Toucan LLM
1.0.0

O Toucan é um modelo de linguagem de diálogo de código aberto, principalmente chinês, baseado na arquitetura [Modelo de Linguagem de META (LLAMA)], com 7 bilhões de parâmetros. Combinando a tecnologia de quantização do modelo e a tecnologia esparsa, ela pode ser implantada no lado final para inferência no futuro. O design do logotipo vem do site de design de logotipo gratuito https://app.logo.com/
O conteúdo fornecido por este projeto inclui código de treinamento de ajuste fino, código de inferência baseado em graduação, código de quantização de 4 bits e código de fusão de modelos etc. Os pesos do modelo podem ser baixados no link fornecido e depois combinados para usar. O Toucan-7b que fornecemos é um pouco melhor que o ChatGLM-6b. O modelo quantificado de 4 bits é comparável ao ChatGLM-6b.
O desenvolvimento deste modelo usa conjuntos de dados de código aberto e de código aberto. Este projeto não assume riscos e responsabilidades decorrentes da segurança de dados, riscos de opinião pública causados por modelos e códigos de código aberto, ou os riscos e responsabilidades decorrentes de enganosos, abusos, disseminação ou uso inadequado de qualquer modelo.
As pontuações de avaliação objetiva são baseadas principalmente nesse código -fonte aberto https://github.com/lianjiatech/belle/tree/main/eval
Exemplos são os seguintes:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}No exemplo acima, as respostas anotadas fornecidas nos dados são as seguintes.
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
No exemplo acima, a resposta gerada por Toucan como exemplo:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )No exemplo acima, o resultado da pontuação com o chatgpt
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
De acordo com a lógica de teste acima, testamos quase 1.000 casos de teste e as categorias estão resumidas da seguinte forma. Comparamos os efeitos dos testes de diferentes modelos em diferentes categorias. O efeito do tucan-7b é um pouco melhor que o do ChatGLM-6B, mas ainda é mais fraco que o chatgpt.
| Nome do modelo | Pontuação média | matemática | código | Classificação | extrair | QA aberto | QA fechado | Geração | brainstorming | reescrever | Resumo | Remova a pontuação média de matemática e código | Comentários |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-Inst-Chat-7b | 0,5017 | 0,275 | 0,675 | 0,329 | 0,19 | 0,54 | 0,35 | 0,825 | 0,81 | 0,8 | 0,27 | 0,514 | num_beams = 4, do_sample = false, min_new_tokens = 1, max_new_tokens = 512, |
| ALPACA-7B | 0,4155 | 0,0455 | 0,535 | 0,52 | 0,2915 | 0,1962 | 0,5146 | 0,475 | 0,3584 | 0,8163 | 0,4026 | 0,4468 | |
| ALPACA-7B-PLUS | 0,4894 | 0,1583 | 0,4 | 0,493 | 0,1278 | 0,3524 | 0,4214 | 0,9125 | 0,8571 | 0,8561 | 0,3158 | 0,542 | |
| Chatglm | 0,62 | 0,27 | 0,536 | 0,57 | 0,48 | 0,37 | 0,6 | 0,93 | 0,9 | 0,87 | 0,64 | 0,67 | |
| Toucan-7b | 0,6408 | 0,17 | 0,73 | 0,7 | 0,426 | 0,48 | 0,63 | 0,92 | 0,89 | 0,93 | 0,52 | 0,6886 | |
| TOCAN-7B-4BIT | 0,6225 | 0,1492 | 0,6826 | 0,6862 | 0,4139 | 0,4716 | 0,5711 | 0,9129 | 0,88 | 0.9088 | 0,5487 | 0,6741 | |
| Chatgpt | 0,824 | 0,875 | 0,875 | 0,813 | 0,767 | 0,69 | 0,751 | 0,971 | 0,944 | 0,861 | 0,795 | 0,824 |
Phoenix-Inst-Chat-7b: https://github.com/freedomintelligence/llmzoo
ALPACA-7B/ALPACA-7B-PLUS: https://github.com/ymcui/chinese-llama-alpaca
ChatGlm: https://github.com/thudm/chatglm-6b
Conforme mostrado na figura acima, o Toucan-7b fornecemos resultados um pouco melhores que o ChatGLM-6b. O modelo quantificado de 4 bits é comparável ao ChatGLM-6b.
Você pode criar um ambiente através do CONDA e, em seguida, instalar os pacotes necessários pela PIP. Existem requisitos.txt sob o arquivo de trem para visualizar os pacotes de instalação necessários, Python versão 3.10
CONDA CREATE -N TUCAN Python = 3,10
Em seguida, execute o seguinte comando para instalar, é recomendável instalar a tocha primeiro
pip install -r Train/requisitos.txt
O treinamento usa principalmente dados de código aberto:
ALPACA_GPT4_DATA.JSON
ALPACA_GPT4_DATA_ZH.JSON
BELLE DATOS: BELLE_CN
Entre eles, menos da metade dos dados da Belle pode ser selecionada adequadamente.
