Toucan LLM
1.0.0

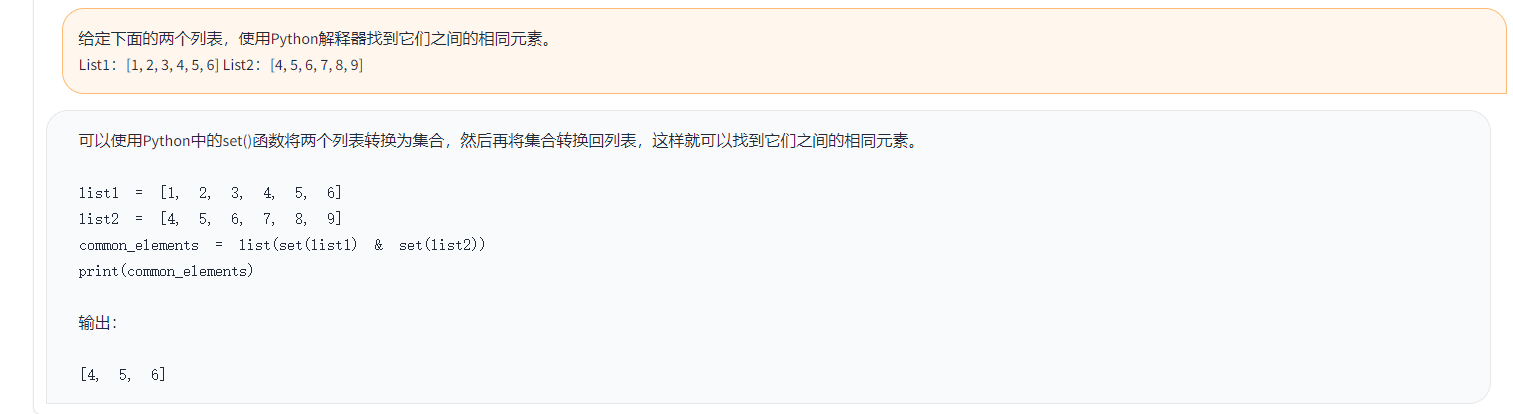
Toucan является открытым исходным кодом, в основном поддерживаемой китайской языком языка диалога, основанной на архитектуре [Meta Meta Meta Ai (Llama)] [Llama)] с 7 миллиардами параметров. Объединяя технологию квантования модели и редкие технологии, ее можно развернуть на конечной стороне для вывода в будущем. Дизайн логотипа поступает с бесплатного веб -сайта Logo Design https://app.logo.com/
Контент, предоставленный этим проектом, включает в себя код обучения с тонкой настройкой, код вывода на основе Gradio, код квантования 4-бит и код слияния модели и т. Д. Вес модели можно загрузить в предоставленной ссылке, а затем объединен для использования. Toucan-7b, который мы предоставляем, немного лучше, чем чатглм-6b. 4-битная количественная модель сопоставима с ChatGLM-6B.
Разработка этой модели использует открытый исходный код и наборы данных с открытым исходным кодом. Этот проект не предполагает никаких рисков и обязанностей, возникающих в результате безопасности данных, рисков общественного мнения, вызванных моделями и кодами с открытым исходным кодом, или рисков и обязанностей, возникающих в результате вводящих в заблуждение, злоупотреблений, распространения или ненадлежащего использования любой модели.
Объективные оценки оценки в основном основаны на этом открытом исходном коде https://github.com/lianjiatech/belle/tree/main/eval
Примеры следующие:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}В приведенном выше примере аннотированные ответы, представленные в данных, следующие.
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
В приведенном выше примере ответ, сгенерированный Toucan в качестве примера:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )В приведенном выше примере результат забивания с помощью CHATGPT
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
Согласно вышеуказанной логике теста, мы проверили почти 1000 тестовых случаев, и категории суммируются следующим образом. Мы сравнили тестовые эффекты различных моделей в разных категориях. Эффект Toucan-7B немного лучше, чем в Chatglm-6B, но все еще слабее, чем CHATGPT.
