new_tokens = 512、 |
| Alpaca-7B | 0.4155 | 0.0455 | 0.535 | 0.52 | 0.2915 | 0.1962 | 0.5146 | 0.475 | 0.3584 | 0.8163 | 0.4026 | 0.4468 | |
| alpaca-7b-plus | 0.4894 | 0.1583 | 0.4 | 0.493 | 0.1278 | 0.3524 | 0.4214 | 0.9125 | 0.8571 | 0.8561 | 0.3158 | 0.542 | |
| chatglm | 0.62 | 0.27 | 0.536 | 0.57 | 0.48 | 0.37 | 0.6 | 0.93 | 0.9 | 0.87 | 0.64 | 0.67 | |
| Toucan-7b | 0.6408 | 0.17 | 0.73 | 0.7 | 0.426 | 0.48 | 0.63 | 0.92 | 0.89 | 0.93 | 0.52 | 0.6886 | |
| Toucan-7b-4bit | 0.6225 | 0.1492 | 0.6826 | 0.6862 | 0.4139 | 0.4716 | 0.5711 | 0.9129 | 0.88 | 0.9088 | 0.5487 | 0.6741 | |
| chatgpt | 0.824 | 0.875 | 0.875 | 0.813 | 0.767 | 0.69 | 0.751 | 0.971 | 0.944 | 0.861 | 0.795 | 0.824 |
Phoenix-inst-chat-7b:https://github.com/freedomintelligence/llmzoo
Alpaca-7b/alpaca-7b-plus:https://github.com/ymcui/chinese-llama-alpaca
chatglm:https://github.com/thudm/chatglm-6b
上の図に示すように、Toucan-7BはChatGlm-6Bよりもわずかに優れた結果を提供します。 4ビット定量化モデルは、chatglm-6bに匹敵します。
Condaを介して環境を作成し、PIPで必要なパッケージをインストールできます。必要なインストールパッケージを表示するために、電車ファイルの下にcompoys.txtがあります、pythonバージョン3.10
Conda Create -N Toucan Python = 3.10
次に、次のコマンドを実行してインストールします。最初にトーチをインストールすることをお勧めします
PIPインストール-R Train/Recomations.txt
トレーニングは主にオープンソースデータを使用します。
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
ベルデータ:belle_cn
その中で、ベルデータの半分未満を適切に選択できます。
元のLlamaモデルの語彙サイズは32Kで、これは主に英語のために訓練されており、中国語を理解して生成する能力は限られています。中国 - ラマアルパカは、元のラマに基づいて中国の語彙をさらに拡大し、中国のコーパスで事前トレーニングを行いました。リソースなどのリソース条件によるトレーニング前の制限により、我々は中国とラマとアルパカの事前訓練モデルに基づいて、対応する開発作業を続けました。
モデル +ディープスピードの完全なパラメーターの微調整、トレーニングによって開始されたスクリプトはTrain/run.shであり、パラメーターは状況に応じて変更できます。
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
—Model_name_or_pathは事前に訓練されたモデルを表し、llamaモデルは顔の形式を抱きしめています - data_pathはトレーニングデータを表します - output_dirはトレーニングログとモデルによって保存されたパスを表します
1.単一のカードトレーニングの場合は、nproc_per_nodeを1に設定します
2.実行中の環境がディープスピードをサポートしていない場合は、削除 - ディープスピード
この実験は、NVIDIA GeForce RTX 3090で行われ、DeepSpeed構成パラメーターを使用すると、OOMの問題を効果的に回避できます。
python scripts/demo.pyデルタの重量を訓練し、Llamaモデルを順守するライセンスを検討します。次のコマンドを使用して、元のモデルの重みに返信できます。
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ diff-ckptは、onedriveでここからダウンロードできます
Baidu Netdiskをこちらからダウンロードしてください
以下の図は、複数のラウンドの会話の後に測定されたビデオメモリの使用法を示しています。これらはすべて、NVIDIA GeForce RTX 3090マシンでテストされた推論を示しています。 4ビットモデルは、メモリの使用量を効果的に削減できます。
Toucan-16bit
最初の職業
トークン長1024 numビーム= 4;トークンの長さ2048はOOMになります。 
トークン長2048 numビーム= 1; 
Toucan-4bit
最初の職業
トークン長2048 numビーム= 4; 
トークン長2048 numビーム= 1; 
単純なデモを下の図に示します。

ここでのデモは、chatglmの実装を指します。