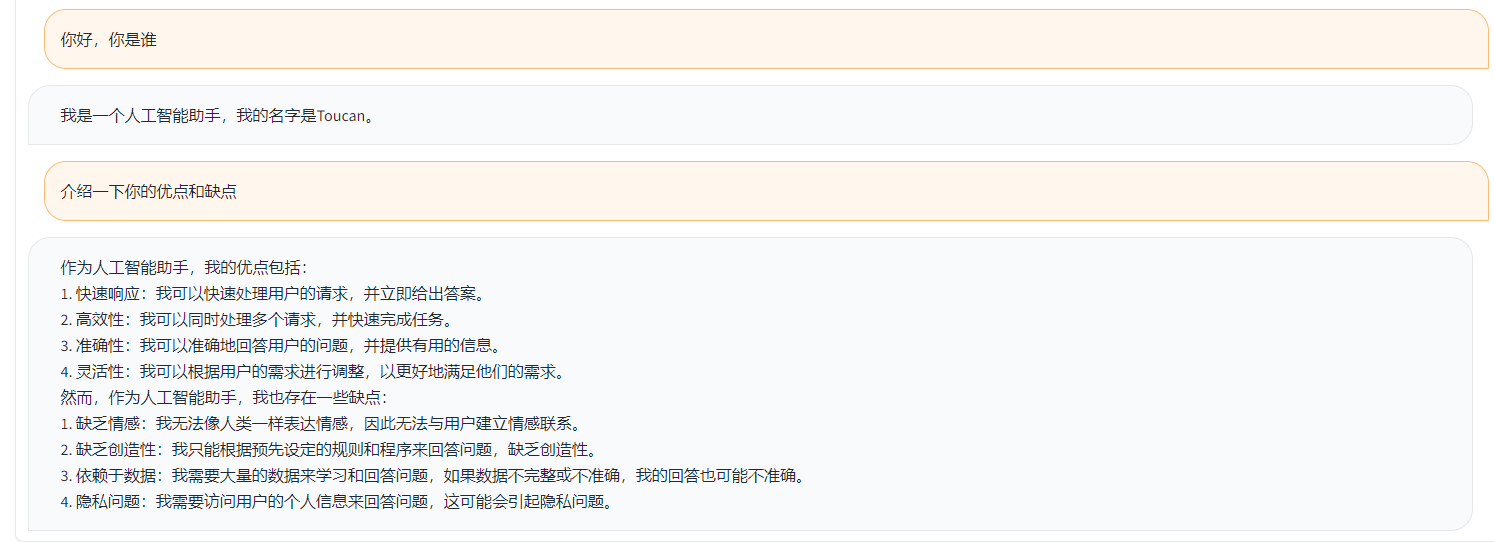
Toucan LLM
1.0.0

Toucan es un modelo de lenguaje de diálogo de código abierto, principalmente con apoyo chino, basado en la arquitectura [modelo de idioma grande de Meta AI (LLAMA)], con 7 mil millones de parámetros. Combinando la tecnología de cuantización del modelo y la tecnología dispersa, se puede implementar en el lado final para la inferencia en el futuro. El diseño del logotipo proviene del sitio web de diseño de logotipo gratuito https://app.logo.com/
El contenido proporcionado por este proyecto incluye el código de capacitación ajustado, el código de inferencia basado en el Grado, el código de cuantización de 4 bits y el código de fusión del modelo, etc. Los pesos del modelo se pueden descargar en el enlace proporcionado y luego combinarse para usar. El Toucan-7B que proporcionamos es un poco mejor que el ChatGlm-6b. El modelo cuantificado de 4 bits es comparable al chatglm-6b.
El desarrollo de este modelo utiliza el código de código abierto y los conjuntos de datos de código abierto. Este proyecto no asume ningún riesgo y responsabilidad que surja de la seguridad de los datos, los riesgos de opinión pública causados por modelos y códigos de código abierto, o los riesgos y responsabilidades derivados de engañosos, abuso, difusión o uso inadecuado de cualquier modelo.
Los puntajes de evaluación objetiva se basan principalmente en este código de código abierto https://github.com/lianjiatech/belle/tree/main/eval
Los ejemplos son los siguientes:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}En el ejemplo anterior, las respuestas anotadas proporcionadas en los datos son las siguientes.
