Toucan LLM
1.0.0

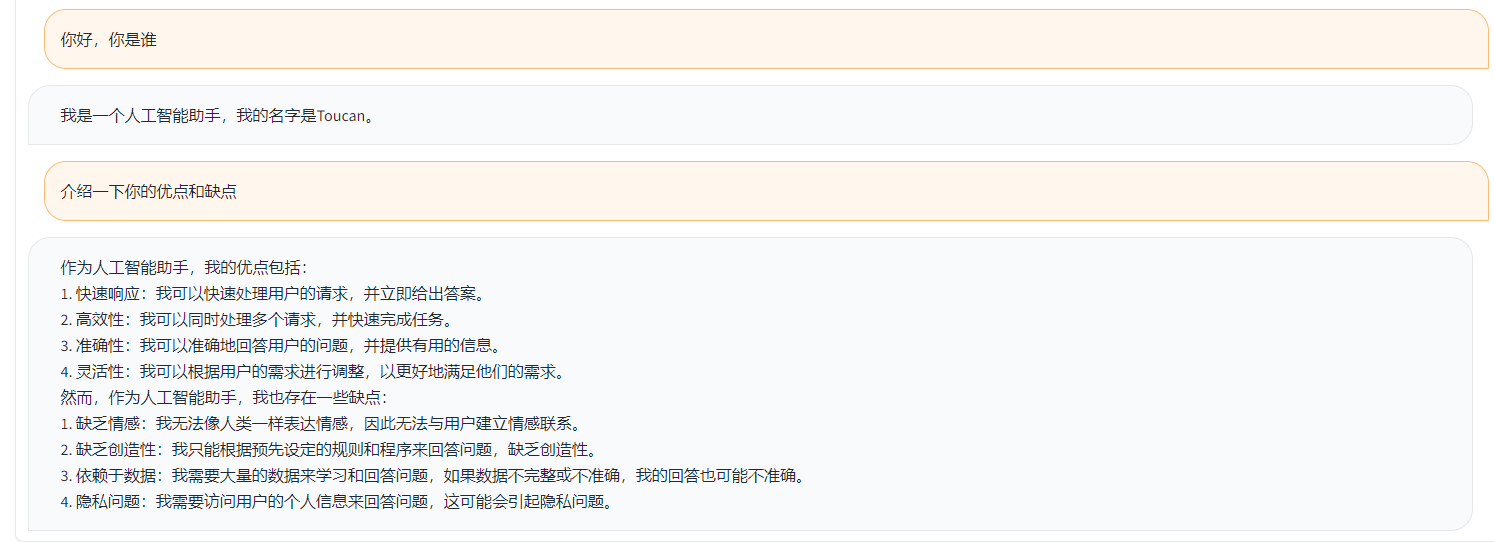
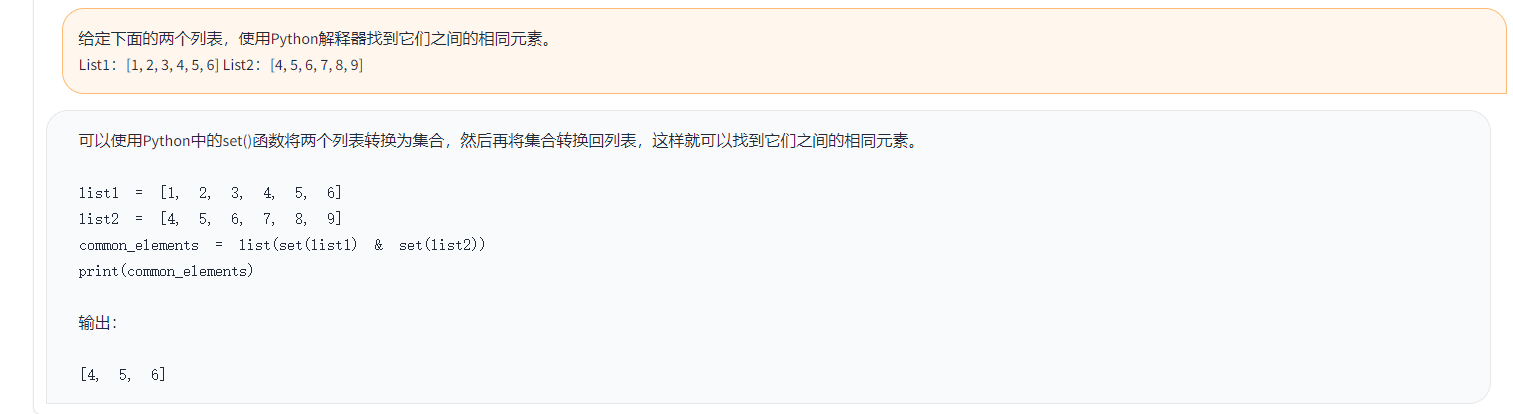
Toucan ist eine Open Source, hauptsächlich chinesisch unterstütztes Dialogsprachmodell, das auf der Architektur [Meta AI AI AI) des [Meta-META) mit 7 Milliarden Parametern basiert. Kombiniert die Modellquantisierungstechnologie und die spärliche Technologie und kann in Zukunft endgültig für die Inferenz eingesetzt werden. Das Design des Logos stammt von der kostenlosen Logo -Design -Website https://app.logo.com/
Der von diesem Projekt bereitgestellte Inhalt umfasst Feinabstimmungscode, Gradio-basierter Inferenzcode, 4-Bit-Quantisierungscode und Modellverführungscode usw. Die Gewichte des Modells können in den bereitgestellten Link heruntergeladen und dann kombiniert werden, um sie zu verwenden. Der von uns bereitgestellte Toucan-7b ist etwas besser als der Chatglm-6b. Das 4-Bit-quantifizierte Modell ist vergleichbar mit dem Chatglm-6b.
Die Entwicklung dieses Modells verwendet Open -Source -Code und Open -Source -Datensätze. In diesem Projekt werden keine Risiken und Verantwortlichkeiten angenommen, die sich aus Datensicherheit, öffentlichen Meinungsrisiken ergeben, die durch Open -Source -Modelle und -Codes verursacht werden, oder die Risiken und Verantwortlichkeiten, die sich aus irreführendem Missbrauch, Missbrauch, Verbreitung oder unsachgemäßer Verwendung eines Modells ergeben.
Die objektiven Bewertungsbewertungen basieren hauptsächlich auf diesem Open -Source -Code https://github.com/lianjiatech/belle/tree/main/eval
Beispiele sind wie folgt:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}Im obigen Beispiel sind die in den Daten angegebenen kommentierten Antworten wie folgt.
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
Im obigen Beispiel hat die von Toucan als Beispiel erzeugte Antwort:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )Im obigen Beispiel das Ergebnis der Bewertung mit ChatGPT
