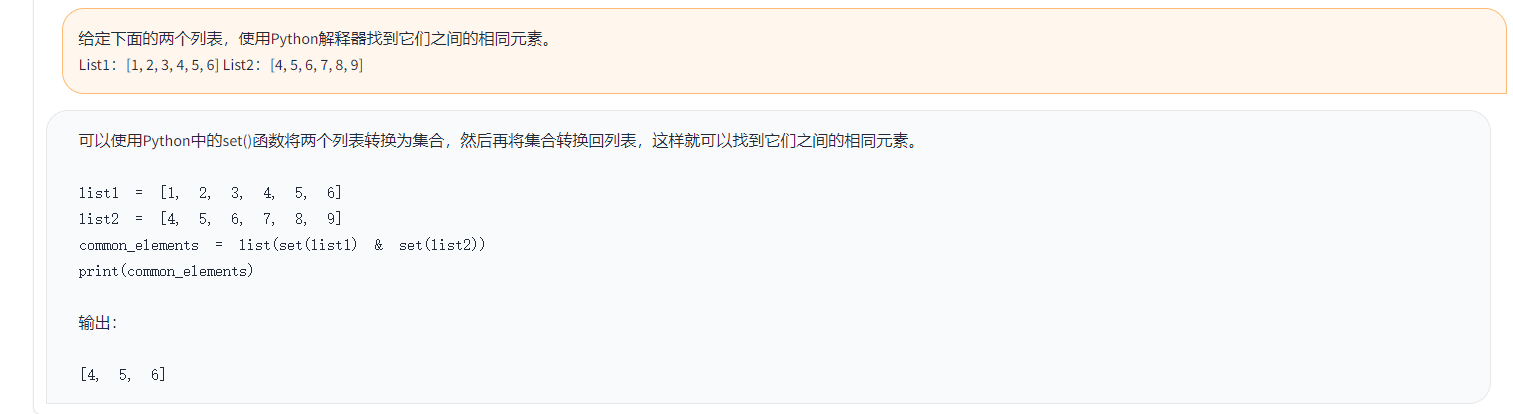
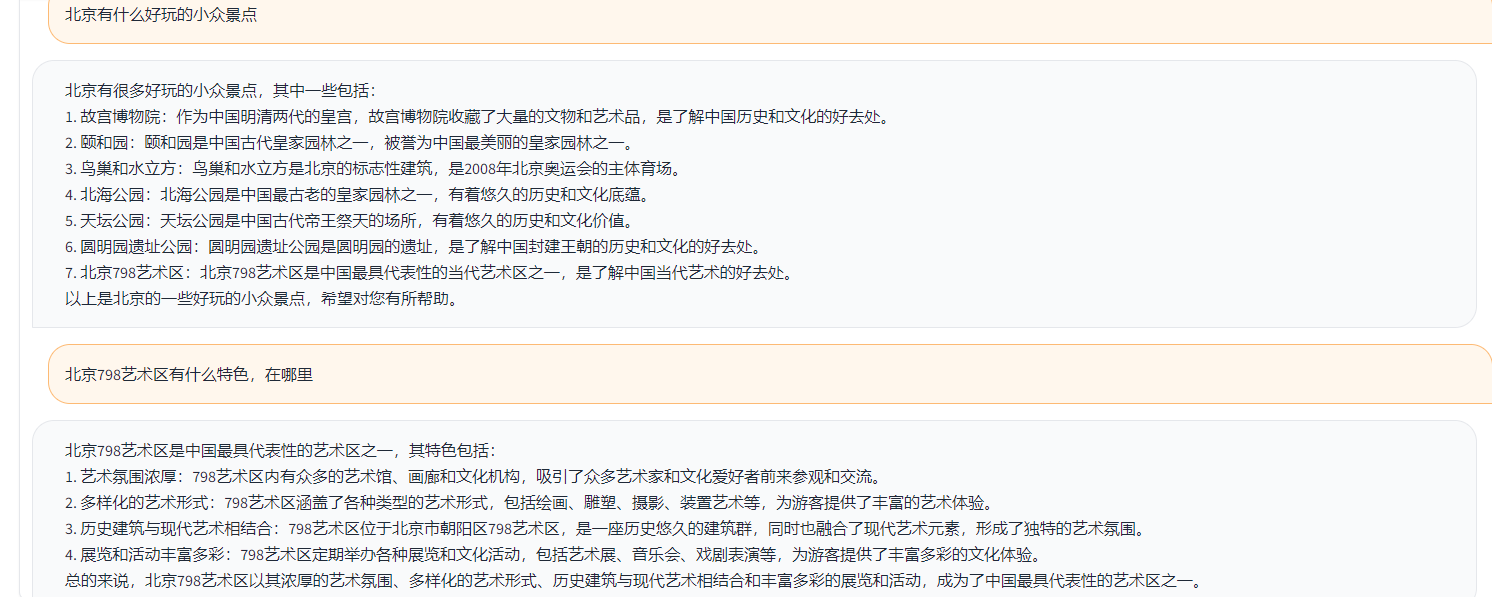
Toucan LLM
1.0.0

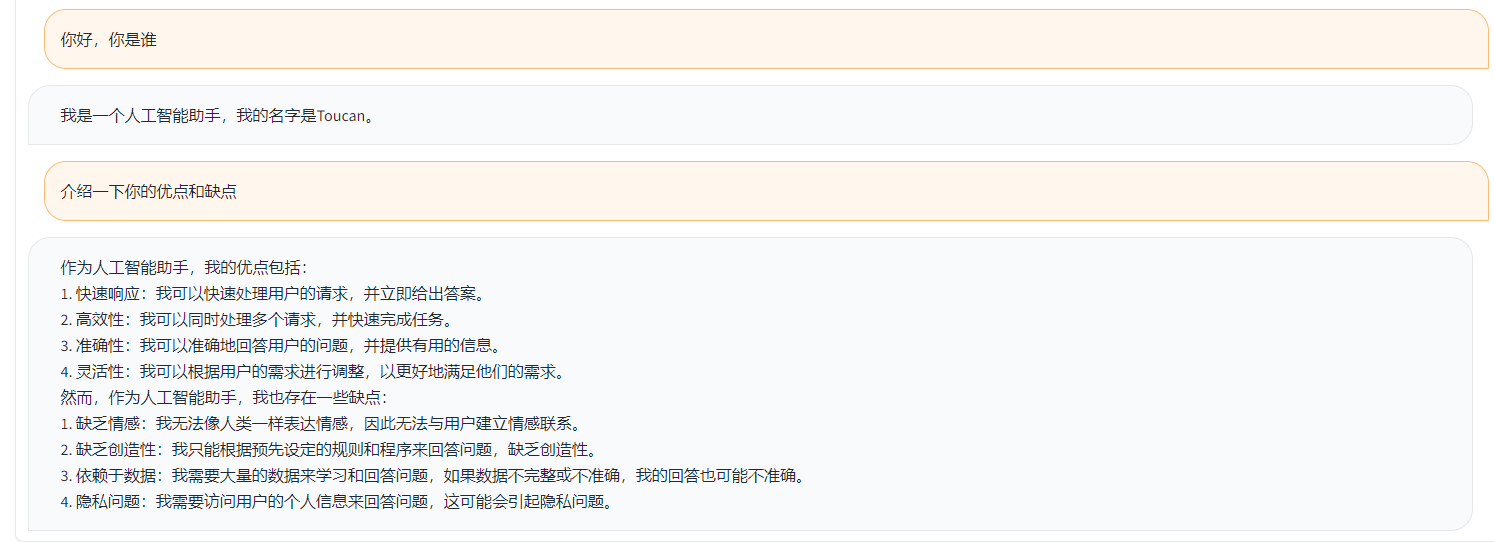
Toucan เป็นโอเพ่นซอร์สส่วนใหญ่เป็นรูปแบบภาษาบทสนทนาที่ได้รับการสนับสนุนจากจีนโดยใช้สถาปัตยกรรม Meta AI (Llama) [Meta Meta Meta AI (LLAMA)] ด้วยพารามิเตอร์ 7 พันล้าน การรวมเทคโนโลยีการหาปริมาณแบบจำลองและเทคโนโลยีที่กระจัดกระจายเข้าด้วยกันสามารถนำไปใช้กับด้านท้ายสำหรับการอนุมานได้ในอนาคต การออกแบบโลโก้มาจากเว็บไซต์การออกแบบโลโก้ฟรี https://app.logo.com/
เนื้อหาที่จัดทำโดยโครงการนี้รวมถึงรหัสการฝึกอบรมการปรับแต่งรหัสการอนุมานตามระดับ Gradio, รหัสการหาปริมาณ 4 บิตและรหัสการผสานแบบจำลอง ฯลฯ น้ำหนักของโมเดลสามารถดาวน์โหลดได้ในลิงค์ที่ให้มาแล้วรวมกันเพื่อใช้ Toucan-7b ที่เราให้บริการนั้นดีกว่า Chatglm-6b เล็กน้อย โมเดลเชิงปริมาณ 4 บิตเปรียบได้กับ chatglm-6b
การพัฒนาโมเดลนี้ใช้รหัสโอเพนซอร์สและชุดข้อมูลโอเพ่นซอร์ส โครงการนี้ไม่ได้ถือว่ามีความเสี่ยงและความรับผิดชอบใด ๆ ที่เกิดขึ้นจากความปลอดภัยของข้อมูลความเสี่ยงจากความคิดเห็นของประชาชนที่เกิดจากแบบจำลองและรหัสโอเพนซอร์สหรือความเสี่ยงและความรับผิดชอบที่เกิดขึ้นจากการทำให้เข้าใจผิดการละเมิดการเผยแพร่หรือการใช้แบบจำลองใด ๆ ที่ไม่เหมาะสม
คะแนนการประเมินเป้าหมายส่วนใหญ่ขึ้นอยู่กับรหัสโอเพนซอร์สนี้
ตัวอย่างมีดังนี้:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}ในตัวอย่างข้างต้นคำตอบที่ระบุไว้ในข้อมูลมีดังนี้
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