| Название модели | Средний балл | математика | код | Классификация | извлекать | Открытый ка | Закрытый QA | Поколение | мозговой штурм | переписать | Суммирование | Удалить средний балл по математике и коду | Комментарии |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-Inst-Chat-7b | 0,5017 | 0,275 | 0,675 | 0,329 | 0,19 | 0,54 | 0,35 | 0,825 | 0,81 | 0,8 | 0,27 | 0,514 | num_beams = 4, do_sample = false, min_new_tokens = 1, max_new_tokens = 512, |
| альпака-7B | 0,4155 | 0,0455 | 0,535 | 0,52 | 0,2915 | 0,1962 | 0,5146 | 0,475 | 0,3584 | 0,8163 | 0,4026 | 0,4468 | |
| Alpaca-7b-плюс | 0,4894 | 0,1583 | 0,4 | 0,493 | 0,1278 | 0,3524 | 0,4214 | 0,9125 | 0,8571 | 0,8561 | 0,3158 | 0,542 | |
| Чатглм | 0,62 | 0,27 | 0,536 | 0,57 | 0,48 | 0,37 | 0,6 | 0,93 | 0,9 | 0,87 | 0,64 | 0,67 | |
| Toucan-7b | 0,6408 | 0,17 | 0,73 | 0,7 | 0,426 | 0,48 | 0,63 | 0,92 | 0,89 | 0,93 | 0,52 | 0,6886 | |
| TOUCAN-7B-4BIT | 0,6225 | 0,1492 | 0,6826 | 0,6862 | 0,4139 | 0,4716 | 0,5711 | 0,9129 | 0,88 | 0,9088 | 0,5487 | 0,6741 | |
| Чатгпт | 0,824 | 0,875 | 0,875 | 0,813 | 0,767 | 0,69 | 0,751 | 0,971 | 0,944 | 0,861 | 0,795 | 0,824 |
Phoenix-inst-chat-7b: https://github.com/freedomintelligence/llmzoo
Alpaca-7b/alpaca-7b-plus: https://github.com/ymcui/chinese-lama-alpaca
Чатглм: https://github.com/thudm/chatglm-6b
Как показано на рисунке выше, TOUCAN-7B мы даем немного лучшие результаты, чем ChatGLM-6B. 4-битная количественная модель сопоставима с ChatGLM-6B.
Вы можете создать среду через Conda, а затем установить необходимые пакеты на PIP. Существуют требования .txt под файлом поезда для просмотра необходимых пакетов установки, Python версия 3.10
conda create -n toucan python = 3.10
Затем выполните следующую команду для установки, рекомендуется сначала установить факел
PIP установка -R Train/Teals.txt
Обучение в основном использует данные с открытым исходным кодом:
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
Данные Belle: Belle_cn
Среди них менее половины данных Belle могут быть соответствующим образом выбраны.
Размер словарного запаса оригинальной модели ламы составляет 32K, которая в основном обучена английскому языку, а способность понимать и генерировать китайский язык ограничена. Китайская лама-альпака также расширила китайский словарный запас, основанный на оригинальной ламе и выполнил предварительное обучение в китайском корпусе. Из-за ограничений предварительного обучения из-за таких условий ресурсов, как ресурс, мы продолжали выполнять соответствующие работы по разработке, основанные на предварительно обученной модели Китая-лама-альпака.
Полный параметр точной настройки модели + Deepspeed, сценарий, запущенный обучением,-это Train/run.sh, и параметры могут быть изменены в соответствии с ситуацией.
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
—— model_name_or_path представляет предварительно обученную модель, а модель Llama находится в формате обнимающего лица-data_path представляет данные обучающих
1. Если это тренировка с одной картой, установите NPROC_PER_NODE на 1
2. Если среда бега не поддерживает DeepSpeed, удалите -Deepspeed
Этот эксперимент проходит в NVIDIA GeForce RTX 3090, с использованием параметров конфигурации DeepSpeed может эффективно избежать проблем OOM.
python scripts/demo.pyМы обучали веса дельты с открытым исходным кодом и рассмотрим лицензии, которые придерживаются моделей LLAMA. Вы можете использовать следующую команду, чтобы ответить на исходные веса модели.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ Diff-CKPT можно загрузить здесь на OneDrive
Скачать Baidu netdisk здесь
На рисунке ниже показано использование видео памяти, измеренное после нескольких раундов разговоров, и все они были проверены на машине NVIDIA GeForce RTX 3090. 4 -битная модель может эффективно снизить использование памяти.