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
Nach der obigen Testlogik haben wir fast 1.000 Testfälle getestet, und die Kategorien werden wie folgt zusammengefasst. Wir haben die Testerffekte verschiedener Modelle unter verschiedenen Kategorien verglichen. Der Effekt von Toucan-7b ist etwas besser als der von Chatglm-6b, aber immer noch schwächer als Chatgpt.
| Modellname | Durchschnittliche Punktzahl | Mathe | Code | Klassifizierung | Extrakt | Offene QA | geschlossene QA | Generation | Brainstorming | umschreiben | Zusammenfassung | Entfernen Sie die durchschnittliche Punktzahl von Mathematik und Code | Kommentare |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-in-Chat-7b | 0,5017 | 0,275 | 0,675 | 0,329 | 0,19 | 0,54 | 0,35 | 0,825 | 0,81 | 0,8 | 0,27 | 0,514 | num_beams = 4, do_sample = false, min_new_tokens = 1, max_new_tokens = 512, |
| Alpaca-7b | 0,4155 | 0,0455 | 0,535 | 0,52 | 0,2915 | 0,1962 | 0,5146 | 0,475 | 0,3584 | 0,8163 | 0,4026 | 0,4468 | |
| ALPACA-7B-PLUS | 0,4894 | 0,1583 | 0,4 | 0,493 | 0,1278 | 0,3524 | 0,4214 | 0,9125 | 0,8571 | 0,8561 | 0,3158 | 0,542 | |
| Chatglm | 0,62 | 0,27 | 0,536 | 0,57 | 0,48 | 0,37 | 0,6 | 0,93 | 0,9 | 0,87 | 0,64 | 0,67 | |
| Toucan-7b | 0,6408 | 0,17 | 0,73 | 0,7 | 0,426 | 0,48 | 0,63 | 0,92 | 0,89 | 0,93 | 0,52 | 0,6886 | |
| Toucan-7b-4bit | 0,6225 | 0,1492 | 0,6826 | 0,6862 | 0,4139 | 0,4716 | 0,5711 | 0,9129 | 0,88 | 0,9088 | 0,5487 | 0,6741 | |
| Chatgpt | 0,824 | 0,875 | 0,875 | 0,813 | 0,767 | 0,69 | 0,751 | 0,971 | 0,944 | 0,861 | 0,795 | 0,824 |
Phoenix-Inst-Chat-7b: https://github.com/freedomintelligence/llmzoo
ALPACA-7B/ALPACA-7B-PLUS: https://github.com/ymcui/chinese-lama-alpaca
Chatglm: https://github.com/thudm/chatglm-6b
Wie in der obigen Abbildung gezeigt, liefern wir die toucan-7b etwas bessere Ergebnisse als der Chatglm-6b. Das 4-Bit-quantifizierte Modell ist vergleichbar mit dem Chatglm-6b.
