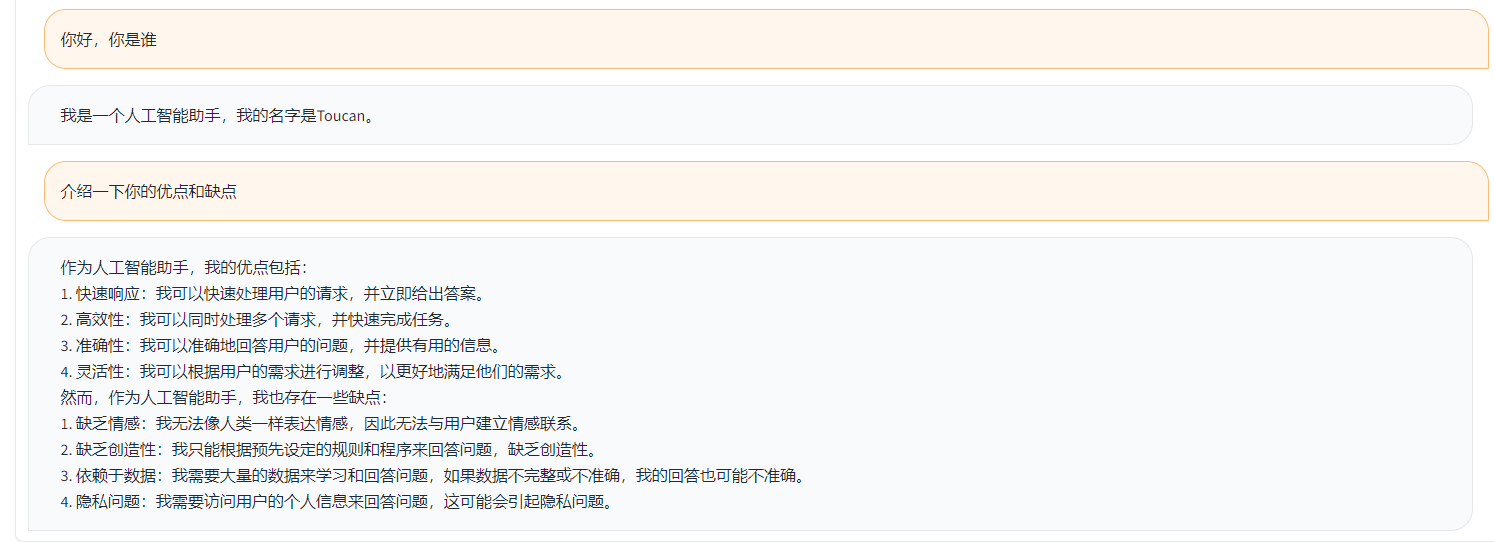
Toucan LLM
1.0.0

Toucan هو نموذج لغة حوار مفتوح المصدر ، لا سيما النموذج الذي يدعمه الصينيين يعتمد على بنية [Meta Model Model Meta AI (Llama)] ، مع 7 مليارات من المعلمات. الجمع بين تقنية قياس الكميات النموذجية والتكنولوجيا المتفرقة ، يمكن نشرها على الجانب النهائي للاستدلال في المستقبل. يأتي تصميم الشعار من موقع تصميم الشعار المجاني https://app.logo.com/
يتضمن المحتوى الذي يوفره هذا المشروع رمز التدريب بشكل جيد ، ورمز الاستدلال القائم على الخريجين ، ورمز قياس كمية 4Bit ورمز دمج النماذج ، وما إلى ذلك. يمكن تنزيل أوزان النموذج في الرابط المقدم ثم تم دمجه للاستخدام. Toucan-7b الذي نقدمه أفضل قليلاً من ChatGlm-6b. النموذج الكمي المكون من 4 بت قابلة للمقارنة مع ChatGLM-6B.
يستخدم تطوير هذا النموذج رمز المصدر المفتوح ومجموعات بيانات المصدر المفتوحة. لا يتحمل هذا المشروع أي مخاطر ومسؤوليات ناشئة عن أمن البيانات ، ومخاطر الرأي العام الناجم عن نماذج ورموز المصدر المفتوح ، أو المخاطر والمسؤوليات الناشئة عن مضللة أو سوء المعاملة أو النشر أو الاستخدام غير المناسب لأي نموذج.
تعتمد درجات التقييم الموضوعي بشكل أساسي على رمز المصدر المفتوح هذا https://github.com/lianjiatech/belle/tree/main/eval
الأمثلة على النحو التالي:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}في المثال أعلاه ، تكون الإجابات المشروحة المقدمة في البيانات كما يلي.
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
في المثال أعلاه ، الإجابة التي تم إنشاؤها بواسطة Toucan كمثال:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )في المثال أعلاه ، نتيجة التسجيل مع chatgpt
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
وفقًا لمنطق الاختبار أعلاه ، قمنا باختبار ما يقرب من 1000 حالة اختبار ، ويتم تلخيص الفئات على النحو التالي. قارنا تأثيرات اختبار النماذج المختلفة تحت فئات مختلفة. تأثير Toucan-7B أفضل قليلاً من تأثير ChatGlm-6B ، لكنه لا يزال أضعف من ChatGPT.