O tamanho do vocabulário do modelo de llama original é de 32k, que é treinado principalmente para o inglês, e a capacidade de entender e gerar chineses é limitada. O chinês-llama-alpaca expandiu ainda mais o vocabulário chinês baseado na lhama original e realizou pré-treinamento no corpus chinês. Devido às limitações de pré-treinamento devido a condições de recursos como recursos, continuamos a fazer um trabalho de desenvolvimento correspondente com base no modelo pré-treinado chinês-lama-alpaca.
O ajuste fino do parâmetro completo do modelo + de profundidade, o script iniciado pelo treinamento é treinar/run.sh, e os parâmetros podem ser modificados de acordo com a situação.
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
——Model_Name_or_Path representa o modelo pré-treinado, e o modelo LLAMA está em abraçar o formato da face-Data_Path representa os dados de treinamento-Output_dir representa o registro de treinamento e o caminho salvo pelo modelo
1. Se for um treinamento único, defina nproc_per_node como 1
2. Se o ambiente de corrida não suportar a velocidade profunda, remova -Deepspeed
Este experimento está no NVIDIA GeForce RTX 3090, usando parâmetros de configuração DeepSpeed pode efetivamente evitar problemas de OOM.
python scripts/demo.pyAbrimos pesos delta treinados de código e consideramos licenças que aderem aos modelos de lhama. Você pode usar o seguinte comando para responder aos pesos do modelo original.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ DIFF-CKPT pode ser baixado aqui no OneDrive
Baixe o Baidu NetDisk aqui
A figura abaixo mostra o uso da memória de vídeo medido após várias rodadas de conversas, todas foram testadas na máquina NVIDIA GeForce RTX 3090. O modelo de 4 bits pode efetivamente reduzir o uso da memória.
toucan-16bit
Ocupação inicial 
comprimento do token 1024 num vigas de num = 4; comprimento do token 2048 irá; 
comprimento do token 2048 num feixes = 1; 
toucan-4bit
Ocupação inicial 
Comprimento do token 2048 NUM BEAMS = 4; 
comprimento do token 2048 num feixes = 1; 
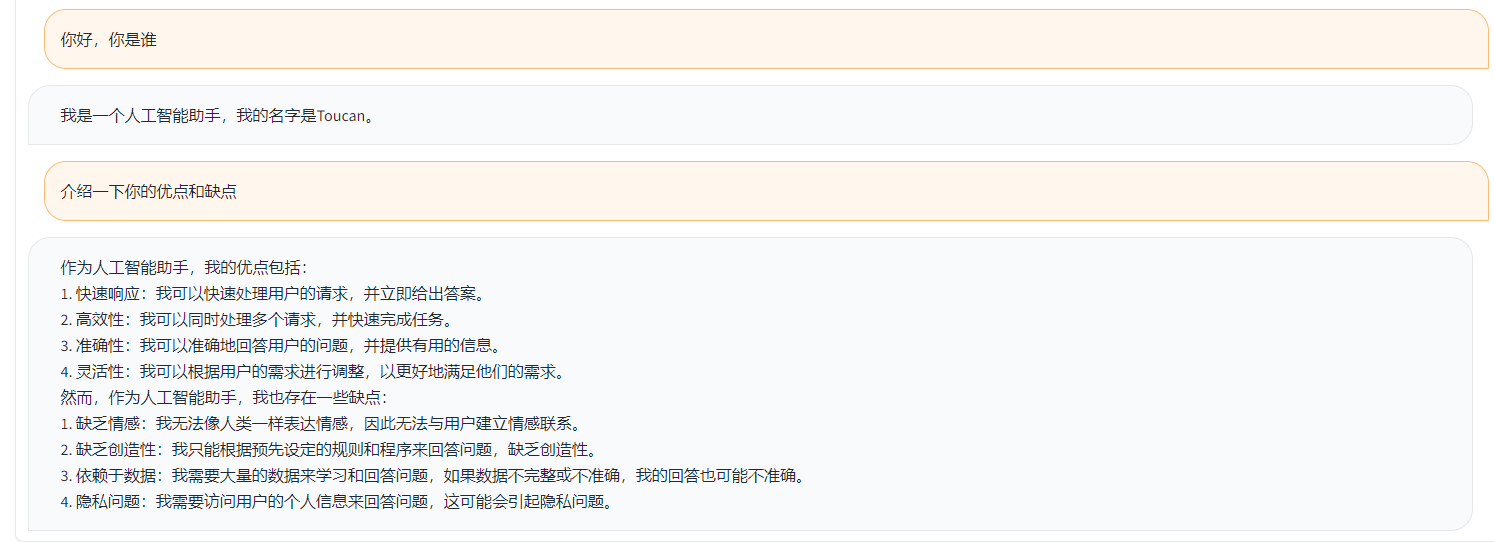
Uma demonstração simples é mostrada na figura abaixo.

A demonstração aqui refere -se à implementação no ChatGLM.