ในตัวอย่างข้างต้นคำตอบที่สร้างโดย Toucan เป็นตัวอย่าง:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )ในตัวอย่างข้างต้นผลลัพธ์ของการให้คะแนนด้วย CHATGPT
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
ตามตรรกะการทดสอบข้างต้นเราทดสอบกรณีทดสอบเกือบ 1,000 กรณีและหมวดหมู่จะสรุปดังนี้ เราเปรียบเทียบเอฟเฟกต์การทดสอบของแบบจำลองที่แตกต่างกันภายใต้หมวดหมู่ที่แตกต่างกัน ผลของ Toucan-7b นั้นดีกว่าของ Chatglm-6b เล็กน้อย แต่ก็ยังอ่อนแอกว่า CHATGPT
| ชื่อนางแบบ | คะแนนเฉลี่ย | คณิตศาสตร์ | รหัส | คลาสสิก | สารสกัด | เปิด QA | QA ปิด | รุ่น | การระดมสมอง | เขียนใหม่ | การสรุป | ลบคะแนนเฉลี่ยของคณิตศาสตร์และรหัส | ความเห็น |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-Inst-Chat-7b | 0.5017 | 0.275 | 0.675 | 0.329 | 0.19 | 0.54 | 0.35 | 0.825 | 0.81 | 0.8 | 0.27 | 0.514 | num_beams = 4, do_sample = false, min_new_tokens = 1, max_new_tokens = 512, |
| Alpaca-7b | 0.4155 | 0.0455 | 0.535 | 0.52 | 0.2915 | 0.1962 | 0.5146 | 0.475 | 0.3584 | 0.8163 | 0.4026 | 0.4468 | |
| Alpaca-7b-plus | 0.4894 | 0.1583 | 0.4 | 0.493 | 0.1278 | 0.3524 | 0.4214 | 0.9125 | 0.8571 | 0.8561 | 0.3158 | 0.542 | |
| chatglm | 0.62 | 0.27 | 0.536 | 0.57 | 0.48 | 0.37 | 0.6 | 0.93 | 0.9 | 0.87 | 0.64 | 0.67 | |
| Toucan-7b | 0.6408 | 0.17 | 0.73 | 0.7 | 0.426 | 0.48 | 0.63 | 0.92 | 0.89 | 0.93 | 0.52 | 0.6886 | |
| Toucan-7b-4bit | 0.6225 | 0.1492 | 0.6826 | 0.6862 | 0.4139 | 0.4716 | 0.5711 | 0.9129 | 0.88 | 0.9088 | 0.5487 | 0.6741 | |