TOUCAN-16BIT
Начальное занятие 
Длина токена 1024 Num Beams = 4; Длина токена 2048 будет 
Длина токена 2048 Num Beams = 1; 
Toucan-4bit
Начальное занятие 
Длина токена 2048 Num Beams = 4; 
Длина токена 2048 Num Beams = 1; 
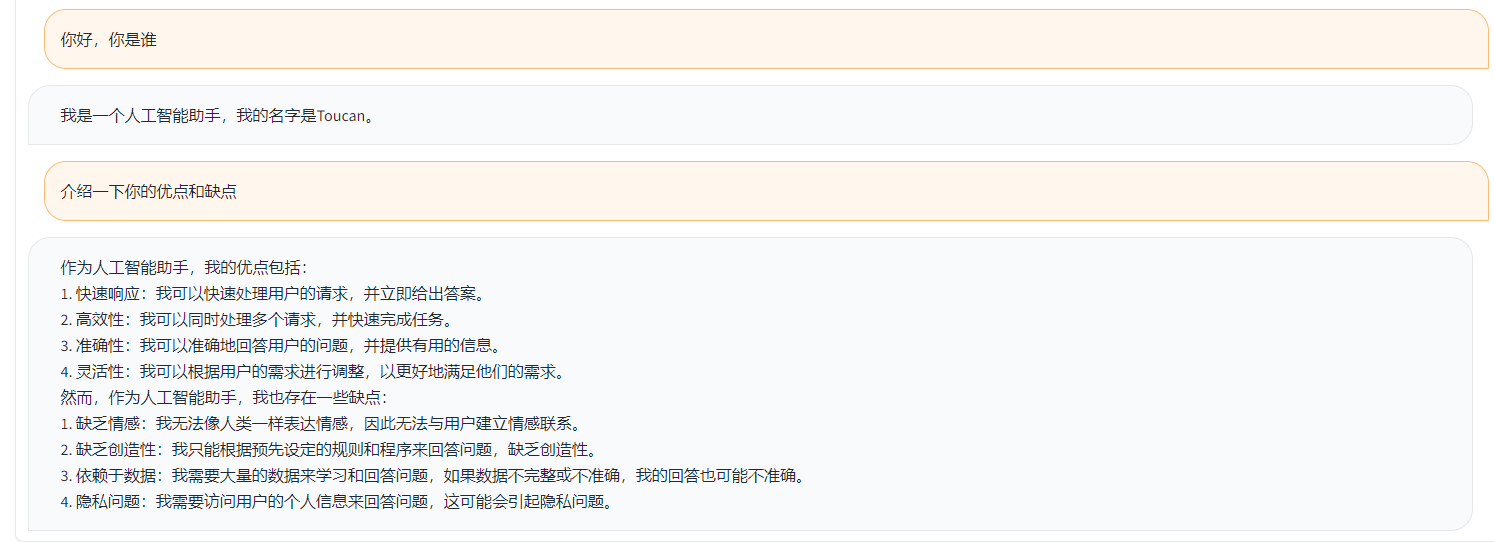
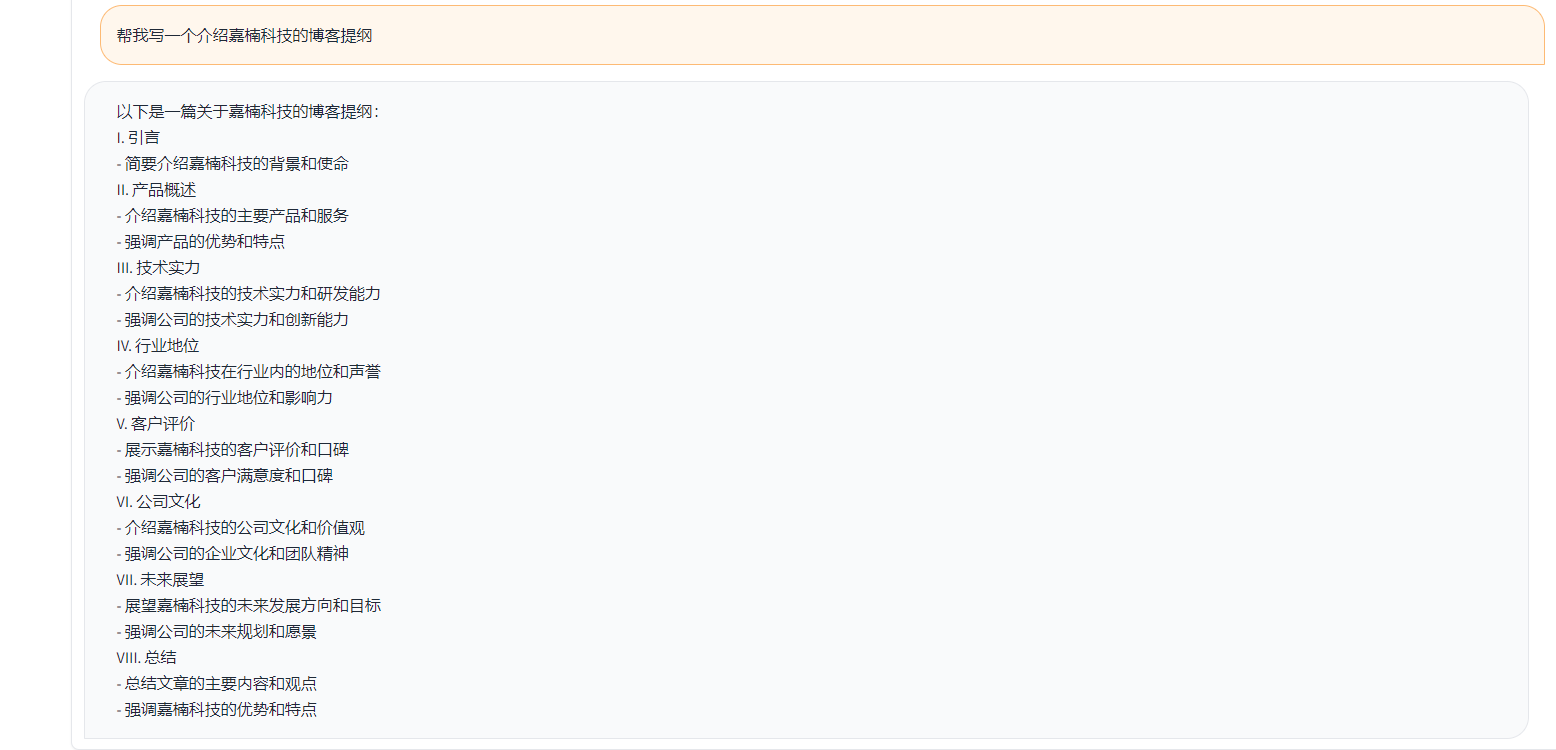