| اسم النموذج | متوسط النتيجة | الرياضيات | شفرة | الفراغ المصنوع | يستخرج | افتح ض QA | مغلق QA | جيل | العصف الذهني | أعد كتابة | تلخيص | إزالة متوسط درجة الرياضيات والرمز | تعليقات |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-inst-Chat-7b | 0.5017 | 0.275 | 0.675 | 0.329 | 0.19 | 0.54 | 0.35 | 0.825 | 0.81 | 0.8 | 0.27 | 0.514 | num_beams = 4 ، do_sample = false ، min_new_tokens = 1 ، max_new_tokens = 512 ، |
| الألبكة-7 ب | 0.4155 | 0.0455 | 0.535 | 0.52 | 0.2915 | 0.1962 | 0.5146 | 0.475 | 0.3584 | 0.8163 | 0.4026 | 0.4468 | |
| الألباكا -7 ب زائد | 0.4894 | 0.1583 | 0.4 | 0.493 | 0.1278 | 0.3524 | 0.4214 | 0.9125 | 0.8571 | 0.8561 | 0.3158 | 0.542 | |
| ChatGlm | 0.62 | 0.27 | 0.536 | 0.57 | 0.48 | 0.37 | 0.6 | 0.93 | 0.9 | 0.87 | 0.64 | 0.67 | |
| طولكان -7 ب | 0.6408 | 0.17 | 0.73 | 0.7 | 0.426 | 0.48 | 0.63 | 0.92 | 0.89 | 0.93 | 0.52 | 0.6886 | |
| Toucan-7b-4bit | 0.6225 | 0.1492 | 0.6826 | 0.6862 | 0.4139 | 0.4716 | 0.5711 | 0.9129 | 0.88 | 0.9088 | 0.5487 | 0.6741 | |
| chatgpt | 0.824 | 0.875 | 0.875 | 0.813 | 0.767 | 0.69 | 0.751 | 0.971 | 0.944 | 0.861 | 0.795 | 0.824 |
Phoenix-inst-chat-7b: https://github.com/freedomintelligence/llmzoo
alpaca-7b/alpaca-7b-plus: https://github.com/ymcui/Chinese-llama-alpaca
ChatGlm: https://github.com/thudm/chatglm-6b
كما هو موضح في الشكل أعلاه ، فإن Toucan-7b نقدم نتائج أفضل قليلاً من ChatGlm-6b. النموذج الكمي المكون من 4 بت قابلة للمقارنة مع ChatGLM-6B.
يمكنك إنشاء بيئة من خلال كوندا ثم تثبيت الحزم المطلوبة بواسطة PIP. هناك متطلبات. txt أسفل ملف القطار لعرض حزم التثبيت المطلوبة ، Python الإصدار 3.10
كوندا إنشاء -n toucan python = 3.10
ثم قم بتنفيذ الأمر التالي للتثبيت ، يوصى بتثبيت الشعلة أولاً
PIP تثبيت -R القطار/المتطلبات
يستخدم التدريب بشكل أساسي بيانات المصدر المفتوح:
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
بيانات الحسناء: belle_cn
من بينها ، يمكن اختيار أقل من نصف بيانات الحسناء بشكل مناسب.
حجم المفردات لنموذج LLAMA الأصلي هو 32 كيلو بايت ، وهو مدرب بشكل أساسي للغة الإنجليزية ، والقدرة على فهم الصينية وتوليدها محدودة. وسعت الصينية لاما ألباكا المفردات الصينية بناءً على اللاما الأصلية وأجرى التدريب المسبق على المجموعة الصينية. نظرًا لقيود التدريب المسبق بسبب شروط الموارد مثل المورد ، واصلنا القيام بأعمال التطوير المقابلة بناءً على النموذج الصيني-بلباكا مسبقًا.
المعلمة الكاملة لضبط النموذج + Spedspeed ، البرنامج النصي الذي بدأه التدريب هو Train/Run.sh ، ويمكن تعديل المعلمات وفقًا للموقف.
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
—— Model_name_or_path يمثل النموذج الذي تم تدريبه مسبقًا ، ويمثل نموذج LLAMA تنسيق الوجه-DATA_PATH يمثل بيانات التدريب-يمثل Output_dir سجل التدريب والمسار المحفوظ بواسطة النموذج
1. إذا كان تدريب البطاقة الفردي ، فقم بتعيين nproc_per_node على 1
2. إذا كانت البيئة الجارية لا تدعم السرعة العميقة ، فزلها -مسبقة عميقة
هذه التجربة في Nvidia Geforce RTX 3090 ، باستخدام معلمات تكوين DeepSpeed يمكن أن تجنب بشكل فعال مشاكل OOM.
python scripts/demo.pyنحن مفتوح المصادر الأوزان دلتا ، وننظر في التراخيص التي تلتزم بنماذج لاما. يمكنك استخدام الأمر التالي للرد على أوزان النموذج الأصلي.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ يمكن تنزيل Diff-Ckpt هنا على OneDrive
قم بتنزيل Baidu NetDisk هنا
يوضح الشكل أدناه استخدام ذاكرة الفيديو المقاسة بعد جولات متعددة من المحادثات ، وكلها تم اختبارها على جهاز Nvidia Geforce RTX 3090. يمكن أن يقلل نموذج 4Bit بشكل فعال من استخدام الذاكرة.
طولكان -16 بت
المهنة الأولية 
طول الرمز 1024 NUM BEATS = 4 ؛ الرمز المميز 2048 سوف OOM. 
طول الرمز المميز 2048 NUM BEATS = 1 ؛ 
طولكان-4 بايت
المهنة الأولية 
طول الرمز المميز 2048 NUM BEATS = 4 ؛ 
طول الرمز المميز 2048 NUM BEATS = 1 ؛ 
يظهر العرض التوضيحي البسيط في الشكل أدناه.

يشير العرض التوضيحي هنا إلى التنفيذ في ChatGlm.