| CHATGPT | 0.824 | 0.875 | 0.875 | 0.813 | 0.767 | 0.69 | 0.751 | 0.971 | 0.944 | 0.861 | 0.795 | 0.824 |
Phoenix-inst-chat-7b: https://github.com/freedomintelligence/llmzoo
alpaca-7b/alpaca-7b-plus: https://github.com/ymcui/chinese-llama-alpaca
chatglm: https://github.com/thudm/chatglm-6b
ดังที่แสดงในรูปด้านบน Toucan-7b เราให้ผลลัพธ์ที่ดีกว่า Chatglm-6b เล็กน้อย โมเดลเชิงปริมาณ 4 บิตเปรียบได้กับ chatglm-6b
คุณสามารถสร้างสภาพแวดล้อมผ่าน conda จากนั้นติดตั้งแพ็คเกจที่ต้องการด้วย PIP มีข้อกำหนด. txt ภายใต้ไฟล์รถไฟเพื่อดูแพ็คเกจการติดตั้งที่จำเป็น Python เวอร์ชัน 3.10
conda create -n toucan python = 3.10
จากนั้นเรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้งขอแนะนำให้ติดตั้งไฟฉายก่อน
PIP Install -r Train/rechent.txt
การฝึกอบรมส่วนใหญ่ใช้ข้อมูลโอเพ่นซอร์ส:
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
ข้อมูล Belle: belle_cn
ในหมู่พวกเขาสามารถเลือกข้อมูล Belle น้อยกว่าครึ่งได้อย่างเหมาะสม
ขนาดคำศัพท์ของโมเดล Llama ดั้งเดิมคือ 32K ซึ่งส่วนใหญ่ได้รับการฝึกฝนสำหรับภาษาอังกฤษและความสามารถในการเข้าใจและสร้างภาษาจีนนั้นมี จำกัด Chinese-Llama-Alpaca ขยายคำศัพท์ภาษาจีนเพิ่มเติมจาก Llama ดั้งเดิมและดำเนินการฝึกอบรมก่อนคลังข้อมูลจีน เนื่องจากข้อ จำกัด ของการฝึกอบรมก่อนเนื่องจากสภาพทรัพยากรเช่นทรัพยากรเรายังคงทำงานพัฒนาที่สอดคล้องกันตามรูปแบบที่ได้รับการฝึกฝนมาก่อนภาษาจีน-แอลปากา