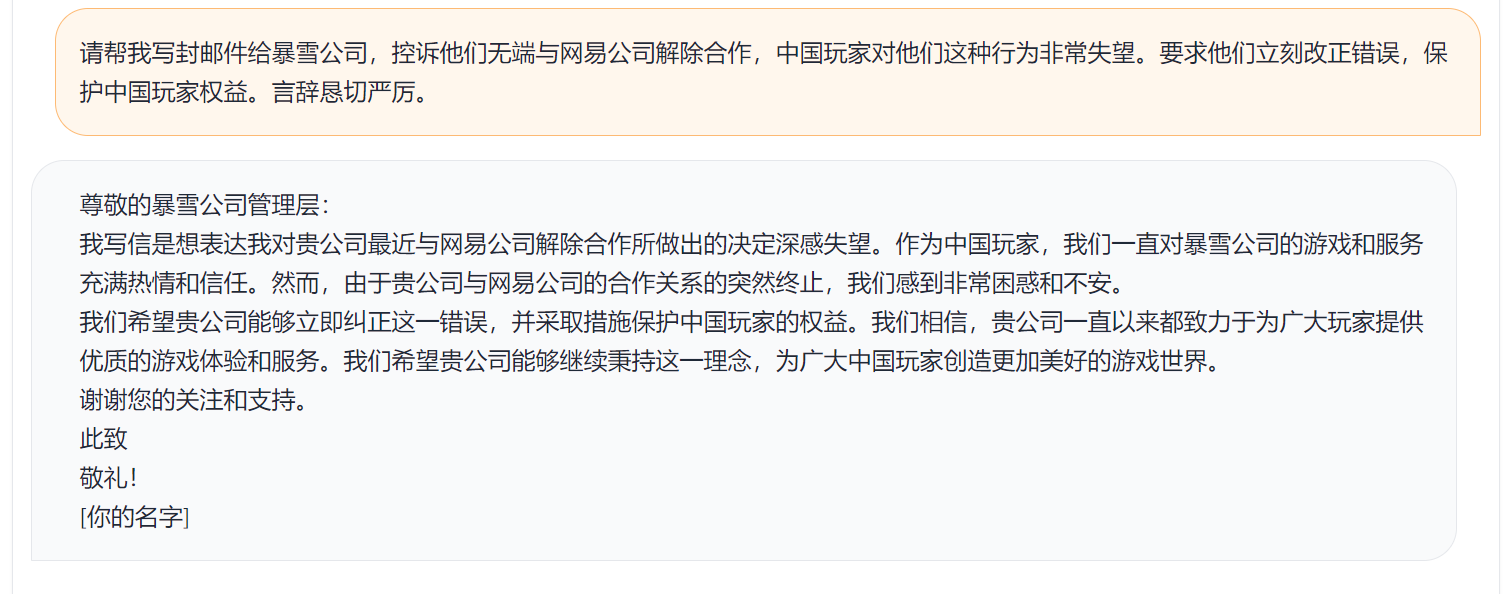
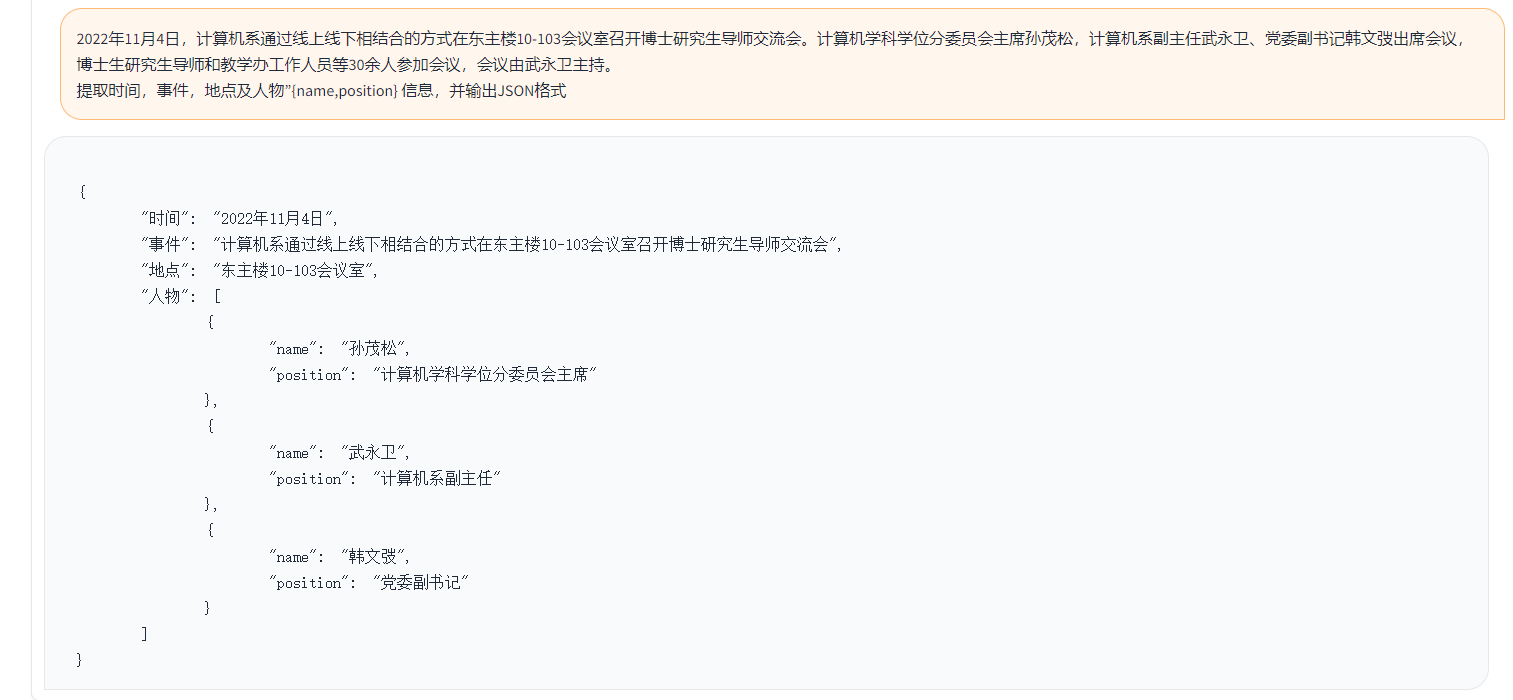
Простая демонстрация показана на рисунке ниже.

Демонстрация здесь относится к реализации в Чатглме.