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
En el ejemplo anterior, la respuesta generada por Tucan como ejemplo:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )En el ejemplo anterior, el resultado de la puntuación con chatgpt
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
Según la lógica de prueba anterior, probamos casi 1,000 casos de prueba, y las categorías se resumen de la siguiente manera. Comparamos los efectos de prueba de diferentes modelos en diferentes categorías. El efecto de Toucan-7B es ligeramente mejor que el de ChatGlm-6b, pero aún es más débil que ChatGPT.
| Nombre del modelo | Puntaje promedio | matemáticas | código | Clasificación | extracto | QA abierto | Qa cerrado | Generación | reunión creativa | volver a escribir | Resumen | Eliminar la puntuación promedio de matemáticas y código | Comentario |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-Inst-Chat-7b | 0.5017 | 0.275 | 0.675 | 0.329 | 0.19 | 0.54 | 0.35 | 0.825 | 0.81 | 0.8 | 0.27 | 0.514 | num_beams = 4, do_sample = false, min_new_tokens = 1, max_new_tokens = 512, |
| Alpaca-7b | 0.4155 | 0.0455 | 0.535 | 0.52 | 0.2915 | 0.1962 | 0.5146 | 0.475 | 0.3584 | 0.8163 | 0.4026 | 0.4468 | |
| alpaca-7b-plus | 0.4894 | 0.1583 | 0.4 | 0.493 | 0.1278 | 0.3524 | 0.4214 | 0.9125 | 0.8571 | 0.8561 | 0.3158 | 0.542 | |
| Chatglm | 0.62 | 0.27 | 0.536 | 0.57 | 0.48 | 0.37 | 0.6 | 0.93 | 0.9 | 0.87 | 0.64 | 0.67 | |
| Tucan-7b | 0.6408 | 0.17 | 0.73 | 0.7 | 0.426 | 0.48 | 0.63 | 0.92 | 0.89 | 0.93 | 0.52 | 0.6886 | |
| Tucan-7b-4bit | 0.6225 | 0.1492 | 0.6826 | 0.6862 | 0.4139 | 0.4716 | 0.5711 | 0.9129 | 0.88 | 0.9088 | 0.5487 | 0.6741 | |
| Chatgpt | 0.824 | 0.875 | 0.875 | 0.813 | 0.767 | 0.69 | 0.751 | 0.971 | 0.944 | 0.861 | 0.795 | 0.824 |
Phoenix-Inst-CHAT-7B: https://github.com/freedomintelligence/llmzoo
Alpaca-7b/Alpaca-7b-Plus: https://github.com/ymcui/chinese-llama-alpaca
Chatglm: https://github.com/thudm/chatglm-6b
Como se muestra en la figura anterior, el Toucan-7B proporcionamos resultados ligeramente mejores que el chatglm-6b. El modelo cuantificado de 4 bits es comparable al chatglm-6b.
Puede crear un entorno a través de Conda e instalar los paquetes requeridos por PIP. Existen requisitos.txt en el archivo de tren para ver los paquetes de instalación requeridos, Python versión 3.10
conda create -n toucan python = 3.10
Luego ejecute el siguiente comando para instalar, se recomienda instalar la antorcha primero
PIP Install -r Train/Requisitos.txt
La capacitación utiliza principalmente datos de código abierto:
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
Datos de Belle: belle_cn
Entre ellos, menos de la mitad de los datos de Belle se pueden seleccionar adecuadamente.
El tamaño del vocabulario del modelo de llama original es de 32k, que está principalmente entrenado para inglés, y la capacidad de comprender y generar chino es limitada. China-Llama-Alpaca amplió aún más el vocabulario chino basado en la llama original y realizó un pretraben en el corpus chino. Debido a las limitaciones de la capacitación previa debido a las condiciones de recursos como los recursos, continuamos realizando el trabajo de desarrollo correspondiente basado en el modelo pre-capacitado chino-llama-alpaca.
El parámetro completo ajustado del modelo + velocidad profunda, el script iniciado por la capacitación es trenes/run.sh, y los parámetros pueden modificarse de acuerdo con la situación.
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
--Model_name_or_path representa el modelo previamente capacitado, y el modelo de LLAMA está en formato de cara abrazada: Data_Path representa los datos de entrenamiento: output_dir representa el registro de entrenamiento y el camino guardado por el modelo
1. Si se trata de entrenamiento de una sola tarjeta, configure nproc_per_node en 1
2. Si el entorno en ejecución no es compatible
Este experimento se encuentra en Nvidia GeForce RTX 3090, el uso de parámetros de configuración de velocidad profunda puede evitar efectivamente problemas de OOM.
python scripts/demo.pyAbrimos pesas delta capacitadas en código y consideramos licencias que se adhieren a los modelos de llamas. Puede usar el siguiente comando para responder a los pesos del modelo original.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ Diff-CKPT se puede descargar aquí en OneDrive
Descargar Baidu NetDisk aquí
La siguiente figura muestra el uso de la memoria de video medido después de múltiples rondas de conversaciones, todas las cuales fueron inferencias probadas en la máquina Nvidia GeForce RTX 3090. El modelo de 4 bits puede reducir efectivamente el uso de la memoria.
tucan-16bit
Ocupación inicial 
Longitud del token 1024 NUM Vigas = 4; Longitud del token 2048 Will Oom; 
longitud del token 2048 NUM Vigas = 1; 
tucan-4bit
Ocupación inicial 
Longitud del token 2048 NUM Vigas = 4; 
longitud del token 2048 NUM Vigas = 1; 
Una demostración simple se muestra en la figura a continuación.

La demostración aquí se refiere a la implementación en ChatGlm.