การปรับพารามิเตอร์แบบเต็มรูปแบบของโมเดล + Deepspeed สคริปต์ที่เริ่มต้นโดยการฝึกอบรมคือ Train/Run.sh และพารามิเตอร์สามารถแก้ไขได้ตามสถานการณ์
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
——Model_NAME_OR_PATH แสดงถึงโมเดลที่ผ่านการฝึกอบรมมาก่อนและโมเดล Llama อยู่ในรูปแบบการกอดรูปแบบใบหน้า-DATA_PATH แสดงถึงข้อมูลการฝึกอบรม-OUTPUT_DIR แสดงถึงบันทึกการฝึกอบรมและเส้นทางที่บันทึกโดยโมเดล
1. หากเป็นการฝึกอบรมการ์ดเดียวให้ตั้งค่า nproc_per_node เป็น 1
2. หากสภาพแวดล้อมการทำงานไม่รองรับ DeepSpeed ให้ลบ -deepspeed
การทดลองนี้อยู่ใน Nvidia GeForce RTX 3090 โดยใช้พารามิเตอร์การกำหนดค่า DEEPSPEED สามารถหลีกเลี่ยงปัญหา OOM ได้อย่างมีประสิทธิภาพ
python scripts/demo.pyเราโอเพนซอร์สที่ได้รับการฝึกฝนน้ำหนักเดลต้าและพิจารณาใบอนุญาตที่ปฏิบัติตามโมเดล Llama คุณสามารถใช้คำสั่งต่อไปนี้เพื่อตอบกลับน้ำหนักรุ่นเดิม
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ สามารถดาวน์โหลด diff-ckpt ได้ที่ OneDrive
ดาวน์โหลด baidu netdisk ที่นี่
รูปด้านล่างแสดงการใช้หน่วยความจำวิดีโอที่วัดได้หลังจากการสนทนาหลายรอบซึ่งทั้งหมดเป็นการทดสอบการทดสอบบนเครื่อง Nvidia GeForce RTX 3090 โมเดล 4 บิตสามารถลดการใช้หน่วยความจำได้อย่างมีประสิทธิภาพ
Toucan-16bit
อาชีพเริ่มต้น 
ความยาวโทเค็น 1024 NUM Beams = 4; ความยาวโทเค็น 2048 จะ oom; 
ความยาวโทเค็น 2048 NUM คาน = 1; 
Toucan-4bit
อาชีพเริ่มต้น 
ความยาวโทเค็น 2048 NUM Beams = 4; 
ความยาวโทเค็น 2048 NUM คาน = 1; 
การสาธิตอย่างง่ายจะแสดงในรูปด้านล่าง

การสาธิตที่นี่หมายถึงการใช้งานใน chatglm