Sie können eine Umgebung über Conda erstellen und dann die erforderlichen Pakete per PIP installieren. Unter der Zugdatei gibt es Anforderungen.txt, um die erforderlichen Installationspakete anzuzeigen, Python Version 3.10
conda erstellen -n toucan python = 3.10
Führen Sie dann den folgenden Befehl aus, um zu installieren. Es wird empfohlen, zuerst Torch zu installieren
PIP Installation -r -Zug/Anforderungen.txt
Das Training verwendet hauptsächlich Open Source -Daten:
ALPACA_GPT4_DATA.JSON
ALPACA_GPT4_DATA_ZH.JSON
Belle Data: Belle_cn
Unter ihnen kann weniger als die Hälfte der Belle -Daten angemessen ausgewählt werden.
Die Wortschatzgröße des ursprünglichen Lama -Modells beträgt 32K, das hauptsächlich für Englisch ausgebildet ist, und die Fähigkeit, Chinesisch zu verstehen und zu erzeugen, ist begrenzt. Chinesisch-Llama-Alpaca erweiterte das chinesische Vokabular weiter auf der Grundlage des ursprünglichen Lama und führte vor dem chinesischen Korpus vor dem Training durch. Aufgrund der Einschränkungen der Vorausbildung aufgrund von Ressourcenbedingungen wie Ressourcen haben wir weiterhin entsprechende Entwicklungsarbeiten auf der Grundlage des vorgeborenen chinesisch-llama-alpaca-Modells durchgeführt.
Die vollständige Parameterfeineinstellung des Modells + DeepSPeed, das vom Training gestartete Skript ist train/run.sh und die Parameter können gemäß der Situation geändert werden.
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
——Model_name_or_path repräsentiert das vorgebildete Modell, und das Lama-Modell befindet
1. Wenn es sich um ein Kartentraining handelt, setzen Sie NPROC_PER_NODE auf 1
2. Wenn die laufende Umgebung Deepspeed nicht unterstützt, entfernen Sie -Deepspeed
Dieses Experiment befindet sich in NVIDIA GEForce RTX 3090, wobei die Verwendung von DeepSpeed -Konfigurationsparametern OOM -Probleme effektiv vermeiden kann.
python scripts/demo.pyWir haben Delta -Gewichte ausgebildet und in Betracht gezogen, dass Lizenzen an Lama -Modelle haften. Sie können den folgenden Befehl verwenden, um auf die ursprünglichen Modellgewichte zu antworten.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ Diff-CKPT kann hier unter OneDrive heruntergeladen werden
Laden Sie Baidu NetDisk hier herunter
Die folgende Abbildung zeigt die nach mehreren Konversationen gemessene Videospeicherverwendung, die alle auf der NVIDIA GEForce RTX 3090 -Maschine getestet wurden. Das 4 -Bit -Modell kann die Speicherverwendung effektiv reduzieren.
Toucan-16bit
Anfänglicher Beruf 
Tokenlänge 1024 Numstrahlen = 4; Tokenlänge 2048 wird oom; 
Tokenlänge 2048 Numstrahlen = 1; 
Toucan-4bit
Anfänglicher Beruf 
Tokenlänge 2048 Numstrahlen = 4; 
Tokenlänge 2048 Numstrahlen = 1; 
Eine einfache Demo ist in der Abbildung unten dargestellt.

Demo bezieht sich hier auf die Implementierung in Chatglm.